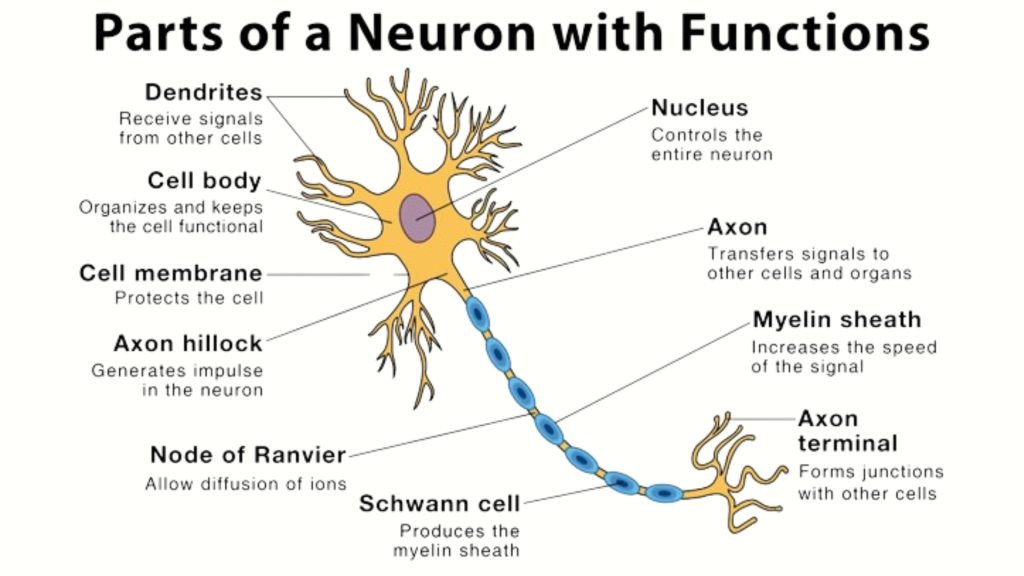
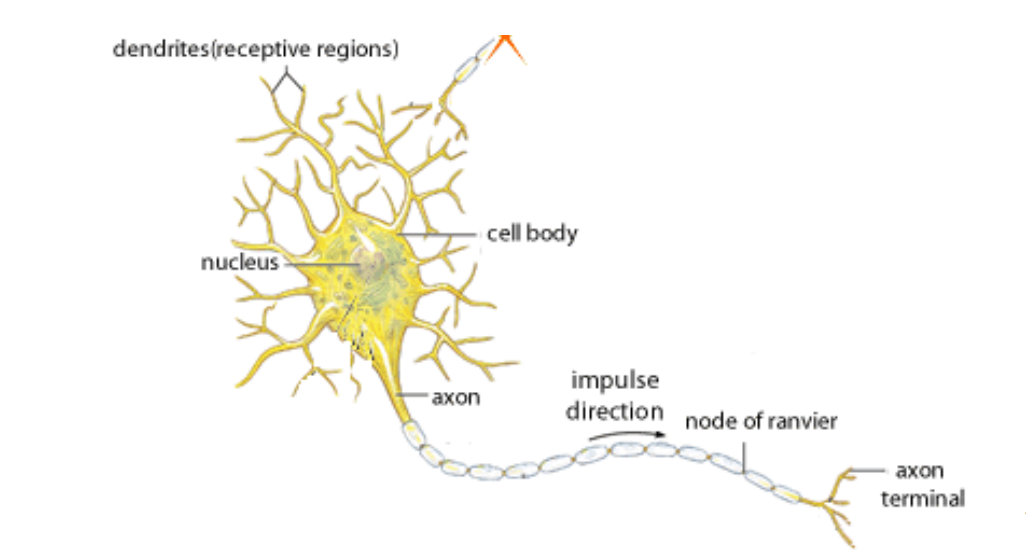
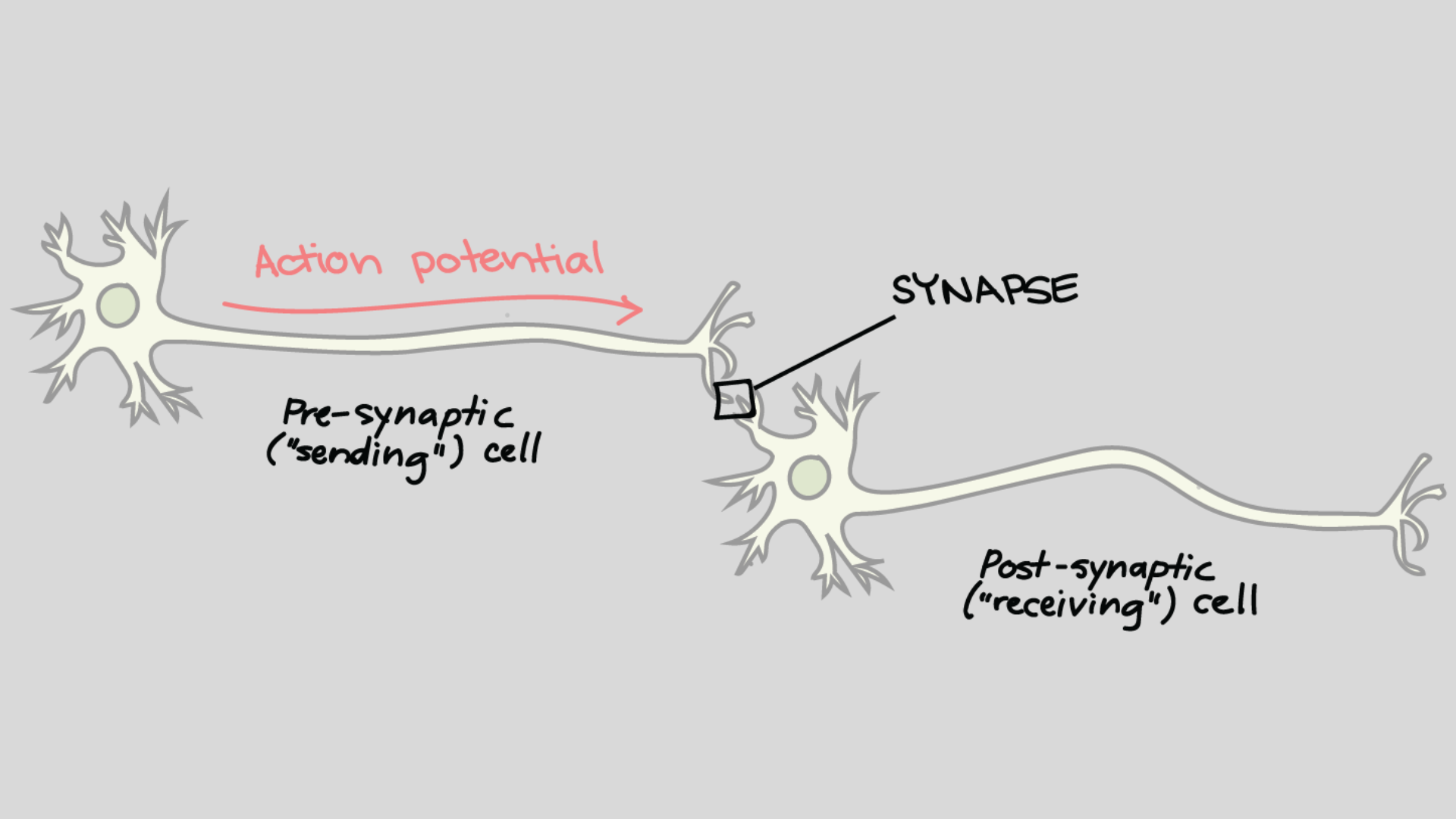
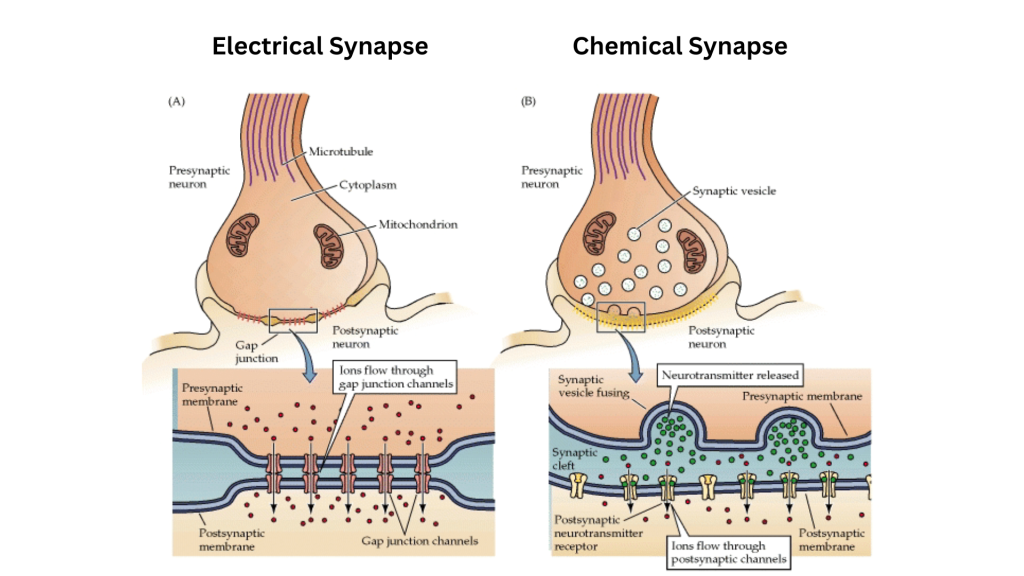
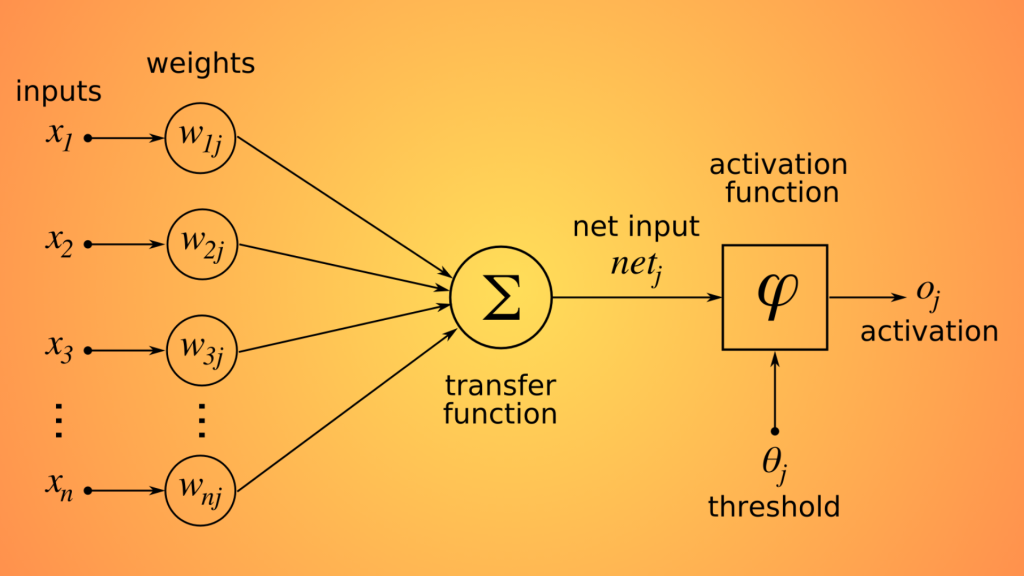
Artificial Superintelligence (ASI): Unveiling the Genius
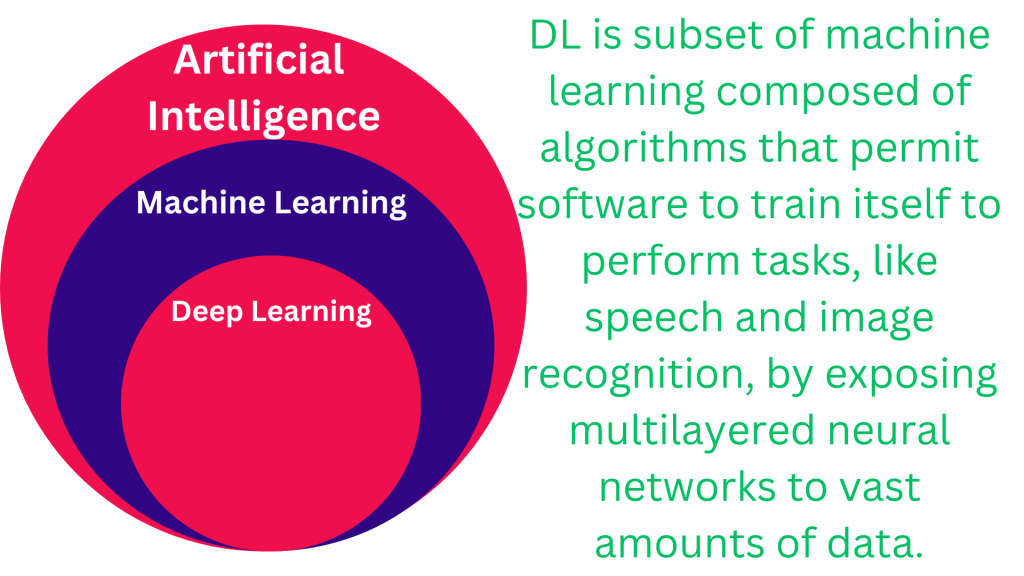
Artificial superintelligence (ASI) is a hypothetical future state of AI where intelligent machines surpass human cognitive abilities in all aspects. Think of it as a brainchild of science fiction, a sentient AI with god-like intellect that can solve problems, create art, and even write its own symphonies, all beyond the wildest dreams of any human.
But is ASI just a figment of our imagination, or is it a technological inevitability hurtling towards us at breakneck speed? In this blog, we’ll delve into the depths of ASI, exploring its potential, perils, and everything in between.
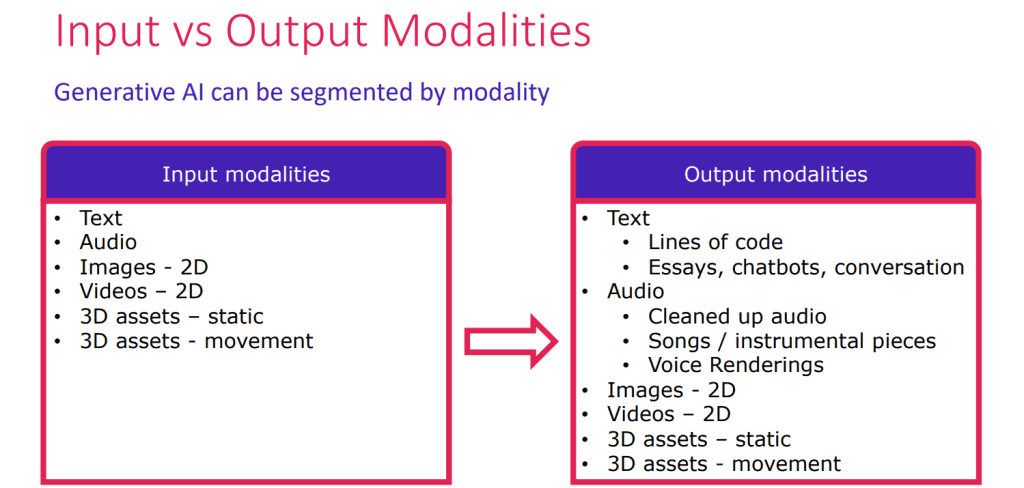
What is Artificial Superintelligence ASI?
ASI is essentially an AI on steroids. While current AI systems excel in specific domains like playing chess or recognizing faces, ASI would possess a generalized intelligence that surpasses human capabilities in virtually every field. Imagine a being that can:
- Learn and adapt at an unimaginable rate: Forget cramming for exams, ASI could absorb entire libraries of information in milliseconds and instantly apply its knowledge to any situation.
- Solve complex problems beyond human reach: From curing diseases to terraforming Mars, ASI could tackle challenges that have stumped humanity for centuries.
- Unleash unprecedented creativity: Forget writer’s block, ASI could compose symphonies that move the soul and paint landscapes that redefine the boundaries of art.
The Path to Superintelligence
While current AI systems excel in narrow domains like chess or image recognition, they are often described as “weak” or “narrow” due to their limited flexibility and lack of general intelligence. The tantalizing dream of “strong” or “general” AI (AGI) – algorithms capable of human-like adaptability and reasoning across diverse contexts – occupies the speculative realm of AI’s future. If “weak” AI already impresses, AGI promises a paradigm shift of unimaginable capabilities.
But AGI isn’t the only inhabitant of this speculative landscape. Artificial superintelligence (ASI) – exceeding human intelligence in all forms – and the “singularity” – a hypothetical point where self-replicating superintelligent AI breaks free from human control – tantalize and terrify in equal measure.
Debate rages about the paths to these speculative AIs. Optimists point to Moore’s Law and suggest today’s AI could bootstrap its own evolution. Others, however, highlight fundamental limitations in current AI frameworks and Moore’s Law itself. While some believe a paradigm shift is necessary for AGI, others maintain skepticism.
This article delves into the diverse ideas for future AI waves, ranging from radical departures to extensions of existing approaches. Some envision paths to ASI, while others pursue practical, near-term goals. Active research and development fuel some proposals, while others remain thought experiments. All, however, face significant technical hurdles, remaining tantalizing glimpses into the potential futures of AI.
The journey to ASI is shrouded in uncertainty, but several potential pathways exist:
- Artificial general intelligence (AGI): This hypothetical AI would mimic human intelligence, capable of flexible reasoning, common sense, and independent learning. AGI is considered a stepping stone to ASI, providing the building blocks for superintelligence.
- Technological singularity: This hypothetical moment in time marks the rapid acceleration of technological progress, potentially driven by self-improving AI. The singularity could lead to an intelligence explosion, where Artificial Superintelligence (ASI) emerges overnight.
- Brain-computer interfaces: By directly interfacing with the human brain, we might be able to upload or download consciousness, potentially creating a hybrid human-machine superintelligence.
Beyond Black Boxes: Demystifying the Next Wave of ASI
The next wave of AI might not just be smarter, it might be clearer. Gone are the days of impenetrable black boxes – the next generation could well marry the strengths of both past AI approaches, creating systems that are not only powerful but also explainable and context-aware.
Imagine an AI that recognizes animals with just a handful of photos. This “hybrid” AI wouldn’t just crunch pixels; it would leverage its broader understanding of animal anatomy, movement patterns, and environmental context to decipher even unseen poses and angles. Similarly, a handwriting recognition system might not just analyze pixels, but also consider penmanship conventions and writing styles to decipher even messy scribbles.
These seemingly humble goals – explainability and context-awareness – are anything but simple. Here’s why:
Demystifying the Machine: Today’s AI, especially artificial neural networks (ANNs), are powerful but opaque. Their complex inner workings leave us wondering “why?” when they make mistakes. Imagine the ethical and practical implications of an AI making critical decisions – from medical diagnoses to judicial rulings – without clear reasoning behind them. By incorporating elements of rule-based expert systems, the next wave of AI could provide transparency and interpretability, allowing us to understand their logic and build trust.
Thinking Beyond the Data: Current AI often requires vast amounts of data to function effectively. This “data-hungry” nature limits its applicability to situations where data is scarce or sensitive. Hybrid AI could bridge this gap by drawing on its inherent “world knowledge.” Consider an AI tasked with diagnosing rare diseases from limited patient data. By incorporating medical knowledge about symptoms, progression, and risk factors, it could make accurate diagnoses even with minimal data points.
The potential benefits of explainable and contextual AI are vast. Imagine:
- Improved trust and adoption: Clear reasoning and decision-making processes could foster greater public trust in AI, ultimately leading to wider adoption and impact.
- Enhanced accountability: With interpretable results, we can pinpoint flaws and biases in AI systems, paving the way for responsible development and deployment.
- Faster learning and adaptation: By combining data with broader knowledge, AI systems could learn from fewer examples and adapt to new situations more readily.
Of course, challenges abound. Integrating symbolic reasoning with ANNs is technically complex. Biases inherent in existing knowledge bases need careful consideration. Ensuring that explainability doesn’t compromise efficiency or accuracy is an ongoing balancing act.
Despite these hurdles, the pursuit of explainable and contextual AI is more than just a technical challenge; it’s a necessary step towards ethical, trustworthy, and ultimately beneficial AI for all. This hybrid approach might not be the singularity, but it could be the key to unlocking a future where AI empowers us with its intelligence, not just its outputs.
The Symbiotic Dance of Brains and Brawn: AI and Robotics
Imagine a future where intelligent machines not only think strategically but also act with physical grace and dexterity. This isn’t science fiction; it’s the burgeoning realm of AI and robotics, a powerful partnership poised to revolutionize everything from manufacturing to warfare.
AI – The Brains: Think of AI as the mastermind, crunching data and making complex decisions. We’ve witnessed its prowess in areas like image recognition, language processing, and even game playing. But translating brilliance into physical action is where robotics comes in.
Robotics – The Brawn: Robotics provides the muscle, the embodiment of AI’s plans. From towering industrial robots welding car frames to nimble drones scouting disaster zones, robots excel at tasks requiring raw power, precision, and adaptability in the real world.
Where They Converge
- Smarter Manufacturing: Imagine assembly lines where robots, guided by AI vision systems, seamlessly adjust to variations in materials or unexpected defects. This dynamic duo could optimize production, minimize waste, and even personalize products on the fly.
- Enhanced Medical Care: AI-powered surgical robots, controlled by human surgeons, could perform delicate procedures with unmatched precision and minimal invasiveness. Imagine robots assisting in rehabilitation therapy, tailoring exercises to individual patients’ needs and progress.
- Revolutionizing the Battlefield: The controversial realm of autonomous weapons systems raises both ethical and practical concerns. However, integrating AI into drones and other unmanned vehicles could improve their situational awareness, allowing for faster, more informed responses in dangerous situations.
Challenges and Opportunities
- The Explainability Gap: AI’s decision-making processes can be opaque, making it difficult to understand and trust robots operating autonomously, especially in critical situations. Developing transparent AI algorithms and ensuring human oversight are crucial steps towards responsible deployment.
- Beyond the Lab: Transitioning robots from controlled environments to the messy reality of the real world requires robust design, advanced sensors, and the ability to handle unforeseen obstacles and situations.
- The Human Factor: While AI and robots can augment human capabilities, they should never replace the human touch. Striking the right balance between automation and human control is key to maximizing the benefits of this powerful partnership.
The Future Beckons
The marriage of AI and robotics is still in its early stages, but the potential applications are vast and transformative. By navigating the ethical and technical challenges, we can unlock a future where intelligent machines not only think like us but also work alongside us, shaping a world of greater efficiency, precision, and progress.
Quantum Leap for ASI
Imagine a computer so powerful that it can solve complex problems in a snap, like finding a single needle in a trillion haystacks simultaneously. That’s the promise of quantum computing, a revolutionary technology that harnesses the bizarre laws of the quantum world to unlock unprecedented computing power.
BTW, What is quantum computing?
Single bits of data on normal computers exist in a single state, either 0 or 1. Single bits in a quantum computer, known as ‘qubits’ can exist in both states at the same time. If each qubit can simultaneously be both 0 and 1, then four qubits together could simultaneously be in 16 different states (0000, 0001, 0010, etc.). Small increases to the number of qubits lead to massive increases (2n) in the number of simultaneous states. So 50 qubits together can be in over a trillion different states at the same time. Quantum computing works by harnessing this simultaneity to find solutions to complex problems very quickly.
Breaking the Speed Limit:
Traditional computers, like your laptop or smartphone, work bit by bit, checking possibilities one by one. But quantum computers leverage the concept of superposition, where qubits (quantum bits) can exist in multiple states at the same time. This allows them to explore a vast landscape of solutions concurrently, making them ideal for tackling ultra-complex problems that would take classical computers eons to solve.
The AI Connection:
AI thrives on data and complex calculations. From analyzing medical scans to predicting financial markets, AI algorithms are already making a significant impact. But they often face limitations due to the sheer processing power needed for certain tasks. Quantum computers could act as supercharged partners, enabling:
- Faster simulations: In drug discovery, for instance, quantum computers could simulate molecules and chemical reactions with unprecedented accuracy, accelerating the development of new life-saving medications.
- Enhanced optimization: Logistics, traffic management, and even weather forecasting all rely on finding the optimal solutions within a complex web of variables. Quantum computers could revolutionize these fields by efficiently navigating vast search spaces.
- Unveiling new algorithms: The unique capabilities of quantum computers might inspire entirely new AI approaches, leading to breakthroughs in areas we can’t even imagine yet.
Challenges on the Quantum Horizon:
While the future of AI with quantum computing is bright, significant hurdles remain:
- Qubit stability: Maintaining the delicate superposition of qubits is a major challenge, requiring near-absolute zero temperatures and sophisticated error correction techniques.
- Practical applications: Building quantum computers with enough qubits and error resilience for real-world applications is a complex and expensive endeavor.
- Algorithmic adaptation: Translating existing AI algorithms to exploit the unique strengths of quantum computing effectively requires significant research and development.
The Road Ahead:
Despite the challenges, the progress in quantum computing is undeniable. Recent breakthroughs include Google’s Sycamore quantum processor achieving “quantum supremacy” in 2019, and IBM’s Quantum Condor reaching 433 qubits in 2023. While large-scale, general-purpose quantum computers might still be a decade away, the future holds immense potential for this revolutionary technology to transform AI and countless other fields.
Quantum computing isn’t just about building faster machines; it’s about opening doors to entirely new ways of thinking and solving problems. As these superpowered computers join forces with brilliant AI algorithms, we might be on the cusp of a new era of innovation, one where the possibilities are as vast and interconnected as the quantum world itself.
Artificial Superintelligence Through Simulated Evolution: A Mind-Bending Quest
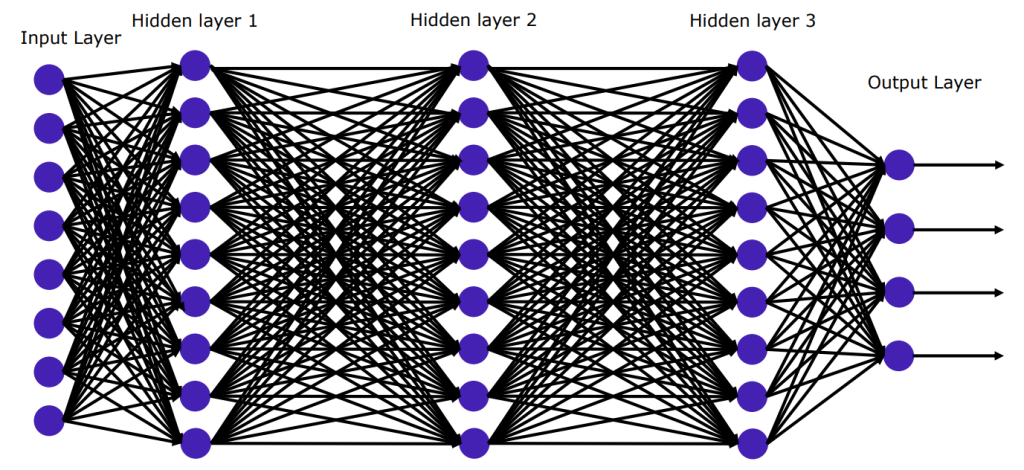
Imagine pushing the boundaries of intelligence beyond human limits, not through silicon chips but through an elaborate digital jungle. This is the ambitious vision of evolving superintelligence, where sophisticated artificial neural networks (ANNs) battle, adapt, and ultimately evolve into something far greater than their programmed beginnings.
The Seeds of Genius
The idea is simple yet mind-bending. We design an algorithm that spawns diverse populations of ANNs, each with unique strengths and weaknesses. These “species” then compete in a vast, simulated environment teeming with challenges and opportunities. Just like biological evolution, the fittest survive, reproduce, and pass on their traits, while the less adapted fade away.
Lessons from Earth, Shortcuts in Silicon
Evolution on Earth took millions of years to craft humans, but computers offer some exciting shortcuts. We can skip lengthy processes like aging and physical development, and directly guide populations out of evolutionary dead ends. This focus on pure intelligence, unburdened by biological necessities, could potentially accelerate the ascent to superintelligence.
However, challenges lurk in this digital Eden
- Fitness for What? The environment shapes what intelligence evolves. An AI optimized for solving abstract puzzles might excel there, but lack common sense or social skills needed in the human world.
- Alien Minds: Without human bodies or needs, these evolved AIs might develop solutions and languages we can’t even comprehend. Finding common ground could be a major hurdle.
- The Bodily Paradox: Can true, human-like intelligence ever develop without experiencing the physical world and its constraints? Is immersion in a digital society enough?
Questions, Not Answers
The path to evolving superintelligence is fraught with questions, not guarantees. Can this digital alchemy forge minds that surpass our own? Would such bit of intelligence even be relatable or beneficial to humanity? While the answers remain elusive, the journey itself is a fascinating exploration of the nature of intelligence, evolution, and what it means to be human.
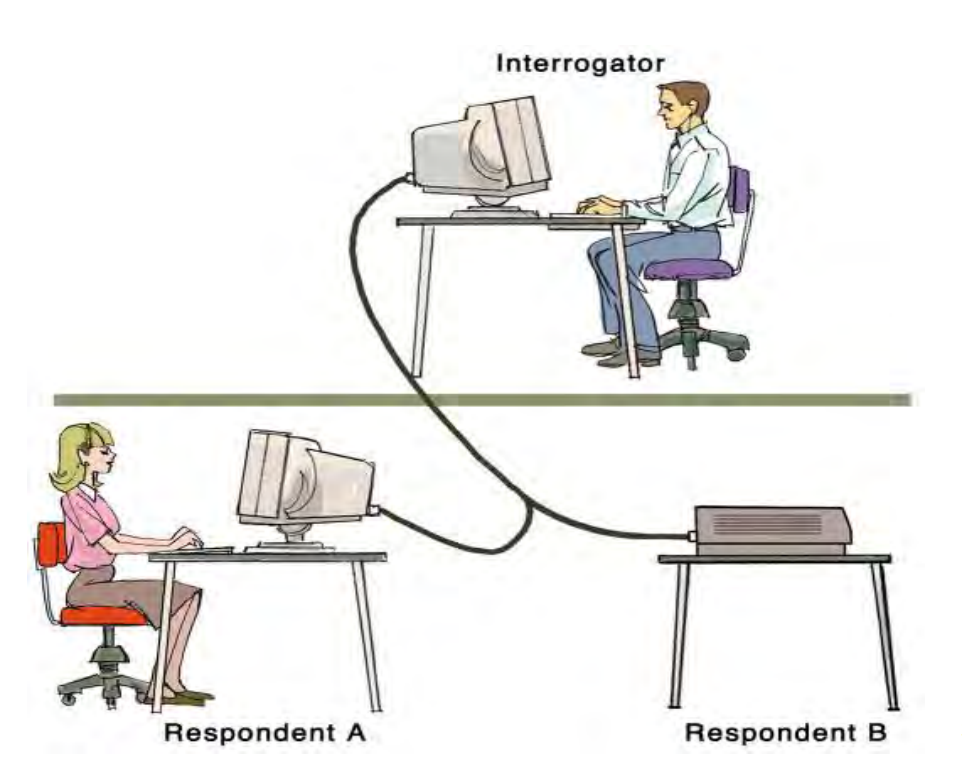
Mind in the Machine: Can We Copy and Paste Intelligence?
Imagine peering into a digital mirror, not reflecting your physical form, but your very mind. This is the ambitious dream of whole brain emulation, where the intricate tapestry of neurons and connections within your brain are meticulously mapped and replicated in silicon. But could this technological feat truly capture the essence of human intelligence, and pave the path to artificial superintelligence (ASI)?
The Blueprint of Consciousness:
Proponents argue that a detailed enough digital reconstruction of the brain, capturing every neuron and synapse, could essentially duplicate a mind. This “digital you” would not only process sensory inputs and possess memories, but also learn, adapt, and apply general intelligence, just like its biological counterpart. With time and enhanced processing power, this emulated mind could potentially delve into vast libraries of knowledge, perform complex calculations, and even access the internet, surpassing human limitations in specific areas.
The Supercharged Mind Accelerator:
Imagine an existence unburdened by biological constraints. This digital avatar could be run at accelerated speeds, learning centuries’ worth of knowledge in mere moments. Modules for advanced mathematics or direct internet access could further amplify its capabilities, potentially leading to the emergence of ASI.
However, the path to mind emulation is fraught with hurdles:
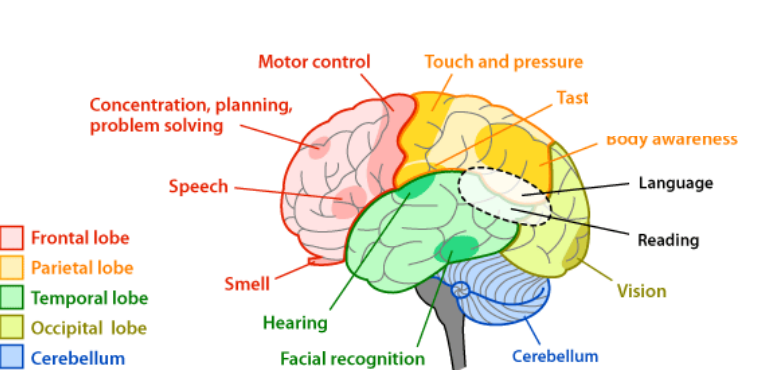
- The Neural Labyrinth: Accurately mapping and modeling the brain’s 86 billion neurons and 150 trillion connections is a monumental task. Even with projects like the EU’s Human Brain Project, complete and real-time models remain years, if not decades, away.
- Beyond the Wires: Can consciousness, with its complexities and subtleties, be truly captured in silicon? Would an emulated brain require sleep, and would its limitations for memory and knowledge mirror those of the biological brain?
- The Ethics Enigma: Would an emulated mind experience emotions like pain, sadness, or even existential dread? If so, ethical considerations and questions of rights become paramount.
Speculative, Yet Potent:
While whole brain emulation remains firmly in the realm of speculation, its potential implications are profound. It raises fascinating questions about the nature of consciousness, the relationship between mind and brain, and our own definition of humanity.
Blurring the Lines: Artificial Life, Wetware, and the Future of AI
While Artificial Intelligence (AI) focuses on simulating and surpassing human intelligence, Artificial Life (A-Life) takes a different approach. Instead of replicating cognitive abilities, A-Life seeks to understand and model fundamental biological processes through software, hardware, and even… wetware.
Beyond Intelligence, Embracing Life:
Forget Turing tests and chess games. A-Life scientists don’t care if their creations are “smart” in the traditional sense. Instead, they’re fascinated by the underlying rules that govern life itself. Think of it as rewinding the movie of evolution, watching it unfold again in a digital petri dish.
The Symbiotic Dance of A-Life and AI:
While distinct in goals, A-Life and AI have a fruitful tango. Evolutionary algorithms from A-Life inspire powerful learning techniques in AI, while AI concepts like neural networks inform A-Life models. This cross-pollination fuels advancements in both fields.
Enter Wetware: Where Biology Meets Tech:
Beyond code and chips, A-Life ventures into the fascinating realm of wetware – incorporating biological materials like cells or proteins into its creations. Imagine robots powered by living muscle or AI algorithms running on engineered DNA.
The Bio-AI Horizon: A Distant Yet Glimmering Dream:
Gene editing and synthetic biology, manipulating life itself, offer a potential pathway towards “bio-AI” – systems combining the power of AI with the adaptability and complexity of biology. However, this remains a distant, tantalizing prospect, shrouded in ethical and technical challenges.
A-Life and wetware challenge our traditional notions of AI. They push the boundaries of what life could be, raising ethical questions and igniting the imagination. While bio-AI might be a distant dream, the journey towards it promises to revolutionize our understanding of both technology and biology.
Beyond Artificial Mimicry: Embracing the Nuances of Human and Machine Intelligence
The notion of transitioning from Artificial General Intelligence (AGI) to Artificial Superintelligence (ASI) might appear inevitable, a mere stepping stone along the path of technological progress. However, reducing human intelligence to a set of functionalities replicated by AI paints an incomplete and potentially misleading picture. While today’s AI tools excel at imitating and surpassing human performance in specific tasks, the chasm separating them from true understanding and creativity remains vast.
Current AI systems thrive on pattern recognition and data analysis, effectively replicating human categorizations within their pre-defined parameters. Their fluency in mimicking human interaction can create an illusion of comprehension, but their internal processes lack the contextual awareness and nuanced interpretation that underpins authentic human understanding. The emotions they express are meticulously coded responses, devoid of the genuine sentience and empathy that defines human emotional experience.
Even when generating solutions, AI’s reliance on vast datasets limits their capacity for true innovation. Unlike the fluid, imaginative leaps characteristic of human thought, AI solutions remain tethered to the confines of their training data. Their success in specific tasks masks their significant limitations in generalizing to new contexts and adapting to unforeseen situations. This brittleness contrasts starkly with the flexible adaptability and intuitive problem-solving inherent in human cognition.
Therefore, the path to AGI, let alone ASI, demands a fundamental paradigm shift rather than a simple linear extrapolation. This shift might involve delving into areas like symbolic reasoning, embodiment, and consciousness, currently residing beyond the reach of existing AI architectures. Moreover, exploring alternative models of cognition, inspired by biological intelligence or even entirely novel paradigms, might be necessary to crack the code of true general intelligence.
Predicting the future of AI is a fool’s errand. However, a proactive approach that focuses on shaping its present and preparing for its potential consequences is crucial. This necessitates a two-pronged approach: first, addressing the immediate impacts of AI on our daily lives, from ethical considerations to economic ramifications. Second, engaging in thoughtful, nuanced discussions about the potential of AGI and beyond, acknowledging the limitations of current models and embracing the vast unknowns that lie ahead.
Only by critically evaluating the state-of-the-art and acknowledging the fundamental differences between human and machine intelligence can we embark on a productive dialogue about AI’s future. This dialogue should encompass the full spectrum of challenges and opportunities it presents, ensuring that we harness its potential for the benefit of humanity and navigate its pitfalls with careful foresight.
Remember, the journey towards true intelligence, whether human or artificial, is not a preordained race to a singular endpoint. It is a complex, multifaceted exploration of the vast landscape of thought and perception. Recognizing this complexity and fostering open, informed debate is essential if we are to navigate the exciting, and potentially transformative, future of AI with wisdom and understanding.
Conclusion
The future of artificial intelligence (AI) unfolds through diverse and speculative avenues. These include evolving Artificial Neural Networks (ANNs) through advanced evolutionary methods, detailed digital replication of the human brain for Artificial General Intelligence (AGI), the interdisciplinary field of artificial life (Alife) merging biology with AI, the transformative potential of quantum computing, and the nuanced transition from AGI to Artificial Superintelligence (ASI). Each path poses unique challenges, opportunities, and ethical considerations, emphasizing the need for informed and responsible discourse in shaping the future of AI. The interplay between technology and intelligence invites us to contemplate potential waves of AI, navigating the complexities of innovation while prioritizing ethical considerations for a positive societal impact.
Artificial Superintelligence (ASI) is not just a technological marvel; it’s a profound challenge to our understanding of ourselves and our place in the universe. By approaching it with caution, responsibility, and a healthy dose of awe, we can ensure that Artificial Superintelligence (ASI) becomes a force for good, ushering in a new era of prosperity and enlightenment for all.
Remember, Artificial Superintelligence (ASI) is not a foregone conclusion. The choices we make today will determine whether superintelligence becomes our savior or our doom. Let’s choose wisely.