How Diffusion Models Create Stunning AI Images From Pure Noise
Artificial intelligence has changed digital creativity in ways that felt impossible just a few years ago. Today, AI can generate realistic portraits, cinematic landscapes, anime characters, product designs, and even paintings that look hand-crafted by professional artists.
At the center of this revolution are Diffusion Models.
These models power popular AI image generators like OpenAI DALL·E, Stability AI Stable Diffusion, and Google Imagen. What makes them fascinating is that they create detailed images starting from nothing but random noise.
Yes, literally noise.
In this guide, you’ll learn:
- What Diffusion Models are
- How they work step by step
- Why they outperform older AI approaches
- The mathematics behind the process
- How text prompts become images
- Real-world applications
- Simple Python code examples
- Challenges and future improvements
Everything is explained in a simple, beginner-friendly way with practical examples and easy-to-follow explanations.
What Are Diffusion Models?
Diffusion Models are a type of generative AI model designed to create new data, especially images, by gradually transforming random noise into meaningful visual content.
Think of it like sculpting.
An artist starts with a rough block of stone and slowly shapes it into a statue. Similarly, Diffusion Models begin with a chaotic noisy image and gradually refine it until a recognizable image appears.
The process happens in two stages:
- Forward Diffusion Process
Noise is gradually added to training images until they become pure static. - Reverse Diffusion Process
The AI learns how to reverse the noise step-by-step to reconstruct realistic images.
That reverse process is where the magic happens.
Basically, for image generation, the model learns two things:
- How to slowly destroy an image by adding noise
- How to rebuild the image from that noise
During training, the model repeatedly sees images with different noise levels added to them. Over time, it learns how to predict and remove the noise accurately.
Once training is complete, the model can start from pure random static and generate entirely new images.
The name comes from physics: diffusion describes how particles spread from a concentrated point into a uniform distribution — like a drop of ink dispersing in water.
Diffusion models don’t “draw” an image directly. They learn to remove noise, one tiny step at a time, until a clean image emerges from what started as static.
Why Diffusion Models Became So Popular
Before Diffusion Models, GANs (Generative Adversarial Networks) dominated AI image generation. GANs produced impressive results but had several limitations:
- Training instability
- Mode collapse issues
- Difficulty generating highly detailed scenes
- Limited prompt understanding
Diffusion Models solved many of these problems.
Key Advantages of Diffusion Models
Better Image Quality
Diffusion-based systems generate sharper and more realistic images.
Stable Training
They are generally easier to train compared to GANs.
Strong Prompt Understanding
Modern Diffusion Models connect language and vision effectively.
Diverse Outputs
The same prompt can produce many unique results.
Scalable Architecture
They work well with massive datasets and larger neural networks.
Understanding the Core Idea With a Simple Analogy
Imagine placing a photograph into water and adding drops of ink repeatedly.
At first, the image is still visible.
Then it becomes blurry.
Eventually, it turns into complete chaos.
Now imagine training an AI to reverse that process perfectly.
The AI learns:
- how much noise was added
- where details originally existed
- how edges, textures, and shapes should look
This is essentially how Diffusion Models work.
The Two Main Processes in Diffusion Models
1. Forward Diffusion Process
The forward process destroys the image slowly.
Mathematically, noise is added over many time steps.
The equation looks like this:

At every step:
- a small amount of noise is added
- the image becomes less recognizable
- eventually only random static remains
After thousands of steps, the original image disappears completely.
2. Reverse Diffusion Process
This is where the AI generates images.
The model learns how to remove noise gradually.
Starting from random noise:
- it predicts what the cleaner image should look like
- removes a little noise
- repeats the process many times
Eventually, a realistic image appears.
This reverse process is powered by deep neural networks trained on millions of images.
How Diffusion Models Learn During Training
Training teaches the model to predict noise accurately.
The process looks like this:
- Take a real image
- Add noise at different levels
- Ask the AI to predict the added noise
- Compare prediction with actual noise
- Improve the model through optimization
Over time, the AI becomes extremely good at reconstructing images from noisy inputs.
The Role of Neural Networks : U-Net
Most modern Diffusion Models use a neural network called a U-Net.
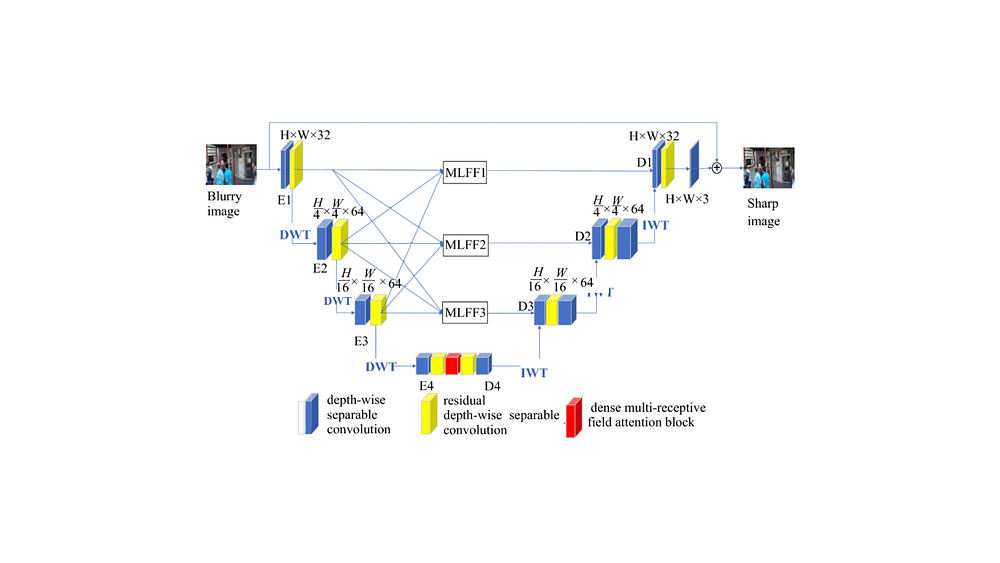
The U-Net architecture originally developed for medical image segmentation. The name comes from its shape: an encoder that compresses the input to a lower-resolution representation, followed by a decoder that brings it back to full resolution, with skip connections tying together the corresponding encoder and decoder layers at each scale.
The U-Net architecture helps the model:
- understand image structures
- preserve details
- recover textures
- maintain object consistency
It processes images at multiple resolutions simultaneously.
This allows the model to generate:
- smooth faces
- detailed hair
- realistic lighting
- accurate shadows
- complex environments
How Text Prompts Become Images
One of the most impressive features of modern Diffusion Models is text-to-image generation.
For example:
“A futuristic cyberpunk city at night with neon rain.”
The AI converts that sentence into visual understanding.
Step-by-Step Prompt Processing
Step 1: Text Encoding
A language model converts the prompt into numerical vectors.
Step 2: Semantic Understanding
The AI learns relationships between words and visual patterns.
For example:
- “cat” relates to fur, whiskers, ears
- “sunset” relates to warm colors
- “cyberpunk” relates to neon lighting and futuristic architecture
Step 3: Guided Image Generation
The diffusion process uses those text embeddings to guide image creation.
This is called conditioning.

What Is Latent Diffusion?
Modern systems like Stable Diffusion use Latent Diffusion Models (LDMs).
Instead of working directly on large images, the model compresses images into a smaller hidden representation called latent space.
Benefits include:
- faster training
- lower memory usage
- improved efficiency
- reduced computational cost
The process becomes:
- Compress image into latent space
- Perform diffusion there
- Decode back into full image
This innovation made AI image generation practical for consumer GPUs.
Simple Python Example of Diffusion Models
Let’s look at a simple Python example using the Hugging Face Diffusers library.
Install Required Libraries
pip install diffusers transformers accelerate torchBasic Text-to-Image Generation Code
from diffusers import StableDiffusionPipeline
import torch
# Load model
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
# Text prompt
prompt = "A majestic dragon flying above snowy mountains"
# Generate image
image = pipe(prompt).images[0]
# Save image
image.save("dragon.png")
print("Image generated successfully!")Explanation
Import Libraries
from diffusers import StableDiffusionPipeline
import torchdiffusersprovides pretrained Diffusion Modelstorchhandles deep learning operations
Load the Model
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16
)This downloads a pretrained Stable Diffusion model.
The model already understands:
- objects
- colors
- lighting
- styles
- compositions
It has been trained on huge image-text datasets.
Move Model to GPU
pipe = pipe.to("cuda")This uses the GPU for faster image generation.
Without GPU acceleration, generation becomes much slower.
Define the Prompt
prompt = "A majestic dragon flying above snowy mountains"The text prompt guides the diffusion process.
More descriptive prompts usually produce better outputs.
Generate the Image
image = pipe(prompt).images[0]The model:
- starts with random noise
- removes noise gradually
- follows prompt guidance
- creates the final image
Save the Result
image.save("dragon.png")The generated image is stored locally.

What Happens Internally During Image Generation?
Behind the scenes, several advanced operations occur.
Noise Prediction
The model predicts which parts are noise.
Attention Mechanisms
Attention layers help connect text concepts to image regions.
For example:
- “dragon” influences body structure
- “snowy mountains” affects the background
- “majestic” changes pose and atmosphere
Iterative Refinement
The image improves over many denoising steps.
Typical generation may use:
- 20 steps
- 50 steps
- 100+ steps
More steps usually improve quality but increase generation time.
Sampling Methods in Diffusion Models
Different samplers control how noise removal happens.
Popular samplers include:
- DDPM
- DDIM
- Euler
- LMS
- DPM++
Each sampler balances:
- speed
- realism
- consistency
Some generate images faster, while others improve detail quality.
Classifier-Free Guidance Explained
Classifier-Free Guidance (CFG) controls prompt adherence.
Higher CFG values:
- follow prompts more strictly
- increase visual intensity
- may reduce realism
Lower CFG values:
- allow more creativity
- produce softer interpretations
A common CFG range is:
7 to 12
Very high values can sometimes create oversaturated or distorted images.
Real-World Applications of Diffusion Models
Diffusion Models are transforming multiple industries.
Digital Art
Artists create concept art, illustrations, and fantasy scenes quickly.
Gaming
Studios generate textures, characters, and environments faster.
Marketing
Brands produce AI-generated advertisements and social media graphics.
Film Production
Filmmakers use AI for storyboarding and visual ideation.
Fashion Design
Designers experiment with clothing concepts instantly.
Medical Imaging
Researchers use diffusion techniques for image reconstruction and enhancement.
Architecture
Architects generate building concepts and interior visualizations.
Challenges and Limitations of Diffusion Models
Despite their power, Diffusion Models still face challenges.
High Computational Cost
Training requires enormous GPU resources.
Slow Generation Speed
Image creation involves many denoising iterations.
Bias in Training Data
Models may reproduce unwanted societal biases.
Copyright Concerns
Training datasets can contain copyrighted material.
Prompt Sensitivity
Small wording changes may produce very different outputs.
Ethical Considerations
AI-generated imagery raises important ethical questions.
These include:
- misinformation
- deepfakes
- artist compensation
- synthetic media transparency
Responsible AI development requires:
- transparency
- safety guardrails
- dataset accountability
- watermarking systems
Leading AI organizations continue researching safer generative systems.
Future of Diffusion Models
The future looks incredibly promising.
Researchers are improving:
- generation speed
- video generation
- 3D object creation
- real-time rendering
- controllable outputs
- multimodal AI systems
We are already seeing:
- AI-generated movies
- real-time editing tools
- interactive creative assistants
- AI-powered design workflows
Diffusion Models will likely become a core part of digital creativity across industries.
Frequently Asked Questions
Are Diffusion Models better than GANs?
In many cases, yes.
Diffusion Models generally produce:
- more stable results
- better detail quality
- stronger prompt alignment
However, GANs can still be faster for some tasks.
Why do Diffusion Models start with noise?
Starting from noise allows the model to learn a flexible generative process capable of producing highly diverse outputs.
What is Stable Diffusion?
Stable Diffusion is an open-source latent diffusion model for generating images from text prompts.
Can Diffusion Models generate videos?
Yes.
Modern diffusion-based systems now support:
- video generation
- animation
- frame interpolation
- motion synthesis
Do Diffusion Models understand language?
Not directly like humans.
They learn statistical relationships between text and images using massive datasets.
Conclusion
Diffusion Models have fundamentally changed how machines create visual content.
What once required expert artists and expensive software can now be generated from a simple text prompt in seconds.
The idea is surprisingly elegant:
- destroy images with noise
- teach AI to reverse the destruction
- generate entirely new visuals from randomness
That simple concept powers some of the most advanced AI systems in the world today.
As computing power improves and research advances, Diffusion Models will continue reshaping art, design, entertainment, and digital creativity for years to come.