

How to Create a Linked List in Kotlin: Easy Step-by-Step Tutorial
If you’re diving into the world of Kotlin and exploring data structures, you’ve probably come across linked lists. While arrays and lists are common in Kotlin development, understanding linked lists can open up new levels of flexibility in your coding journey. In this guide, we’ll unravel what linked lists are, why you might need them, and most importantly, how to create and use linked lists in Kotlin.
What is a Linked List?
A Linked List is a data structure consisting of a sequence of elements, called nodes.

Each node has two components:
- Data: The value we want to store.
- Next: A reference to the next node in the sequence.
Unlike arrays, Linked Lists are dynamic in size, offering efficient insertions and deletions at any position in the list.

In a linked list, each node stores a value and points to the next node in the chain. The last node in the sequence points to “null,” indicating the end of the list.
Linked lists have several advantages over arrays or ArrayLists in Kotlin:
- Quick insertions and removals at the front of the list.
- Consistent performance for operations, especially for inserting or removing elements anywhere in the list.
Types of Linked Lists
- Singly Linked List — Each node points to the next node in the sequence (we’ll focus on this one).
- Doubly Linked List — Each node has a reference to both the next and the previous node.
- Circular Linked List — The last node points back to the first node, forming a loop.
Building a Singly Linked List in Kotlin
Kotlin doesn’t offer a built-in linked list class like Java does. But no worries! We’re going to create our own custom Singly Linked List step-by-step. Let’s create a linked list from scratch! We’ll start by defining the Node class and then build a LinkedList class to manage the nodes.
Defining the Node Class
Each node needs to store data and a reference to the next node. Here’s our Node class:
// We define a node of the linked list as a data class, where it holds a value and a reference to the next node.
data class Node<T>(var value: T, var next: Node<T>? = null) {
override fun toString(): String {
return if (next != null) "$value -> ${next.toString()}" else "$value"
}
}
fun main() {
val node1 = Node(value = 1)
val node2 = Node(value = 2)
val node3 = Node(value = 3)
node1.next = node2
node2.next = node3 //here node3 points to null at last, as per our code we only print its value
println(node1)
}
//OUTPUT
1 -> 2 -> 3Here, we defined a generic Node class for a linked list in Kotlin. Each Node holds a value of any type (T) and a reference to the next Node, which can be null. The toString() method provides a custom string representation for the node, recursively displaying the value of the node followed by the values of subsequent nodes, separated by ->. If the node is the last in the list, it simply shows its value.
Have you observed how we constructed the list above? We essentially created a chain of nodes by linking their ‘next’ references. However, building lists in this manner becomes impractical as the list grows larger. To address this, we can use a LinkedList, which simplifies managing the nodes and makes the list easier to work with. Let’s explore how we can implement this in Kotlin.
Creating the LinkedList Class
Let’s create our LinkedList class and add core functionalities like adding nodes and displaying the list.
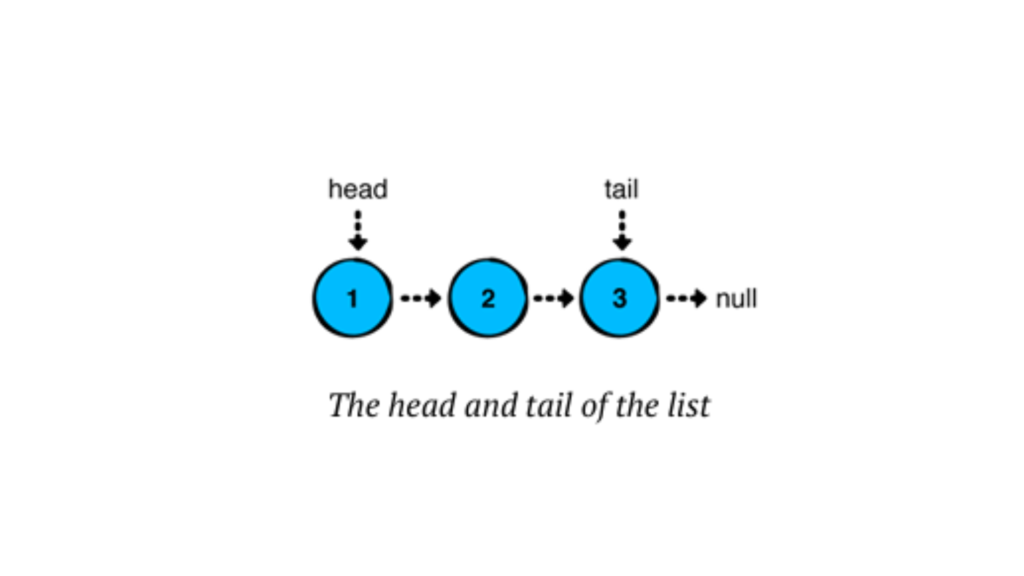
Basically, a linked list has a ‘head’ (the first node) and a ‘tail’ (the last node). In a singly linked list, we usually only deal with the head node, although the tail node can also be relevant, especially when adding elements at the end. The tail node becomes more important in doubly linked lists or circular linked lists, where it supports bidirectional traversal or maintains circular references. However, here, we will use both nodes in a singly linked list.
class LinkedList<T> {
private var head: Node<T>? = null
private var tail: Node<T>? = null
private var size = 0
// Method to check if the list is empty
fun isEmpty(): Boolean = size == 0
// to print nodes in linkedlist
override fun toString(): String {
if (isEmpty()) {
return "Empty list"
} else {
return head.toString()
}
}
}Here, a linked list has a ‘head’ (the first node) and a ‘tail’ (the last node). We’ll also store the list’s size in a ‘size’ property.
Now, to use this linked list, we need to store or add some values to it. Otherwise, we’d only be using an empty list. There are three major operations for adding values to a linked list, and we’ll explore each one in more details in the next blog. First, let’s see how to add a new value (or node) to the linked list and then print the result.
// Method to add a new node at the beginning
fun addFirst(data: T) {
val newNode = Node(data)
newNode.next = head
head = newNode
size++
}Here, we first create a new node with the passed value. Then, the new node’s next points to the head, and finally, we update the head to point to the newly created node. The same process is repeated whenever we add a new value.
Note: Whenever a new value is added, the list size increases. Therefore, we need to increment the size accordingly.
Now, let’s look at the complete code.
class LinkedList<T> {
private var head: Node<T>? = null
private var tail: Node<T>? = null
private var size = 0
// Method to check if the list is empty
fun isEmpty(): Boolean = size == 0
// to print nodes in linkedlist
override fun toString(): String {
if (isEmpty()) {
return "Empty list"
} else {
return head.toString()
}
}
// Method to add a new node at the beginning
fun addFirst(data: T) {
val newNode = Node(data)
newNode.next = head
head = newNode
size++
}
}Using the Linked List in Kotlin
Let’s put our linked list to the test! Here’s how we can use the LinkedList class:
fun main() {
val myList = LinkedList<String>()
println("Is the list empty? ${myList.isEmpty()}")
myList.addFirst("Kotlin")
myList.addFirst("Hello")
println(myList) // Output: Hello -> Kotlin -> null
println("Is the list empty? ${myList.isEmpty()}")
}Output
Is the list empty? true
Hello -> Kotlin
Is the list empty? falseConclusion
We’ve explored the key insertion operations in linked lists, along with the foundational concepts and structure that make them an essential part of data management. Understanding these operations provides a solid base for working with linked lists in various scenarios.
Linked lists might seem daunting, but with a bit of practice, you’ll be using them like a pro.








