Let’s explore Kotlin lambda name-resolution in this comprehensive guide. Learn how Kotlin resolves names in lambda expressions, enhancing your understanding of this powerful language feature. Master the intricacies of lambda function naming for improved code clarity and functionality.
Kotlin, with its concise and expressive syntax, brings functional programming concepts to the forefront. One of its powerful features is lambda expressions, which allow you to define and pass around blocks of code as first-class citizens. However, understanding the name-resolution rules when working with Kotlin lambdas can sometimes be a bit tricky. In this blog post, we’ll dive into these rules with clear examples to help you navigate them confidently.
What exactly are name-resolution rules?
Name-resolution rules refer to the guidelines that determine how the programming language identifies and selects variables, functions, or other symbols based on their names in different contexts. In the context of programming languages like Kotlin, these rules define how the compiler or interpreter decides which variable, function, or other entities should be referred to when a particular name is used.
For example, if you have a variable named x declared in a certain scope, and you use the name x in that scope, the name-resolution rules determine whether you are referring to the local variable x or some other variable with the same name in an outer or enclosing scope.
In the context of Kotlin lambda expressions, the name-resolution rules specify how variables from the surrounding scope are captured by lambdas and how lambda parameters interact with variables of the same name in outer scopes. Understanding these rules is crucial for writing correct and maintainable code when working with lambdas and closures.
Lambda Expressions in a Nutshell
Lambda expressions in Kotlin provide a way to define small, inline functions, often used as arguments to higher-order functions or assigned to variables. The general syntax of a lambda expression is as follows:
Now, let’s explore the intricacies of name resolution within lambda expressions. Let’s go through each of the lambda name-resolution rules in Kotlin with corresponding code examples and explanations
Capturing Variables (Just a short Recap for Rule_1)
Lambdas can capture variables from their surrounding scopes. These captured variables are accessible within the lambda’s body. However, the rules for capturing variables can sometimes lead to unexpected results.
In this case, the lambda captures the reference to outsideVariable, so it prints the updated value even after the variable changes.
Example 3: Capturing Final Variables
Kotlin
funmain() {val outsideVariable = 42val lambda: () -> Unit = {println(outsideVariable) } outsideVariable = 99// Compilation error: Val cannot be reassignedlambda()}
Since outsideVariable is a final (val) variable, it cannot be reassigned, leading to a compilation error.
Rule 1: Local Scope Access
Lambdas can access variables and functions from their surrounding scope (enclosing function or block) just like regular functions.
Kotlin
funmain() {val outerValue = 42val lambda = {println(outerValue) // Can access outerValue from the enclosing scope }lambda() // Prints: 42}
Explanation:Lambda expressions can access variables from their surrounding scope just like regular functions. The lambda in this example can access the outerValue variable defined in the main function.
Shadowing Lambda Parameters
Lambda parameters can shadow variables from outer scopes. This means that if a lambda parameter has the same name as a variable in the enclosing scope, the lambda will refer to its parameter, not the outer variable.
In this example, the lambda’s parameter value shadows the outer variable value, and the lambda refers to its parameter.
Rule 2: Shadowing
If a lambda parameter or a variable inside the lambda has the same name as a variable in the enclosing scope, the lambda’s local variable shadows the outer variable. The lambda will use its own variable instead of the outer one.
Kotlin
funmain() {valvalue = 42val lambda = { value: Int ->println(value) // Refers to the parameter inside the lambda }lambda(10) // Prints: 10}
Explanation: If a lambda parameter or a variable inside the lambda has the same name as a variable in the enclosing scope, the lambda’s local variable shadows the outer variable. In this example, the lambda parameter value shadows the outer value, so the lambda prints the parameter’s value.
Qualifying Lambda Parameters
To refer to variables from the outer scope when they are shadowed by lambda parameters, you can use the following approaches to refer to the outer variable:
Example 1: Qualifying Lambda Parameters
Kotlin
funmain() {valvalue = 42val lambda: (Int) -> Unit = { param ->// Use a different name instead of "value"println(value) // Refers to the outer variable "value" }lambda(99) // Prints: 42}
The simplest and most effective way is to use a different name for the lambda parameter.
Rule 3: Qualified Access
You can use a qualified name to access variables from an outer scope. For example, if you have a lambda inside a class method, you can access class-level properties using [email protected].
Kotlin
classExample {val property = "Hello from Example"funprintProperty() {val lambda = {println(this@Example.property) // Uses 'this@Example' to access class-level property }lambda() // Prints: Hello from Example }}funmain() {val example = Example() example.printProperty()}
Explanation:Inside a class method, you can access class-level properties using [email protected]. In this example, the lambda inside the printProperty method accesses the property of the Example class using this@Example, ensuring correct reference to the outer class.
Rule 4: Avoiding Variable Capture
If you want to avoid capturing variables by reference and instead capture their values, you can use the run function.
By using run, you ensure that the value of outsideVariable is captured instead of its reference.
Rule 5: Access to Receiver
In lambdas with receivers, you can directly access properties and functions of the receiver object without needing to qualify them with the receiver’s name.
Explanation: In lambdas with receivers (like the lambda passed to apply here), you can directly access properties and functions of the receiver object without needing to qualify them with the receiver’s name. The lambda modifies the StringBuilder receiver directly.
Rule 6: Closure
Lambda expressions have closure, which means they capture the variables they reference from their containing scope. These captured variables are available even if the containing scope is no longer active.
Explanation: Lambda expressions have closure, meaning they capture the variables they reference from their containing scope. In this example, the closure captures the outerValue variable from its surrounding scope and retains it even after the closureExample function has finished executing.
Rule 7: Anonymous Functions
In contrast to lambda expressions, anonymous functions don’t have implicit name-resolution rules. They behave more like regular functions in terms of scoping and access.
Kotlin
funmain() {val outerValue = 42val anonymousFunction = fun() {println(outerValue) // Can access outerValue like a regular function }anonymousFunction() // Prints: 42}
Explanation: Anonymous functions behave more like regular functions in terms of scoping and access. They don’t introduce the same implicit receiver and closure behavior that lambda expressions do.
I hope these examples help you understand how each name-resolution rule works in Kotlin lambda expressions
Conclusion
Kotlin’s lambda expressions provide a flexible and powerful way to work with functional programming concepts. Understanding the name-resolution rules, especially when capturing variables and dealing with parameter shadowing, is essential to writing clean and predictable code. By following the examples provided in this blog post, you’ll be better equipped to use lambdas effectively in your Kotlin projects. Happy coding!
In Kotlin, we often come across situations where we need to call functions on objects using dot notation, which can sometimes lead to verbose and cluttered code. To address this issue, Kotlin introduces the concept of infix functions, a powerful feature that allows you to call methods in a more concise and intuitive way. In...
Kotlin is a modern, statically typed programming language that runs on the Java Virtual Machine (JVM). One of the language’s powerful features is reflection, which allows you to examine and manipulate the structure of your code at runtime. Kotlin reflection provides a set of APIs that enable introspection, dynamic loading, and modification of classes, objects, properties, and functions. In this blog post, we will delve into the world of Kotlin reflection, exploring its various aspects and providing examples to help you understand its capabilities.
Basics of Reflection in Kotlin
Reflection in Kotlin allows you to access properties and methods of objects dynamically at runtime, without knowing them in advance. Normally, when you access a method or property, your program’s source code references a specific declaration, and the compiler ensures that the declaration exists. However, there are situations where you need to work with objects of any type or where the names of methods and properties are only known at runtime. This is where reflection comes in handy.
In Kotlin, there are two reflection APIs you can work with. The first one is the standard Java reflection API, which is defined in java.lang.reflect package. Since Kotlin classes are compiled to regular Java bytecode, the Java reflection API works perfectly with Kotlin. This means that Java libraries that use reflection are fully compatible with Kotlin code.
The second reflection API is the Kotlin reflection API, defined in the kotlin.reflect package. This API provides access to concepts that don’t exist in the Java world, such as properties and nullable types. However, it doesn’t fully replace the Java reflection API, and there may be cases where you need to use Java reflection instead. It’s important to note that the Kotlin reflection API is not restricted to Kotlin classes alone; you can use it to access classes written in any JVM language.
Let’s take an example to understand how reflection can be useful. Suppose you have a JSON serialization library that needs to serialize any object to JSON. Since the library can’t reference specific classes and properties, it relies on reflection to dynamically access and serialize the object’s properties at runtime. This allows the library to handle objects of different types without having prior knowledge about their structure.
Here’s a simplified example of using reflection in Kotlin to access the properties of an object dynamically:
Kotlin
dataclassPerson(val name: String, val age: Int)funmain() {val person = Person("Alice", 25)val properties = person.javaClass.declaredFieldsfor (property in properties) { property.isAccessible = truevalvalue = property.get(person)println("${property.name}: $value") }}
In this example, we have a Person class with two properties: name and age. Using reflection, we retrieve the declared fields (name and age) of the person object dynamically. By setting the isAccessible property to true, we ensure that we can access private fields as well. Finally, we get the values of the properties using the get() method and print them.
JVM dependency
To add the Kotlin reflection library as a dependency in your JVM project, you’ll need to include the kotlin-reflect artifact. Here’s how you can do it in Gradle and Maven:
Make sure to replace the version (1.9.0 in this example) with the version you desire to use or the latest updated one.
If you’re not using Gradle or Maven, ensure that the kotlin-reflect.jar is present in the classpath of your project. For IntelliJ IDEA projects that use the command-line compiler or Ant, the reflection library is automatically added by default. However, in the command-line compiler and Ant, you can use the -no-reflect compiler option to exclude kotlin-reflect.jar from the classpath if you don’t need it.
Note that, to reduce the runtime library size on platforms where it matters, such as Android, the Kotlin reflection API is packaged into a separate .jar file, kotlin-reflect.jar, which isn’t added to the dependencies of new projects by default. If you’re using the Kotlin reflection API, you need to make sure the library is added as a dependency. IntelliJ IDEA can detect the missing dependency and assist you with adding it.
Kotlin reflection API
The Kotlin reflection API provides a set of classes and interfaces that allow you to inspect and manipulate the structure and behavior of Kotlin classes at runtime. Here are the main components of the Kotlin reflection API that you mentioned:
KClass
In Kotlin, the main entry point for the reflection API is the KClass interface, which represents a class. It serves as a counterpart to Java’s java.lang.Class and allows you to perform various reflection operations.
To obtain an instance of KClass, you can use the ::class syntax on a class name. For example, if you have a class named MyClass, you can get its KClass instance like this:
Kotlin
val myClassKClass: KClass<MyClass> = MyClass::class
Once you have a KClass instance, you can use it to enumerate and access the declarations contained within the class, its superclasses, interfaces, and so on. The KClass interface provides functions and properties to perform these operations.
To get the KClass of an object at runtime, you can use the javaClass property, which returns the corresponding Java class. Then, you can access the .kotlin extension property on the Java class to obtain the Kotlin reflection counterpart (KClass). Here’s an example:
Kotlin
val obj = MyClass()val objKClass: KClass<outMyClass> = obj.javaClass.kotlin
In the above example, obj.javaClass returns the Java class of the obj instance, and .kotlin is used to obtain the corresponding KClass instance.
Once you have a KClass instance, you can use it to perform reflection operations such as accessing properties, functions, constructors, annotations, and more.
Kotlin
classPerson(val name: String, val age: Int)val person = Person("Alice", 29)val kClass = person.javaClass.kotlinprintln(kClass.simpleName)kClass.memberProperties.forEach { println(it.name) }
Output:
Person age name
Explanation:
The Person class is defined with two properties: name of type String and age of type Int.
An instance of Person named person is created with the values “Alice” and 29 for the name and age properties, respectively.
person.javaClass returns the corresponding Java class object for the person instance.
kotlin is used as an extension property on the Java class object to obtain the KClass instance representing the Person class, which is assigned to the kClass variable.
kClass.simpleName prints the simple name of the class, which in this case is “Person”.
kClass.memberProperties returns a collection of KProperty objects representing the non-extension properties of the class, including properties defined in its superclasses.
The forEach function is used to iterate over each KProperty object in the collection and print its name. In this example, it prints “age” and “name”, which are the names of the properties defined in the Person class.
By using kClass.memberProperties, you can retrieve all the non-extension properties defined in a class, including those inherited from its superclasses. This is a useful feature of Kotlin reflection for dynamically inspecting and working with class properties at runtime.
If you browse the declaration of KClass, you’ll see that, KClass interface in Kotlin reflection provides several useful methods and properties for accessing the contents of a class. Here are some additional features of KClass:
simpleName:Returns the simple name of the class as a String. This property is useful for getting the name of the class without any package information.
qualifiedName: Returns the fully qualified name of the class as a String, including the package name. This property is useful when you need the complete name of the class, including the package.
members:Returns a collection of KCallable objects representing all members (properties, functions, etc.) of the class. This includes both declared members and inherited members from superclasses.
constructors:Returns a collection of KFunction objects representing all constructors of the class. This allows you to retrieve information about the constructors and their parameters.
nestedClasses:Returns a collection of KClass objects representing all nested classes declared within the class. This is useful if you want to access and work with nested classes.
These are just a few examples of the additional features provided by the KClass interface. You can find more details and explore other methods and properties available in the Kotlin standard library reference (http://mng.bz/em4i).
KCallable
In Kotlin, when you want to access and call functions or properties dynamically through reflection, you can use the KCallable interface. KCallable is a super interface for functions and properties, and it declares the call method, which allows you to invoke the corresponding function or property getter.
Here’s an example of using the call method to call a function through reflection:
In this example, the ::foo syntax refers to the function foo and returns an instance of the KFunction class from the reflection API. By using the call method on kFunction, you can invoke the referenced function. In this case, we provide a single argument, 42.
If you try to call the function with an incorrect number of arguments, such as function.call(), it will throw a runtime exception with the message “IllegalArgumentException: Callable expects 1 arguments, but 0 were provided.”
To provide better type safety and enforce the correct number of arguments, you can use a more specific method called invoke. The type of the ::foo expression, in this case, is KFunction1<Int, Unit>, which contains information about parameter and return types. The 1 denotes that this function takes one parameter of type Int. You can then use the invoke method to call the function with a fixed number of arguments:
In the above example, kFunction.invoke(1, 2) calls the sum function with arguments 1 and 2, and kFunction(3, 4) is a shorthand notation for invoking the function. Since kFunction is of type KFunction2<Int, Int, Int>, it only accepts two arguments of type Int. If you try to call it with an incorrect number of arguments, the code won’t compile.
So, if you have a KFunction of a specific type with known parameters and return type, it’s recommended to use its invoke method for type safety. The call method is a more generic approach that can work with any type of function but doesn’t provide the same level of type safety.
BTW, How, and where are KFunctionN interfaces defined?
The KFunctionN interfaces, such as KFunction1, KFunction2, and so on, represent functions with different numbers of parameters. Each of these types extends the KFunction interface and adds an invoke member with the corresponding number of parameters.
For example, the KFunction2 interface declares the invoke method as follows:
Kotlin
operatorfuninvoke(p1: P1, p2: P2): R
Here, P1 and P2 represent the parameter types of the function, and R represents the return type.
It’s important to note that these function types, represented by KFunctionN, are synthetic compiler-generated types. You won’t find their explicit declarations in the kotlin.reflect package or any other standard Kotlin library.
The synthetic types approach allows for flexibility in the number of parameters a function type can have. Generating these types dynamically reduces the size of the kotlin-runtime.jar and avoids imposing artificial restrictions on the maximum number of function-type parameters.
So, the KFunctionN interfaces are synthetic types created by the compiler to represent functions with different numbers of parameters. They are not explicitly defined in the kotlin.reflect package, and their generation is based on the function’s parameter and return types.
KProperty
In Kotlin, you can also use reflection to access and retrieve property values dynamically. The KProperty interface provides methods to achieve this, with different interfaces for top-level properties and member properties.
For top-level properties, you can use instances of the KProperty0 interface, which has a no-argument get method. Here’s an example:
Kotlin
var counter = 0val kProperty = ::counterkProperty.setter.call(21)println(kProperty.get()) // Output: 21
In this example, kProperty refers to the top-level property counter. By calling kProperty.get(), you retrieve the current value of the property.
For member properties, you need to use the appropriate interface based on the number of arguments the get method requires. For example, KProperty1 is used for member properties with a single argument. You also need to provide the object instance on which the property is accessed. Here’s an example:
Kotlin
classPerson(val name: String, val age: Int)val person = Person("Alice", 29)val memberProperty = Person::ageprintln(memberProperty.get(person)) // Output: 29
In this case, memberProperty refers to the age property of the Person class. By calling memberProperty.get(person), you retrieve the value of the age property for the specific person instance.
It’s important to note that KProperty1 is a generic class. The type of memberProperty in the above example is KProperty<Person, Int>, where the first type parameter represents the type of the receiver (in this case, Person) and the second type parameter represents the property type (Int). This ensures that you can only call the get method with a receiver of the correct type. Attempting to call memberProperty.get("Alice") would result in a compilation error.
Please keep in mind that reflection can only be used to access properties defined at the top level or within a class, and not local variables within a function. If you try to obtain a reference to a local variable using::x, you will encounter a compilation error stating that “References to variables aren’t supported yet”.
Hierarchy of interfaces in Kotlin Reflection API
In Kotlin, there is a hierarchy of interfaces that allows you to access source code elements at runtime. These interfaces are designed to represent declarations and provide access to various information about them.
Hierarchy of interfaces in the Kotlin reflection API
Here’s a breakdown of the key interfaces mentioned:
KAnnotatedElement: This interface serves as the base for all other interfaces that represent declarations at runtime, such as KClass, KFunction, and KParameter. Since all declarations can be annotated, they inherit this interface to provide access to annotations.
KClass:This interface is used to represent both classes and objects at runtime. It provides access to information about the class or object, such as its name, superclass, interfaces, properties, and functions.
KProperty: This interface represents any property at runtime, regardless of whether it’s mutable (var) or read-only (val). It allows you to access information about the property, such as its name, type, annotations, and the getter function.
KMutableProperty: This is a subclass of KProperty and specifically represents a mutable property, which is declared using var. It provides additional functionality to modify the property’s value, in addition to the information available through KProperty.
Getter and Setter: These are special interfaces defined in Property and KMutableProperty to work with property accessors as functions. They extend the KFunction interface, allowing you to access information about the getter and setter functions associated with the property. For example, you can retrieve annotations applied to the getter or setter.
Note that the figure mentions the omission of specific interfaces like KProperty0 for simplicity. KProperty0 represents a property without any parameters (zero-argument property). Similarly, there are other specific interfaces in the hierarchy that cater to different scenarios and numbers of parameters.
Overall, these interfaces in the hierarchy provide a flexible and comprehensive way to access and manipulate source code elements at runtime, allowing you to retrieve information, modify values, and work with annotations.
Best Practices and Use Cases for Kotlin Reflection:
Serialization and Deserialization
Reflection is commonly used in serialization and deserialization libraries. It allows these libraries to introspect object structures dynamically, enabling automatic conversion between objects and their serialized forms. Reflection facilitates the inspection of object properties and their values, making it easier to transform objects into a serialized format and vice versa.
In this example, reflection is used to serialize a Person object by obtaining its properties using memberProperties and creating a map of property names and values. The same reflection-based approach is used to deserialize the serialized data back into a Person object.
Dependency Injection
Frameworks like Spring heavily rely on reflection for implementing dependency injection. Reflection enables these frameworks to scan classes, examine annotations, and wire dependencies at runtime. By leveraging reflection, frameworks can automatically discover and instantiate the required dependencies, reducing the need for manual configuration. Reflection helps in achieving loose coupling and makes the dependency injection process more flexible and adaptable.
Kotlin
classServiceA {fundoSomething() {println("Service A is doing something.") }}classServiceB {fundoSomethingElse() {println("Service B is doing something else.") }}classClient(privateval serviceA: ServiceA, privateval serviceB: ServiceB) {funperformActions() { serviceA.doSomething() serviceB.doSomethingElse() }}funmain() {val clientClass = Client::classval constructors = clientClass.constructorsif (constructors.isNotEmpty()) {val constructor = constructors.first()val parameters = constructor.parameters// Dependency injection using reflectionval serviceA = ServiceA()val serviceB = ServiceB()val client = constructor.callBy(mapOf(parameters[0] to serviceA, parameters[1] to serviceB)) client.performActions() }}
In this example, reflection is used for dependency injection. The Client class has dependencies on ServiceA and ServiceB. Using reflection, the constructor of Client is obtained, and the dependencies are instantiated (ServiceA and ServiceB). The dependencies are then injected into the Client object using callBy and a map of parameter-to-argument pairs.
Testing and Mocking
Reflection is valuable in testing and mocking scenarios. It allows developers to examine and modify internal state, invoke private methods, and create mock objects dynamically. Reflection provides the ability to access and modify otherwise inaccessible members, which is particularly useful for unit testing private methods or creating mock objects with dynamically generated behavior. It simplifies the process of writing test cases and enables comprehensive testing of code components.
Kotlin
classMathUtils {privatefunmultiply(a: Int, b: Int): Int {return a * b }funsquare(n: Int): Int {returnmultiply(n, n) }}funmain() {val mathUtils = MathUtils()val multiplyMethod = mathUtils::class.declaredFunctions .firstOrNull { it.name == "multiply" } multiplyMethod?.let { it.isAccessible = trueval result = it.call(mathUtils, 4, 5)println(result) // Output: 20 }}
In this example, reflection is used for testing and mocking. The private multiply method of the MathUtils class is accessed using reflection by setting its accessibility to true. The call method is then used to invoke the method with arguments. This allows us to test the private method’s functionality or mock its behavior in a controlled testing environment.
By following these best practices and leveraging Kotlin reflection in appropriate use cases such as serialization, dependency injection, and testing, developers can harness the full potential of reflection to enhance the flexibility, extensibility, and maintainability of their Kotlin applications.
Limitations of Kotlin Reflection
Reflection has some limitations, such as being unable to access private members by default, requiring additional permissions in security-restricted environments, and being less type-safe than static typing.
The limitations of Kotlin reflection include:
Performance Overhead: Reflection operations incur performance overhead compared to statically typed code, as they involve runtime introspection and dynamic dispatch.
Limited Access to Private Members: By default, Kotlin reflection does not provide direct access to private members of classes. Access to private members requires setting accessibility, which may have security implications.
Security and Permissions: In security-restricted environments, using reflection may require additional permissions or explicit configuration to prevent unauthorized access.
Type Safety: Reflection is inherently less type-safe compared to static typing. Type errors that would normally be caught by the compiler can only be detected at runtime when using reflection.
Limited Compile-Time Checks: Reflection bypasses many compile-time checks provided by the Kotlin compiler. Renaming elements accessed via reflection may lead to runtime errors that are not caught during compilation.
Platform Dependencies: Kotlin reflection relies on platform-specific features and APIs, which may introduce variations in behavior and capabilities across different platforms.
Conclusion
Kotlin reflection provides a powerful set of APIs that enable you to examine and manipulate your code dynamically at runtime. From accessing class information to modifying properties and invoking functions dynamically, reflection opens up a whole new range of possibilities in your Kotlin projects. However, it’s essential to use reflection judiciously and be aware of its performance implications. By understanding the concepts and best practices outlined in this blog post, you’ll be well-equipped to leverage the full potential of Kotlin reflection in your applications.
Annotations are a powerful feature in the Kotlin programming language that allows you to add metadata and additional information to your code. They provide a way to decorate classes, functions, properties, and other program elements with custom markers, which can be processed at compile time or runtime. In this blog post, we will dive deep...
Kotlin is a modern programming language that offers powerful features for building robust and type-safe applications. One such feature is generics, which allows developers to write reusable code that can work with different types. In this blog post, we will delve into the concept of Kotlin generics and explore the intricacies of variance, providing clear explanations and practical examples along the way.
In Kotlin, there are some advanced concepts related to generics that we will explore. These concepts include reified type parameters and declaration-site variance. While they may sound unfamiliar, don’t worry! This blog post will cover them in detail.
Generic type parameters
In Kotlin Generics, you can define types that have type parameters, allowing for more flexible and reusable code. When you create an instance of such a type, you substitute the type parameters with specific types, known as type arguments. This allows you to specify the kind of data that will be stored or processed by the type.
For example, let’s consider the List type. In Kotlin, you can declare a variable of type List<String>, which means it holds a list of strings. Similarly, the Map type has type parameters for the key type (K) and the value type (V). You can instantiate a Map with specific arguments, such as Map<String, Person>, which represents a map with string keys and Person values.
In many cases, the Kotlin compiler can infer the type arguments based on the context. For example:
Kotlin
val authors = listOf("Stan Lee", "J.K Rowling")
Here, since both values passed to the listOf function are strings, the compiler infers that you’re creating a List<String>. However, when creating an empty list, there is nothing to infer the type argument from, so you need to specify it explicitly. You have two options for specifying the type argument:
Kotlin
// here created empty list, so nothing to infer, so specified type argument(i.e String) explicitly.val readers: MutableList<String> = mutableListOf()val readers = mutableListOf<String>()
Both of these declarations are equivalent and create an empty mutable list of strings.
It’s important to note that Kotlin always requires type arguments to be either specified explicitly or inferred by the compiler. In contrast, Java allows the use of raw types, where you can declare a variable of a generic type without specifying the type argument. However, Kotlin does not support raw types, and type arguments must always be defined.
So, in Kotlin, you won’t encounter situations where you can use a generic type without providing the type arguments explicitly or inferring them through type inference.
Generic functions and properties
In Kotlin generics, You can write generic functions and properties to work with any type, providing flexibility and reusability. Generic functions have their own type parameters, which are replaced with specific type arguments when invoking the function. Similarly, generic properties allow you to define properties that are parameterized by a type.
Let’s explore examples of generic functions and properties to understand how they work.
Generic Functions
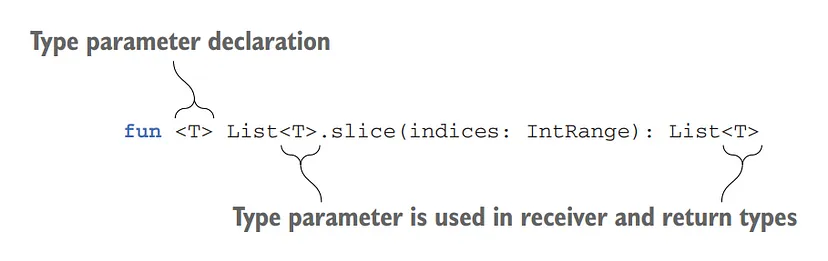
To illustrate, let’s consider the slice function, which returns a list containing elements at specified indices. Its declaration looks like this:
The generic function slice has the type parameter T
Kotlin
fun <T> List<T>.slice(indices: IntRange): List<T> {// Implementation goes here}
In this example, <T> is the type parameter, which represents the unknown type that will be specified when calling the function. The List<T> is the receiver type, indicating that this function is an extension function for lists. The return type List<T> ensures that the resulting list has the same type as the input list.
When invoking the slice function, you can either explicitly specify the type argument or rely on type inference:
Kotlin
val letters = ('a'..'z').toList()println(letters.slice<Char>(0..2)) // Specifies the type argument explicitly, o/p - [a, b, c]println(letters.slice(10..13)) // The compiler infers that T is Char here, o/p - [k, l, m, n]
The compiler can often infer the type argument based on the context, so you don’t need to explicitly provide it. In both cases, the result type will be List<Char>.
Generic type parameter used in parameter Function Type
When a generic type parameter is used in a parameter function type like (T) -> Boolean, it allows the function to accept a lambda or function that operates on elements of the generic type. The compiler infers the type based on the context and ensures type safety throughout the filtering process. Let’s see it in detail.
Consider the filter function, which filters a list based on a provided predicate. Its declaration looks like this:
In this example, <T> is the type parameter, representing the unknown type that will be specified when calling the function. The List<T> is the receiver type, indicating that this function is an extension function for lists. The predicate parameter has the function type (T) -> Boolean, which means it accepts a function that takes a parameter of type T and returns a Boolean value.
When using the filter function, you can provide a lambda expression as the predicate. The compiler infers the type based on the function’s declaration and the type of the list being filtered. Here’s an example:
Kotlin
val authors = listOf("Stan Lee", "J.K.Rowling")val readers = mutableListOf<String>(/* ... */)val filteredReaders = readers.filter { it !in authors }
In this case, the lambda expression { it !in authors } is used as the predicate. The compiler determines that the lambda parameter it has the type T, which is inferred to be String because the filter function is called on List<String> (readers).
By utilizing the generic type parameter T in the function declaration, the filter function can work with any type of list and apply the provided predicate accordingly.
Generic Extension Properties
Similar to generic functions, you can declare generic extension properties using the same syntax. For example, let’s define an extension property penultimate that returns the element before the last one in a list:
Kotlin
val <T> List<T>.penultimate: T// This generic extension property can be called on a list of any kindget() = this[size - 2]
In this case, <T> is the type parameter, and it is part of the receiver type List<T>. The get() function provides the implementation for retrieving the penultimate element.
You can then use the penultimate property on a list:
Kotlin
println(listOf(1, 2, 3, 4).penultimate) //The type parameter T is inferred to be Int in this invocation// Output: 3
Note that generic non-extension properties are not allowed in Kotlin. Regular (non-extension) properties cannot have type parameters because they are associated with a specific class or obect and cannot store multiple values of different types.
If you attempt to declare a generic non-extension property, the compiler will report an error similar to the following:
Kotlin
val <T> x: T = TODO()// ERROR: type parameter of a property must be used in its receiver type
The error message indicates that the type parameter T used in the property declaration should be associated with its receiver type, but since regular properties are specific to a class or object, it doesn’t make sense to have a generic property that can accommodate multiple types.
Declaring generic classes
Just like in Java, in Kotlin also, you can declare generic classes and interfaces by using angle brackets after the class name and specifying the type parameters within the angle brackets. These type parameters can then be used within the body of the class, just like any other types.
For example, let’s consider the declaration of the standard Java interface List in Kotlin:
In this example, List is declared as a generic interface with a type parameter T. You can use this type parameter in the interface’s methods and other declarations.
When a class extends a generic class or implements a generic interface, you need to provide a type argument for the generic parameter of the base type. This type argument can be a specific type or another type parameter.
In the first example, the StringList class extends List<String>, which means it specifically contains String elements. The get function in StringList will have the signature fun get(index: Int): String instead of fun get(index: Int): T.
In the second example, the ArrayList class defines its own type parameter T and specifies it as the type argument for the superclass List<T>.
Note that T in ArrayList is not the same as in List — it’s a new type parameter, and it doesn’t need to have the same name.
Additionally, a class can even refer to itself as a type argument. Classes implementing the Comparable interface are the classical example of this pattern. Any comparable element must define how to compare it with objects of the same type:
In this example, the String class implements the generic Comparable interface by specifying String as the type argument for the type parameter T.
Type parameter constraints
Type parameter constraints in Kotlin allow you to limit the types that can be used as arguments for a class or function. This ensures that only specific types or their subtypes can be used.
When you specify a type as an upper bound constraint for a type parameter of a generic type, the corresponding type arguments in specific instantiations of the generic type must be either the specified type or its subtypes(For now, you can think of subtype as a synonym for subclass).
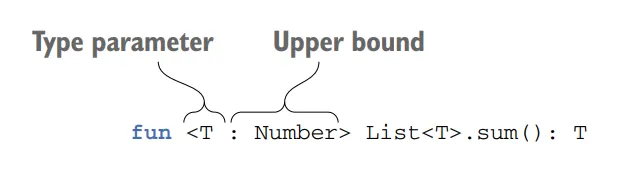
To specify a constraint, you put a colon after the type parameter name, followed by the type that’s the upper bound for the type parameter. In Java, you use the keyword extends to express the same concept: T sum(List list)
Constraints are defined by specifying an upper bound after a type parameter
Let’s start with an example. Suppose we have a function called sum that calculates the sum of elements in a list. We want this function to work with List<Int> or List<Double>, but not with List<String>. To achieve this, we can define a type parameter constraint that specifies the type parameter of sum must be a number.
Kotlin
fun <T : Number> sum(list: List<T>): T {var result = 0.0for (element in list) { result += element.toDouble() }return result as T}
In this example, we specify <T : Number> as the type parameter constraint, indicating that T must be a subclass of Number. Now, when we invoke the function with a list of integers, it works correctly:
Kotlin
println(sum(listOf(1, 2, 3))) // Output: 6
The type argument Int extends Number, so it satisfies the type parameter constraint.
You can also use methods defined in the class used as the bound for the type parameter constraint. Here’s an example:
In this case, T is constrained to be a subclass of Number, so we can use methods defined in the Number class, such as toDouble().
Now let’s consider another example where we want to find the maximum of two items. Since it’s only possible to compare items that are comparable to each other, we need to specify that requirement in the function signature using the Comparable interface:
Kotlin
fun <T : Comparable<T>> max(first: T, second: T): T {returnif (first > second) first else second}println(max("kotlin", "java")) // Output: kotlin
In this case, we specify <T : Comparable<T>> as the type parameter constraint. It ensures that T can only be a type that implements the Comparable interface. Hence, we can compare first and second using the > operator.
If you try to call max with incomparable items, such as a string and an integer, it won’t compile:
Kotlin
println(max("kotlin", 42)) // ERROR: Type parameter bound for T is not satisfied
The error occurs because the type argument Any inferred for T is not a subtype of Comparable<Any>, which violates the type parameter constraint.
In some cases, you may need to specify multiple constraints on a type parameter. You can use a slightly different syntax for that. Here’s an example where we ensure that the given CharSequence has a period at the end and can be appended:
Kotlin
fun <T> ensureTrailingPeriod(seq: T)where T : CharSequence, T : Appendable {if (!seq.endsWith('.')) { seq.append('.') }}val helloWorld = StringBuilder("Hello World")ensureTrailingPeriod(helloWorld)println(helloWorld) // Output: Hello World.
In this case, we specify the constraints T : CharSequence and T : Appendable using the where clause. This ensures that the type argument must implement both the CharSequence and Appendable interfaces, allowing us to use operations like endsWith and append on values of that type
Type parameter constraints are also commonly used when you want to declare a non-null type parameter. This helps enforce that the type argument cannot be nullable, ensuring that you always have a non-null value. Let’s see it in more detail.
Making type parameters non-null
In Kotlin, when you declare a generic class or function, you can substitute any type argument, including nullable types, for its type parameters. By default, a type parameter without an upper bound specified will have the upper bound of Any? which means it can accept both nullable and non-nullable types.
Let’s take an example to understand this. Consider the Processor class defined as follows:
Kotlin
classProcessor<T> {funprocess(value: T) {value?.hashCode() // value” is nullable, so you have to use a safe call }}
In the process function of this class, the parameter value is nullable, even though T itself is not marked with a question mark. This is because specific instantiations of the Processor class can use nullable types for T. For example, you can create an instance of Processor<String?> which allows nullable strings as its type argument:
Kotlin
val nullableStringProcessor = Processor<String?>() // String?, which is a nullable type, is substituted for TnullableStringProcessor.process(null) // This code compiles fine, having “null” as the “value” argument
If you want to ensure that only non-null types can be substituted for the type parameter, you can specify a constraint or an upper bound. If the only restriction you have is nullability, you can use Any as the upper bound instead of the default Any?. Here’s an example:
Kotlin
classProcessor<T : Any> { // Specifying a non-“null” upper boundfunprocess(value: T) {value.hashCode() // “value” of type T is now non-“null” }}
In this case, the <T : Any> constraint ensures that the type T will always be a non-nullable type. If you try to use a nullable type as the type argument, like Processor<String?>(), the compiler will produce an error. The reason is that String? is not a subtype of Any (it’s a subtype of Any?, which is a less specific type):
Kotlin
val nullableStringProcesor = Processor<String?>()// Error: Type argument is not within its bounds: should be subtype of 'Any'
It’s worth noting that you can make a type parameter non-null by specifying any non-null type as an upper bound, not only Any. This allows you to enforce stricter constraints based on your specific needs.
Underscore operator ( _ ) for type arguments
The underscore operator _ in Kotlin is a type inference placeholder that allows the Kotlin compiler to automatically infer the type of an argument based on the context and other explicitly specified types.
Kotlin
abstractclassSomeClass<T> {abstractfunexecute() : T}classSomeImplementation : SomeClass<String>() {overridefunexecute(): String = "Test"}classOtherImplementation : SomeClass<Int>() {overridefunexecute(): Int = 42}objectRunner {inlinefun <reifiedS: SomeClass<T>, T> run() : T {return S::class.java.getDeclaredConstructor().newInstance().execute() }}funmain() {// T is inferred as String because SomeImplementation derives from SomeClass<String>val s = Runner.run<SomeImplementation, _>()assert(s == "Test")// T is inferred as Int because OtherImplementation derives from SomeClass<Int>val n = Runner.run<OtherImplementation, _>()assert(n == 42)}
Don’t worry! Let’s break down the code step by step:
In this code, we have an abstract class called SomeClass with a generic type T. It declares an abstract function execute() that returns an object of type T.
We have a class called SomeImplementation which extends SomeClass and specifies the generic type as String. It overrides the execute() function and returns the string value "Test".
Similarly, we have another class called OtherImplementation which extends SomeClass and specifies the generic type as Int. It overrides the execute() function and returns the integer value 42.
Below that, we have an object called Runner with a function run(). This function is generic and has two type parameters S and T. It uses the reified keyword to access the type information at runtime. Inside the function, it creates an instance of the specified class S using reflection (getDeclaredConstructor().newInstance()) and calls the execute() function on it, returning the result of type T.
In the above code, the underscore operator is used in the main() function when calling the Runner.run() function. Let’s take a closer look:
Kotlin
val s = Runner.run<SomeImplementation, _>()
In this line, the type parameter T is explicitly specified as _ for the Runner.run() function. Here, _ acts as a placeholder for the type to be inferred by the compiler. Since SomeImplementation derives from SomeClass<String>, the compiler infers T as String for this invocation. Therefore, the variable s is inferred to be of type String, and the Runner.run() function returns the result of executing SomeImplementation, which is the string "Test".
Kotlin
val n = Runner.run<OtherImplementation, _>()
Similarly, in this line, the type parameter T is specified as _ for the Runner.run() function. Since OtherImplementation derives from SomeClass<Int>, the compiler infers T as Int for this invocation. Consequently, the variable n is inferred to be of type Int, and the Runner.run() function returns the result of executing OtherImplementation, which is the integer 42.
By using the underscore operator _ as a type argument, the compiler can automatically infer the appropriate type based on the context and the explicitly specified types.
BTW, how do generics work at runtime?
In Kotlin, generics are a compile-time feature rather than a runtime feature. This means that type information is erased at runtime and not available for inspection or manipulation by the program.
When you use generics in Kotlin, the compiler performs type checking and ensures type safety at compile time. It enforces that the correct types are used in generic functions or classes based on the type parameters specified.
At runtime, Kotlin uses type erasure to remove the generic type information. This is done for compatibility with Java, as both languages share a common runtime environment known as the Java Virtual Machine (JVM). The JVM does not natively support reified generics, which would allow for preserving type information at runtime.
Due to type erasure, you cannot directly access the type parameters of a generic class or function at runtime. For example, if you define a List<String> and a List<Int>, they both become List<Any> at runtime.
However, there are cases where Kotlin provides a workaround for working with generics at runtime using reified types. The reified keyword can be used in inline functions to retain type information within the body of the function. This allows you to perform type checks or access the class instance of the type parameter within the function.
Here’s an example of an inline function that utilizes reified types to perform type checks at runtime:
Kotlin
inlinefun <reifiedT> getType(obj: T) {if (obj is T) {println("Object is of type ${T::class.simpleName}") } else {println("Object is not of type ${T::class.simpleName}") }}
In this example, the reified T declaration allows you to access the class instance of the type parameter T using T::class. This wouldn’t be possible without the reified keyword.
Please note that although reified types enable limited runtime access to type information, they only work within the scope of inline functions. Outside of inline functions, the type information is still erased at runtime.
Variance: generics and subtyping
The concept of variance describes how types with the same base type and different type arguments relate to each other: for example, List<String> and List<Any>. It’s important to understand variance when working with generic classes or functions because it helps ensure the safety and consistency of your code.
Why variance exists: passing an argument to a function
To illustrate why variance is important, let’s consider passing arguments to functions. Suppose we have a function that takes a List<Any> as an argument. Is it safe to pass a variable of type List<String> to this function?
In the case of a function that prints the contents of the list, such as:
You can safely pass a list of strings (List<String>) to this function. Each element in the list is treated as an Any, and since String is a subtype of Any, it is considered safe.
However, let’s consider another function that modifies the list:
If you attempt to pass a list of strings (MutableList<String>) to this function, like so:
Kotlin
val strings = mutableListOf("abc", "bac")addAnswer(strings)println(strings.maxBy { it.length })
You will encounter a ClassCastException at runtime. This occurs because the function addAnswer tries to add an integer (42) to a list of strings. If the compiler allowed this, it would lead to a type inconsistency when accessing the contents of the list as strings. To prevent such issues, the Kotlin compiler correctly forbids passing a MutableList<String> as an argument when a MutableList<Any> is expected.
So, the answer to whether it’s safe to pass a list of strings to a function expecting a list of Any objects depends on whether the function modifies the list. If the function only reads the list, it is safe to pass a List with a more specific element type. However, if the list is mutable and the function adds or replaces elements, it is not safe.
Kotlin provides different interfaces, such as List and MutableList, to control safety based on mutability. If a function accepts a read-only list, you can pass a List with a more specific element type. However, if the list is mutable, you cannot do that.
In the upcoming sections, we’ll explore these concepts in the context of generic classes. We’ll also examine why List and MutableList differ regarding their type arguments. But before that, let’s discuss the concepts of type and subtype.
Difference between Classes, types, and subtypes
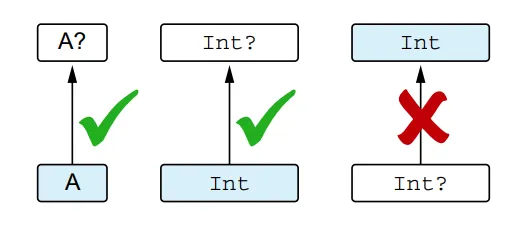
In Kotlin, the type of a variable specifies the possible values it can hold. The terms “type” and “class” are sometimes used interchangeably, but they have distinct meanings. In the case of a non-generic class, the class name can be used directly as a type. For example, var x: String declares a variable that can hold instances of the String class. However, the same class name can also be used to declare a nullable type, such as var x: String?which indicates that the variable can hold either a String or null. So each Kotlin class can be used to construct at least two types.
When it comes to generic classes, things get more complex. To form a valid type, you need to substitute a specific type as a type argument for the class’s type parameter. For example, List is a class, not a type itself, but the following substitutions are valid types: List<Int>, List<String?>, List<List<String>>, and so on. Each generic class can generate an infinite number of potential types.
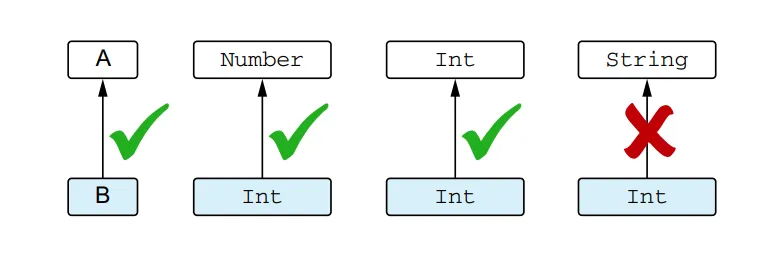
To discuss the relationship between types, it’s important to understand the concept of subtyping. Type B is considered a subtype of type A if you can use a value of type B wherever a value of type A is expected. For example, Int is a subtype of Number, but Int is not a subtype of String. Note that a type is considered a subtype of itself. The term “supertype” is the opposite of subtype: if A is a subtype of B, then B is a supertype of A.
B is a subtype of A if you can use it when A is expected
Understanding subtype relationships is crucial because the compiler performs checks whenever you assign a value to a variable or pass an argument to a function. For example:
Storing a value in a variable is only allowed if the value’s type is a subtype of the variable’s type. In this case, since Int is a subtype of Number, the declaration val n: Number = i is valid. Similarly, passing an expression to a function is only allowed if the expression’s type is a subtype of the function’s parameter type. In the example, the type Int of the argument i is not a subtype of the function parameter type String, so the invocation of the f function does not compile.
In simpler cases, subtype is essentially the same as subclass. For example, Int is a subclass of Number, so the Int type is a subtype of the Number type. If a class implements an interface, its type is a subtype of the interface type. For instance, String is a subtype of CharSequence.
Nullable types introduce a scenario where subtype and subclass differ. A non-null type is a subtype of its corresponding nullable type, but they both correspond to the same class.
A non-null type A is a subtype of nullable A?, but not vice versa
You can store the value of a non-null type in a variable of a nullable type, but not vice versa. For example:
Kotlin
val s: String = "abc"val t: String? = s
In this case, the value of the non-null type String can be stored in a variable of the nullable type String?. However, you cannot assign a nullable type to a non-null type because null is not an acceptable value for a non-null type.
The distinction between subclasses and subtypes becomes particularly important when dealing with generic types. This brings us back to the question from the previous section: is it safe to pass a variable of type List<String> to a function expecting List<Any>? We’ve already seen that treating MutableList<String> as a subtype of MutableList<Any> is not safe. Similarly, MutableList<Any> is not a subtype of MutableList<String> either.
A generic class, such as MutableList, is called invariant on the type parameter if, for any two different types A and B, MutableList<A> is neither a subtype nor a supertype of MutableList<B>. In Java, all classes are invariant, although specific uses of those classes can be marked as non-invariant (as you’ll see soon).
In the previous section, we encountered a class, List, where the subtyping rules are different. The List interface in Kotlin represents a read-only collection. If type A is a subtype of type B, then List<A> is a subtype of List<B>. Such classes or interfaces are called covariant. In the upcoming sections, we’ll explore the concept of covariance in more detail and explain when it’s possible to declare a class or interface as covariant.
Covariance: preserved subtyping relation
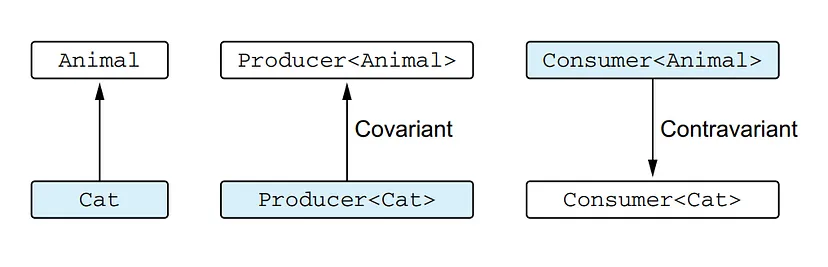
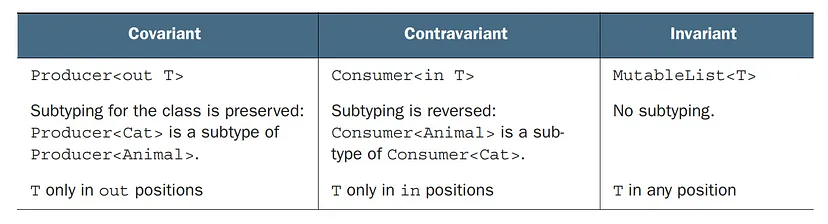
Covariance refers to preserving the subtyping relation between generic classes. In Kotlin, you can declare a class to be covariant on a specific type parameter by using the out keyword before the type parameter’s name.
A covariant class is a generic class (we’ll use Producer as an example) for which the following holds: Producer<A> is a subtype of Producer<B> if A is a subtype of B. We say that the subtyping is preserved. For example, Producer<Cat> is a subtype of Producer<Animal> because Cat is a subtype of Animal.
Here’s an example of the Producer interface using the out keyword:
Kotlin
interfaceProducer<outT> {funproduce(): T}
Flexible Function Argument and Return Value Passing
Covariance in Kotlin allows you to pass values of a class as function arguments and return values, even when the type arguments don’t exactly match the function definition. This means that you can use a more specific type as a substitute for a more generic type.
Suppose we have a hierarchy of classes involving Animal, where Cat is a subclass of Animal. We also have a generic interface called Producer, which represents a producer of objects of type T. We’ll make the Producer interface covariant by using the out keyword on the type parameter.
Kotlin
interfaceProducer<outT> {funproduce(): T}
Now, let’s define a class AnimalProducer that implements the Producer interface for the Animal type:
Since Cat is a subtype of Animal, we can also use CatProducer wherever a Producer<Animal> is expected. This is possible because we declared the Producer interface as covariant.
Now, let’s see how covariance allows us to pass these producers as function arguments and return values:
funmain() {val animalProducer = AnimalProducer()val catProducer = CatProducer()feedAnimal(animalProducer) // Passes an AnimalProducer, which is a Producer<Animal>feedAnimal(catProducer) // Passes a CatProducer, which is also a Producer<Animal>}
In the feedAnimal function, we expect a Producer<Animal> as an argument. With covariance, we can pass both AnimalProducer and CatProducer instances because Producer<Cat> is a subtype of Producer<Animal> due to the covariance declaration.
This demonstrates how covariance allows you to treat more specific types (Producer<Cat>) as if they were more generic types (Producer<Animal>) when it comes to function arguments and return values.
BTW, How covariance guarantees type safety?
Suppose we have a class hierarchy involving Animal, where Cat is a subclass of Animal. We also have a Herd class that represents a group of animals.
Kotlin
openclassAnimal {funfeed() { /* feeding logic */ }}classHerd<T : Animal> { // The type parameter isn’t declared as covariantval size: Intget() = /* calculate the size of the herd */operatorfunget(i: Int): T { /* get the animal at index i */ }}funfeedAll(animals: Herd<Animal>) {for (i in0 until animals.size) { animals[i].feed() }}
Now, suppose you have a function called takeCareOfCats, which takes a Herd<Cat> as a parameter and performs some operations specific to cats.
Kotlin
classCat : Animal() {funcleanLitter() { /* clean litter logic */ }}funtakeCareOfCats(cats: Herd<Cat>) {for (i in0 until cats.size) { cats[i].cleanLitter()// feedAll(cats) // This line would cause a type-mismatch error, Error: inferred type is Herd<Cat>, but Herd<Animal> was expected }}
In this case, if you try to pass the cats herd to the feedAll function, you’ll get a type-mismatch error during compilation. This happens because you didn’t use any variance modifier on the type parameter T in the Herd class, making the Herd<Cat> incompatible with Herd<Animal>. Although you could use an explicit cast to overcome this issue, it is not a recommended approach.
To make it work correctly, you can make the Herd class covariant by using the out keyword on the type parameter:
Kotlin
classHerd<outT : Animal> { // The T parameter is now covariant.// ...}funtakeCareOfCats(cats: Herd<Cat>) {for (i in0 until cats.size) { cats[i].cleanLitter() }feedAll(cats) // Now this line works because of covariance, You don’t need a cast.
By marking the type parameter as covariant, you ensure that the subtyping relation is preserved, and T can only be used in \”out\” positions. This guarantees type safety and allows you to pass a Herd<Cat> where a Herd<Animal> is expected.
Usage of covariance
Covariance in Kotlin allows you to make a class covariant on a type parameter, but it also imposes certain constraints to ensure type safety. The type parameter can only be used in “out” positions, which means it can produce values of that type but not consume them.
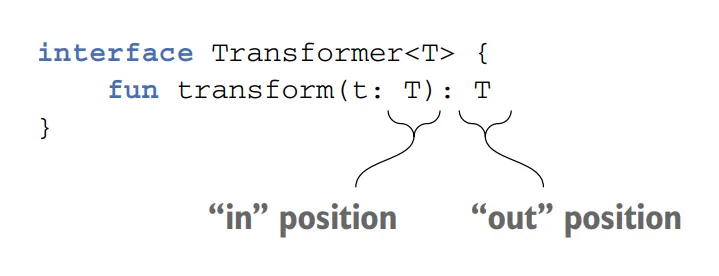
You can’t make any class covariant: it would be unsafe. Making the class covariant on a certain type parameter constrains the possible uses of this type parameter in the class. To guarantee type safety, it can be used only in so-called out positions, meaning the class can produce values of type T but not consume them. Uses of a type parameter in declarations of class members can be divided into “in” and “out” positions.
Let’s consider a class that declares a type parameter T and contains a function that uses T. We say that if T is used as the return type of a function, it’s in the out position. In this case, the function produces values of type T. If T is used as the type of a function parameter, it’s in the in position. Such a function consumes values of type T.
The function parameter type is called in position, and the function return type is called out position
The out keyword on a type parameter of the class requires that all methods using T have T only in “out” positions and not in “in” positions. This keyword constrains possible use of T, which guarantees safety of the corresponding subtype relation.
Let’s understand this with some examples. Consider the Herd class, which is declared as Herd<out T : Animal>. The type parameter T is used only in the return value of the get method. This is an “out” position, and it is safe to declare the class as covariant. For instance, Herd<Cat> is considered a subtype of Herd<Animal> because Cat is a subtype of Animal.
Kotlin
classHerd<outT : Animal> {val size: Int = ...operatorfunget(i: Int): T { ... } // Uses T as the return type}
Similarly, the List<T> interface in Kotlin is covariant because it only defines a get method that returns an element of type T. Since there are no methods that store values of type T, it is safe to declare the class as covariant.
Kotlin
interfaceList<outT> : Collection<T> {operatorfunget(index: Int): T// Read-only interface that defines only methods that return T (so T is in the “out” position)// ...}
You can also use the type parameter T as a type argument in another type. For example, the subList method in the List interface returns a List<T>, and T is used in the “out” position.
Kotlin
interfaceList<outT> : Collection<T> {funsubList(fromIndex: Int, toIndex: Int): List<T> // Here T is in the “out” position as well.// ...}
However, you cannot declare MutableList<T> as covariant on its type parameter because it contains methods that both consume and produce values of type T. Therefore, T appears in both “in” and “out” positions, and making it covariant would be unsafe.
Kotlin
interfaceMutableList<T> : List<T>, MutableCollection<T> { //MutableList can’t be declared as covariant on T …overridefunadd(element: T): Boolean// … because T is used in the “in” position.}
The compiler enforces this restriction. It would report an error if the class was declared as covariant: Type parameter T is declared as ‘out’ but occurs in ‘in’ position.
Constructor Parameters and Variance
In Kotlin, constructor parameters are not considered to be in the “in” or “out” position when it comes to variance. This means that even if a type parameter is declared as “out,” you can still use it in a constructor parameter declaration without any restrictions.
The type parameter T is declared as “out” but it can still be used in the constructor parameter vararg animals: T without any issues. The variance protection is not applicable to the constructor because it is not a method that can be called later, so there are no potentially dangerous method calls that need to be restricted.
However, if you use the val or var keyword with a constructor parameter, it declares a property with a getter and setter (if the property is mutable). In this case, the type parameter T is used in the “out” position for a read-only property and in both “out” and “in” positions for a mutable property.
Here, the type parameter T cannot be marked as “out” because the class contains a setter for the leadAnimal property, which uses T in the “in” position. The presence of a setter makes it necessary to consider both “out” and “in” positions for the type parameter.
It’s important to note that the position rules for variance in Kotlin only apply to the externally visible API of a class, such as public, protected, and internal members. Parameters of private methods are not subject to the “in” or “out” position rules. The variance rules are in place to protect a class from misuse by external clients and do not affect the implementation of the class itself.
In this case, the Herd class can safely be made covariant on T because the leadAnimal property has been made private. The private visibility means that the property is not accessible from external clients, so the variance rules for the public API do not apply.
Contravariance: reversed subtyping relation
Contravariance is the opposite of covariance and it can be understood as a mirror image of covariance. When a class is contravariant, the subtyping relationship between its type arguments is the reverse of the subtyping relationship between the classes themselves.
To illustrate this concept, let’s consider the example of the Comparator interface. This interface has a single method called compare, which takes two objects and compares them:
Kotlin
interfaceComparator<inT> {funcompare(e1: T, e2: T): Int { ... }}
In this case, you’ll notice that the compare method only consumes values of type T. This means that the type parameter T is used in “in” positions only, indicating that it is a contravariant type. To indicate contravariance, the “in” keyword is placed before the declaration of T.
A comparator defined for values of a certain type can, of course, compare the values of any subtype of that type. For example, if you have a Comparator, you can use it to compare values of any specific type.
Kotlin
val anyComparator = Comparator<Any> { e1, e2 -> e1.hashCode() - e2.hashCode() }val strings: List<String> = listOf("abc","xyz")strings.sortedWith(anyComparator) // You can use the comparator for any objects to compare specific objects, such as strings.
Here, the sortedWith function expects a Comparator (a comparator that can compare strings), and it’s safe to pass one that can compare more general types. If you need to perform comparisons on objects of a certain type, you can use a comparator that handles either that type or any of its supertypes. This means Comparator<Any> is a subtype of Comparator<String>, where Any is a supertype of String. The subtyping relation between comparators for two different types goes in the opposite direction of the subtyping relation between those types.
What is contravariance?
A class that is contravariant on the type parameter is a generic class (let’s consider Consumer<T> as an example) for which the following holds: Consumer<A> is a subtype of Consumer<B> if B is a subtype of A. The type arguments A and B changed places, so we say the subtyping is reversed. For example, Consumer<Animal> is a subtype of Consumer<Cat>.
In simple words, contravariance in Kotlin means that the subtyping relationship between two generic types is reversed compared to the normal inheritance hierarchy. If B is a subtype of A, then a generic class or interface that is contravariant on its type parameter T will have the relationship ClassName<A> is a subtype of ClassName<B>.
For a covariant type Producer, the subtyping is preserved, but for a contravariant type Consumer, the subtyping is reversed
Here, we see the difference between the subtyping relation for classes that are covariant and contravariant on a type parameter. You can see that for the Producer class, the subtyping relation replicates the subtyping relation for its type arguments, whereas for the Consumer class, the relation is reversed.
The “in” keyword means values of the corresponding type are passed in to methods of this class and consumed by those methods. Similar to the covariant case, constraining use of the type parameter leads to the specific subtyping relation. The “in” keyword on the type parameter T means the subtyping is reversed and T can be used only in “in” positions.
Covariance and Contravariance in Kotlin’s Function Types
In Kotlin, a class or interface can be covariant on one type parameter and contravariant on another. One of the classic examples of this is the Function interface. Let’s take a look at the declaration of the Function1 interface, which represents a one-parameter function:
To make the notation more readable, Kotlin provides an alternative syntax (P) -> R to represent Function1<P, R>. In this syntax, you’ll notice that P (the parameter type) is used only in the in position and is marked with the in keyword, while R (the return type) is used only in the out position and is marked with the out keyword.
This means that the subtyping relationship for the function type is reversed for the first type argument (P) and preserved for the second type argument (R).
For example, let’s say you have a higher-order function called enumerateCats that accepts a lambda function taking a Cat parameter and returning a Number:
Kotlin
funenumerateCats(f: (Cat) -> Number) { ... }
Now, suppose you have a function called getIndex defined in the Animal class that returns an Int. You can pass Animal::getIndex as an argument to enumerateCats:
Kotlin
funAnimal.getIndex(): Int = ...enumerateCats(Animal::getIndex) // This code is legal in Kotlin. Animal is a supertype of Cat, and Int is a subtype of Number
In this case, the Animal::getIndex function is accepted because Animal is a supertype of Cat, and Int is a subtype of Number, the function type’s subtyping relationship allows it.
The function (T) -> R is contravariant on its argument and covariant on its return type
This illustration demonstrates how subtyping works for function types. The arrows indicate the subtyping relationship.
Use-site variance: specifying variance for type occurrences
To understand use-site variance better, you first need to understand declaration-site variance. In Kotlin, the ability to specify variance modifiers on class declarations provides convenience and consistency because these modifiers apply to all places where the class is used. This concept is known as a declaration-site variance.
Declaration-site variance in Kotlin is achieved by using variance modifiers on type parameters when defining a class. As you already knows there are two main variance modifiers:
out (covariant): Denoted by the out keyword, it allows the type parameter to be used as a return type or read-only property. It specifies that the type parameter can only occur in the “out” position, meaning it can only be returned from functions or accessed in a read-only manner.
in (contravariant): Denoted by the in keyword, it allows the type parameter to be used as a parameter type. It specifies that the type parameter can only occur in the “in” position, meaning it can only be passed as a parameter to functions.
By specifying these variance modifiers on type parameters, you define the variance behavior of the class, and it remains consistent across all usages of the class.
On the other hand, Java handles variance differently through use-site variance. In Java, each usage of a type with a type parameter can specify whether the type parameter can be replaced with its subtypes or supertypes using wildcard types (? extends and ? super). This means that at each usage point of the type, you can decide the variance behavior.
It’s important to note that while Kotlin supports declaration-site variance with the out and in modifiers, it also provides a certain level of use-site variance through the out and in projection syntax (out T and in T). These projections allow you to control the variance behavior in specific usage points within the code.
Declaration-site variance in Kotlin Vs. Java wildcards
In Kotlin, declaration-site variance allows for more concise code because variance modifiers are specified once on the declaration of a class or interface. This means that clients of the class or interface don’t have to think about the variance modifiers. The convenience of declaration-site variance is that the variance behavior is determined at the point of declaration and remains consistent throughout the codebase.
On the other hand, in Java, wildcards are used to handle variance at the use site. To create APIs that behave according to users’ expectations, the library writer has to use wildcards extensively. For example, in the Java 8 standard library, wildcards are used on every use of the Function interface. This can lead to code like Function<? super T, ? extends R> in method signatures.
To illustrate the declaration of the map method in the Stream interface in Java :
In the Java code, wildcards are used in the declaration of the map method to handle the variance of the function argument. This can make the code less readable and more cumbersome, especially when dealing with complex type hierarchies.
In contrast, the Kotlin code uses declaration-site variance, specifying the variance once on the declaration makes the code much more concise and elegant.
BTW, How does use-site variance work in Kotlin?
Kotlin supports use-site variance, you can specify variance at the use site, which means you can indicate the variance for a specific occurrence of a type parameter, even if it can’t be declared as covariant or contravariant in the class declaration. Let’s break down the concepts and see how use-site works.
In Kotlin, many interfaces, like MutableList, are not covariant or contravariant by default because they can both produce and consume values of the types specified by their type parameters. However, in certain situations, a variable of that type may be used only as a producer or only as a consumer.
Consider the function copyData that copies elements from one collection to another:
Kotlin
fun <T> copyData(source: MutableList<T>, destination: MutableList<T>) {for (item in source) { destination.add(item) }}
In this function, both the source and destination collections have an invariant type. However, the source collection is only used for reading, and the destination collection is only used for writing. In this case, the element types of the collections don’t need to match exactly.
To make this function work with lists of different types, you can introduce a second generic parameter:
Kotlin
fun <T : R, R> copyData(source: MutableList<T>, destination: MutableList<R>) {for (item in source) { destination.add(item) }}
In this modified version, you declare two generic parameters representing the element types in the source and destination lists. The source element type (T) should be a subtype of the elements in the destination list (R).
However, Kotlin provides a more elegant way to express this using use-site variance. If the implementation of a function only calls methods that have the type parameter in the “out” position (as a producer) or only in the “in” position (as a consumer), you can add variance modifiers to the particular usages of the type parameter in the function definition.
For example, you can modify the copyData function as follows:
Kotlin
fun <T> copyData(source: MutableList<outT>, destination: MutableList<T>) {for (item in source) { destination.add(item) }}
In this version, you specify the out modifier for the source parameter, which means it’s a projected (restricted) MutableList. You can only call methods that return the generic type parameter (T) or use it in the “out” position. The compiler prohibits calling methods where the type parameter is used as an argument (“in” position).
When using use-site variance in Kotlin, there are limitations on the methods that can be called on a projected type. If you are using a projected type, you may not be able to call certain methods that require the type parameter to be used as an argument (“in” position) :
Kotlin
val list: MutableList<outNumber> = ..list.add(42) // Error: Out-projected type 'MutableList<out Number>' prohibits the use of 'fun add(element: E): Boolean'
Here, list is declared as a MutableList<out Number>, which is an out-projected type. The out projection restricts the type parameter Number to only be used in the “out” position, meaning it can only be used as a return type or read from. You cannot call the add method because it requires the type parameter to be used as an argument (“in” position).
If you need to call methods that are prohibited by the projection, you should use a regular type instead of a projection. In this case, you can use MutableList<Number> instead of MutableList<out Number>. By using the regular type, you can access all the methods available for that type.
Regarding the concept of using the in modifier, it indicates that in a particular location, the corresponding value acts as a consumer, and the type parameter can be substituted with any of its supertypes. This is similar to the contravariant position in Java’s bounded wildcards.
For example, the copyData function can be rewritten using an in-projection:
Kotlin
fun <T> copyData(source: MutableList<T>, destination: MutableList<inT>) {for (item in source) { destination.add(item) }}
In this version, the destination parameter is projected with the in modifier, indicating that it can consume elements of type T or any of its supertypes. This allows you to copy elements from the source list to a destination list with a broader type.
It’s important to note that use-site variance declarations in Kotlin correspond directly to Java’s bounded wildcards. MutableList<out T> in Kotlin is equivalent to MutableList<? extends T> in Java, while the in-projected MutableList<in T> corresponds to Java’s MutableList<? super T>.
Use-site projections in Kotlin can help widen the range of acceptable types and provide more flexibility when working with generic types, without the need for separate covariant or contravariant interfaces.
Star projection: using * instead of a type argument
In Kotlin, star projection is a syntax that allows you to indicate that you have no information about a generic argument. It is represented by the asterisk (*) symbol. Let’s explore the semantics of star projections in more detail.
When you use star projection, such as List<*>, it means you have a list of elements of an unknown type. It’s important to note that MutableList<*> is not the same as MutableList<Any?>. The former represents a list that contains elements of a specific type, but you don’t know what type it is. You can’t put any values into the list because it may violate the expectations of the calling code. However, you can retrieve elements from the list because you know they will match the type Any?, which is the supertype of all Kotlin types.
Here’s an example to illustrate this:
Kotlin
val list: MutableList<Any?> = mutableListOf('a', 1, "qwe")val chars = mutableListOf('a', 'b', 'c')val unknownElements: MutableList<*> = if (Random().nextBoolean()) list else charsunknownElements.add(42) // Error: Adding elements to a MutableList<*> is not allowedprintln(unknownElements.first()) // You can retrieve elements from unknownElements
In this example, unknownElements can be either list or chars based on a random condition. You can’t add any values to unknownElements because its type is unknown, but you can retrieve elements from it using the first() function.
Kotlin
unknownElements.add(42)// Error: Out-projected type 'MutableList<*>' prohibits//the use of 'fun add(element: E): Boolean'
The term “out-projected type” refers to the fact that MutableList<*> is projected to act as MutableList<out Any?>. It means you can safely get elements of type Any? from the list but cannot put elements into it.
For contravariant type parameters, like Consumer<in T>, a star projection is equivalent to <in Nothing>. In this case, you can’t call any methods that have T in the signature on a star projection because you don’t know exactly what it can consume. This is similar to Java’s wildcards (MyType<?> in Java corresponds to MyType<*> in Kotlin).
You can use star projections when the specific information about type arguments is not important. For example, if you only need to read the data from a list or use methods that produce values without caring about their specific types. Here’s an example of a function that takes List<*> as a parameter:
In this case, the printFirst function only reads the first element of the list and doesn’t care about its specific type. Alternatively, you can introduce a generic type parameter if you need more control over the type:
Kotlin
fun <T> printFirst(list: List<T>) {if (list.isNotEmpty()) {println(list.first()) }}
The syntax with star projection is more concise, but it works only when you don’t need to access the exact value of the generic type parameter.
Now let’s consider an example using a type with a star projection and common traps that you may encounter. Suppose you want to validate user input using an interface called FieldValidator. It has a type parameter declared as contravariant (in T). You also have two validators for String and Int inputs.
If you want to store all validators in the same container and retrieve the right validator based on the input type, you might try using a map. However, using FieldValidator<*> as the value type in the map can lead to difficulties. You won’t be able to validate a string with a validator of type FieldValidator<*> because the compiler doesn’t know the specific type of the validator.
Kotlin
val validators = mutableMapOf<KClass<*>, FieldValidator<*>>()validators[String::class] = DefaultStringValidatorvalidators[Int::class] = DefaultIntValidatorvalidators[String::class]!!.validate("") // Error: Cannot call validate() on FieldValidator<*>
In this case, you will encounter a similar error as before, indicating that it’s unsafe to call a method with the type parameter on a star projection. One way to work around this is by explicitly casting the validator to the desired type, but this is not recommended as it is not type-safe.
Kotlin
val stringValidator = validators[String::class] as FieldValidator<String>println(stringValidator.validate("")) // Output: false
This code compiles, but it’s not safe because the cast is unchecked and may fail at runtime if the generic type information is erased.
A safer approach is to encapsulate the access to the map and provide type-safe methods for registration and retrieval. This ensures that only the correct validators can be registered and retrieved. Here’s an example using an object called Validators:
In this example, the Validators object controls all access to the map, ensuring that only correct validators can be registered and retrieved. The code emits a warning about the unchecked cast, but the guarantees provided by the Validators object make sure that no incorrect use can occur.
This pattern of encapsulating unsafe code in a separate place helps prevent misuse and makes the usage of a container safe. It’s worth noting that this pattern is not specific to Kotlin and can be applied in Java as well.
Conclusion
Kotlin generics and variance are powerful tools that enhance type safety and code reusability. Understanding these concepts enables developers to write generic code that can be adapted to different types and relationships between them. By mastering generics and variance, you can build more flexible and robust applications.
In this blog post, we covered the basics of Kotlin generics, explained variance with examples, explored variance annotations, wildcards, type projections, and discussed additional topics such as reified type parameters and generic constraints. With this knowledge, you are well-equipped to utilize generics effectively in your Kotlin projects.
In object-oriented programming, inheritance is a fundamental concept that allows a class to inherit properties and behaviors from its parent class. However, inheritance has its limitations, and sometimes an alternative approach is needed. Kotlin provides native support for the delegation pattern, which is a powerful alternative to implementation inheritance. In this article, we will explore the delegation pattern in Kotlin and its various aspects.
Overview of the Delegation Pattern
The delegation pattern is a design pattern where an object delegates some or all of its responsibilities to another object. Instead of inheriting behavior, an object maintains a reference to another object and forwards method calls to it. This promotes composition over inheritance and provides greater flexibility in reusing and combining behaviors from different objects.
In Kotlin, the delegation pattern is built into the language, making it easy and convenient to implement. With the by keyword, Kotlin allows a class to implement an interface by delegating all of its public members to a specified object. Let’s dive into the details and see how it works.
Basic Usage of Delegation in Kotlin
To understand the basic usage of delegation in Kotlin, let’s consider a simple example. Assume we have an interface called Base with a single function print():
Kotlin
interfaceBase {funprint()}
Next, we define a class BaseImpl that implements the Base interface. It has a constructor parameter x of type Int and provides an implementation for the print() function:
Kotlin
classBaseImpl(val x: Int) : Base {overridefunprint() {println(x) }}
Now, we want to create a class called Derived that also implements the Base interface. Instead of implementing the print() function directly, we can delegate it to an instance of the Base interface. We achieve this by using the by keyword followed by the object reference in the class declaration:
Kotlin
classDerived(b: Base) : Basebyb
In this example, the by clause in the class declaration indicates that b will be stored internally in objects of Derived, and the compiler will generate all the methods of Base that forward to b. This means that the print() function in Derived will be automatically delegated to the print() function of the b object.
To see the delegation in action, let’s create an instance of BaseImpl with a value of 10 and pass it to the Derived class. Then, we can call the print() function on the Derived object:
When we execute the print() function on the Derived object, it internally delegates the call to the BaseImpl object (b), and thus it prints the value 10.
Overriding Methods in DelegationPattern
In Kotlin, when a class implements an interface by delegation, it can also override methods provided by the delegate object. This allows for customization and adding additional behavior specific to the implementing class.
Let’s extend our previous example to understand method overriding in the delegation. Assume we have an interface Base with two functions: printMessage() and printMessageLine():
In this example, the printMessage() function in the Derived class overrides the implementation provided by the delegate object b. When we call printMessage() on an instance of Derived, it will print “softAai Apps” instead of the original implementation.
To test the overridden behavior, we can modify the main() function as follows:
When we call the printMessage() function on the Derived object, it invokes the overridden implementation in the Derived class, and it prints “softAai Apps” instead of 10. However, the printMessageLine() function is not overridden in the Derived class, so it delegates the call to the BaseImpl object, which prints the original value 10 followed by a new line.
Property Delegationin Delegation Pattern
In addition to method delegation, Kotlin also supports property delegation. This allows a class to delegate the implementation of properties to another object. Let’s understand how it works.
Assume we have an interface Base with a read-only property message:
Kotlin
interfaceBase {val message: String}
We modify the BaseImpl class to implement the Base interface with the message property:
Kotlin
classBaseImpl(val x: Int) : Base {overrideval message: String = "BaseImpl: x = $x"}
Now, let’s update the Derived class to delegate the Base interface and override the message property:
In this example, the Derived class delegates the implementation of the Base interface to the b object. However, it overrides the message property and provides its own implementation.
To see the property delegation in action, we can modify the main() function as follows:
Kotlin
funmain() {val b = BaseImpl(10)val derived = Derived(b)println(derived.message) // Output: Message of Derived}
When we access the message property of the Derived object, it returns the overridden value “Message of Derived” instead of the one in the delegate object b.
Advantages of the Delegation Pattern in Kotlin
Code Reusability: Delegation allows for code reuse by delegating responsibilities to another object. This promotes composition over inheritance and allows for the flexible reuse of behavior.
Separation of Concerns: Delegation helps in separating different concerns by assigning specific responsibilities to different objects. This leads to a more modular and maintainable codebase.
Flexibility: Delegation allows for dynamic behavior modification at runtime. By delegating to different objects, you can easily switch or modify behavior as needed without changing the implementing class.
Easy Composition: Delegation makes it straightforward to combine and compose multiple behaviors. Objects can be combined by delegating to multiple objects, allowing for flexible composition of functionalities.
Code Readability: Delegation improves code readability by clearly specifying which object is responsible for which behavior. It enhances code understanding and reduces complexity.
Disadvantages of the Delegation Pattern in Kotlin
Performance Overhead: Delegation adds a level of indirection, which can introduce a slight performance overhead. Each method call needs to be forwarded to the delegate object, which can impact performance in performance-critical scenarios.
Increased Complexity: Delegation can introduce additional complexity, especially when multiple levels of delegation are involved. Understanding the flow of method calls and responsibilities might require careful analysis.
Potential Code Duplication: If multiple classes implement the same interface using delegation, there is a possibility of code duplication. Each class might need to provide its own implementation, even if the behavior is similar across implementations.
Limited Access to Internal State: When using delegation, accessing the internal state or members of the delegate object might become more complex. If the delegate object exposes limited or no access to its internal state, it can limit the flexibility of the implementing class.
Learning Curve: Understanding and utilizing the delegation pattern might require some learning and understanding of the concept. Developers who are not familiar with delegation might require additional effort to grasp the concept and its best practices.
Conclusion
The delegation pattern in Kotlin is a powerful alternative to implementation inheritance. It allows a class to implement an interface by delegating the responsibilities to another object. Kotlin’s by keyword makes it easy to implement delegation without boilerplate code.
In this article, we covered the basics of delegation pattern, including how to delegate methods and properties, and how to override them in the implementing class. We also discussed the limitation of overridden methods not being called from within the delegate object.
By leveraging the delegation pattern, you can achieve code reuse, composition, and flexibility in your Kotlin applications. Understanding and utilizing this pattern can lead to cleaner and more maintainable code.
Remember to consider the delegation pattern when designing your classes and to evaluate whether it provides a better solution compared to traditional implementation inheritance.
Performance is an important element in constructing solid and proficient software applications. Kotlin, a cutting-edge and multifunctional programming language, offers multiple language structures for developers to take advantage of, each with its own performance-related properties. In this blog post, we will go in-depth into the execution efficiency impact of regular classes, sealed classes, and sealed interfaces in Kotlin.
Regular Classes
Regular classes in Kotlin provide the most basic form of class definition. They are open by default, meaning that they can be inherited and extended by other classes. Regular classes allow for polymorphism, encapsulation, and inheritance. In terms of performance, regular classes generally have a minimal impact on runtime efficiency. When instantiating regular classes, there is a slight overhead associated with memory allocation and object initialization. However, this overhead is typically negligible and doesn’t significantly impact performance unless you are creating an excessive number of instances. The method dispatch mechanism used in regular classes is dynamic, which incurs a small runtime cost when invoking methods. Nevertheless, modern virtual machine optimizations often mitigate this performance impact, making regular classes a reliable choice for most scenarios.
Sealed Classes
Sealed classes in Kotlin are used to represent restricted class hierarchies. They provide a way to define a limited set of subclasses that can inherit from them. Sealed classes are declared with the sealed modifier and are typically used in scenarios where you have a predefined set of possible types.
In terms of performance, sealed classes offer a slight trade-off compared to regular classes. The restricted class hierarchy allows the compiler to perform exhaustive when expression checks, which results in more efficient code generation. The when expression, when used with sealed classes, can ensure that all possible subclasses are handled, eliminating the need for a default case. This static analysis leads to improved performance since the compiler can optimize the code based on the exhaustive knowledge of the subclasses. Consequently, sealed classes can offer better runtime efficiency compared to regular classes when used appropriately.
Sealed Interfaces
Sealed interfaces, introduced in Kotlin 1.5, extend the concept of sealed classes to interfaces. They allow developers to define a sealed set of possible implementations for an interface. Sealed interfaces are declared using the sealed modifier and provide a way to restrict the types that can implement them.
From a performance standpoint, sealed interfaces share similar characteristics with sealed classes. The restricted set of implementations allows for exhaustive checks, enabling the compiler to optimize the code by eliminating unnecessary branching and providing improved runtime efficiency. The usage of sealed interfaces can lead to more predictable performance compared to regular interfaces, especially in scenarios where you need to handle a limited number of implementations.
Conclusion
When constructing applications in Kotlin, regular classes, sealed classes, and sealed interfaces provide varied performance benefits depending on the specific utilization. Regular classes are strong, providing minimal performance effects. Sealed classes and sealed interfaces, conversely, introduce a bound class hierarchy or implementation group, permitting more competent code generation and enhanced runtime productivity.
To determine the best construction for the job, it is critical to take into consideration the design prerequisites and balance between agility and performance. Regular classes are a suitable solution for a wide range of circumstances, whereas sealed classes and sealed interfaces are of greater use when there is a minimal number of known subclasses or executions.
It is imperative to understand that optimizing performance must be carried out with actual profiling and testing to determine issues with accuracy. By understanding the performance properties of regular classes, sealed classes, and sealed interfaces in Kotlin, you can make sound decisions to generate efficient and high-performing applications.
In today’s mobile app development landscape, implementing a smooth and secure authentication process is essential for user engagement and retention. One popular authentication method is Google Sign-In, which allows users to sign in to your app using their Google credentials. In this blog, we will explore how to integrate Google Sign-In seamlessly into your Jetpack Compose UI for Android projects. By following the steps outlined below, you’ll be able to enhance the user experience and streamline the authentication process.
Prerequisites
Before diving into the implementation, ensure that you have a basic understanding of Jetpack Compose and Android development. Familiarity with Kotlin is also beneficial. Additionally, make sure you have set up a project in the Google Cloud Platform (GCP) and obtained the necessary credentials and permissions.
Step 1: Google Sign-In APIAdding the Dependency
The first step is to add the required dependency to your project’s build.gradle file. By including the ‘play-services-auth’ library, you gain access to the Google Sign-In API. Make sure to sync the project after adding the dependency to ensure it is correctly imported.
The version number, in this case, is 19.2.0, which specifies the specific version of the play-services-auth library you want to include.
Step 2: Creating the GoogleUserModel
To handle the user data obtained from the Google Sign-In process, we need to create a data class called ‘GoogleUserModel’. This class will store the relevant user information, such as their name and email address. By encapsulating this data in a model class, we can easily pass it between different components of our app.
Kotlin
dataclassGoogleUserModel(val name: String?, val email: String?)
Step 3: Implementing the AuthScreen
The ‘AuthScreen’ composable function serves as the entry point for our authentication flow. It interacts with the ‘GoogleSignInViewModel’ and handles the UI components required for the sign-in process. We will create a smooth navigation flow that allows users to initiate the Google Sign-In procedure.
In the ‘AuthView’ composable function, we will define the visual layout of our authentication screen. This includes displaying a loading indicator, the Google Sign-In button, and handling potential error messages. By providing a user-friendly interface, we enhance the overall user experience.
The AuthScreen function is a Composable function that represents the authentication screen. It takes a NavController as a parameter, which will be used for navigating to different screens.
Inside the AuthScreen function, an instance of GoogleSignInViewModel is created using the viewModel function. This ViewModel is responsible for managing the authentication state related to Google Sign-In.
The userState variable collects the state of the googleUser property from the GoogleSignInViewModel as a Composable state. This allows the UI to update reactively whenever the user state changes.
The AuthView composable function is called to display the UI components of the authentication screen. It takes a lambda function onClick and the mGoogleSignInViewModel as parameters.
After calling the AuthView composable, there is a check to see if the user’s name is not empty. If it’s not empty, a LaunchedEffect is used to perform an action. It hides the loading state, converts the user object to JSON using MoshiUtils, and navigates to the settings screen, passing the user data along.
The AuthView composable function is responsible for rendering the UI of the authentication screen. It uses the Scaffold composable to set up the basic layout structure.
Inside the AuthView composable, there’s a Column that contains various UI components of the authentication screen, such as an Image, a sign-in button (SignInGoogleButton), and a Text displaying the app’s slogan.
The when expression is used to handle different states. In this case, when the loading state of the mGoogleSignInViewModel is true, it displays an error message (AUTH_ERROR_MSG) using the Text composable.
Finally, there are @Preview annotations for previewing the AuthView composable in different UI modes (day mode and night mode).
Step 5: Managing Authentication with GoogleSignInViewModel
The ‘GoogleSignInViewModel’ class plays a crucial role in managing the authentication state and communicating with the Google Sign-In API. Depending on your preference, you can choose to use LiveData or StateFlow to update the user’s sign-in status and handle loading and error states. This ViewModel acts as a bridge between the UI and the underlying authentication logic.
Kotlin
/* * It contains commented code I think it will helpful when implement logout functionality * in future thats why kept as it is here. * */classGoogleSignInViewModel : ViewModel() {privatevar _userState = MutableStateFlow(GoogleUserModel("", ""))val googleUser = _userState.asStateFlow()privatevar _loadingState = MutableStateFlow(false)val loading = _loadingState.asStateFlow()privateval _errorStateFlow = MutableStateFlow(false)val errorStateFlow = _errorStateFlow.asStateFlow()/* init { checkSignedInUser(application.applicationContext) }*/funfetchSignInUser(email: String?, name: String?) { _loadingState.value = true viewModelScope.launch { _userState.value =GoogleUserModel( email = email, name = name, ) } _loadingState.value = false }/* private fun checkSignedInUser(applicationContext: Context) { _loadingState.value = true val gsa = GoogleSignIn.getLastSignedInAccount(applicationContext) if (gsa != null) { _userState.value = GoogleUserModel( email = gsa.email, name = gsa.displayName, ) } _loadingState.value = false }*/funhideLoading() { _loadingState.value = false }funshowLoading() { _loadingState.value = true }funisError(isError: Boolean) { _errorStateFlow.value = isError }}/*class GoogleSignInViewModelFactory( private val application: Application) : ViewModelProvider.Factory { override fun <T : ViewModel> create(modelClass: Class<T>): T { @Suppress("UNCHECKED_CAST") if (modelClass.isAssignableFrom(GoogleSignInViewModel::class.java)) { return GoogleSignInViewModel(application) as T } throw IllegalArgumentException("Unknown ViewModel class") }}*/
Conclusion
By following this tutorial, you have learned how to seamlessly integrate Google Sign-In into your Jetpack Compose UI for Android. The integration allows users to sign in to your app using their Google credentials, enhancing the user experience and streamlining the authentication process. By leveraging the power of Jetpack Compose and the Google Sign-In API, you can build secure and user-friendly apps that cater to the modern authentication needs of your users.
Generics in Kotlin provide a powerful way to write reusable and type-safe code. However, on the Java Virtual Machine (JVM), generics are subject to type erasure, meaning that the specific type arguments used for instances of a generic class are not preserved at runtime. This limitation has implications for runtime type checks and casts. But fear not! Kotlin provides a solution: reified type parameters. In this blog post, we’ll delve into the world of reified type parameters and explore how they enable us to access and manipulate type information at runtime.
Understanding Type Erasure in Kotlin Generics
Generics in Kotlin are implemented using type erasure on the JVM. This means that the specific type arguments used for instances of a generic class are not preserved at runtime. In this section, we’ll explore the practical consequences of type erasure in Kotlin and learn how you can overcome its limitations by declaring a function as inline.
By declaring a function as inline, you can prevent the erasure of its type arguments. In Kotlin, this is achieved by using reified type parameters. Reified type parameters allow you to access and manipulate the actual type information of the generic arguments at runtime.
In simpler terms, when you mark a function as inline with a reified type parameter, you can retrieve and work with the specific types used as arguments when calling that function.
Now, let’s look at some examples to better understand the concept of reified type parameters and their usefulness.
Generics at runtime: type checks and casts
Generics in Kotlin, similar to Java, are erased at runtime. This means that the type arguments used to create an instance of a generic class are not preserved at runtime. For example, if you create a List<String> and put strings into it, at runtime, you will only see it as a List. You won’t be able to identify the specific type of elements the list was intended to contain. However, the compiler ensures that only elements of the correct type are stored in the list based on the type arguments provided during compilation.
At runtime, you don’t know whether list1 and list2 were declared as lists of strings or integers. Each of them is just a List
Even though the compiler recognizes list1 and list2 as distinct types, at execution time, they appear the same. However, you can generally rely on List<String> to contain only strings and List<Int> to contain only integers because the compiler knows the type arguments and enforces type safety. It is possible to deceive the compiler using type casts or Java raw types, but it requires a deliberate effort.
When it comes to checking the type information at runtime, the erased type information poses some limitations. You cannot directly check if a value is an instance of a specific erased type with type arguments. For example, the following code won’t compile:
Kotlin
if (valueis List<String>) { ... } // Error: Cannot check for instance of erased type
Even though you can determine at runtime that value is a List, you cannot determine whether it’s a list of strings, persons, or some other type. That information is erased.
Note that erasing generic type information has its benefits: the overall amount of memory used by your application is smaller; because less type information needs to be saved in memory.
As we stated earlier, Kotlin doesn’t let you use a generic type without specifying type arguments. Thus you may wonder how to check that the value is a list, rather than a set or another object
To check if a value is a List without specifying its type argument, you can use the star projection syntax:
Kotlin
if (valueis List<*>) { ... }
By using List<*>, you’re essentially treating it as a type with unknown type arguments, similar to Java’s List<?>. In this case, you can determine that the value is a List, but you won’t have any information about its element type.
Note that you can still use normal generic types in as and as? casts. However, these casts won’t fail if the class has the correct base type but a wrong type argument because the type argument is not known at runtime. The compiler will emit an “unchecked cast” warning for such casts. It’s important to understand that it’s only a warning, and you can still use the value as if it had the necessary type.
Here’s an example of using as? cast with a warning:
Kotlin
funprintSum(c: Collection<*>) {val intList = c as? List<Int> // Warning here. Unchecked cast: List<*> to List<Int> ?: throwIllegalArgumentException("List is expected")println(intList.sum())}
This code defines a function called printSum that takes a collection (c) as a parameter. Within the function, a cast is performed using the as? operator, attempting to cast c as a List<Int>. If the cast succeeds, the resulting value is assigned to the variable intList. However, if the cast fails (i.e., c is not a List<Int>), the as? operator returns null, and the code throws an IllegalArgumentException with the message “List is expected”. Finally, the sum of the integers in intList is printed.
Let’s see how this function behaves when called with different inputs:
Kotlin
printSum(listOf(1, 2, 3)) // o/p - 6
When called with a list of integers, the function works as expected. The sum of the integers is calculated and printed.
Now let’s change the input to a set:
Kotlin
printSum(setOf(1, 2, 3)) // o/p - IllegalArgumentException: List is expected
When called with a set of integers, the function throws an IllegalArgumentException because the input is not a List. The as? cast fails, resulting in a null value, and the IllegalArgumentException is thrown.
Now we pass String as input:
Kotlin
printSum(listOf("a", "b", "c")) // o/p - ClassCastException: String cannot be cast to Number
When called with a list of strings, the function successfully casts the list to a List<Int>, despite the wrong type argument. However, during the execution of intList.sum(), a ClassCastException occurs. This happens because the function tries to treat the strings as numbers, resulting in a runtime error.
The code examples above demonstrate that type casts (as and as?) in Kotlin may lead to runtime exceptions if the casted type and the actual type are incompatible. The compiler emits an “unchecked cast” warning to notify you about this potential risk. It’s important to understand the meaning of these warnings and be cautious when using type casts.
The code snippet below shows an alternative approach using an is check:
Kotlin
funprintSum(c: Collection<*>) {val intList = c as? List<Int> // Warning here. Unchecked cast: List<*> to List<Int> ?: throwIllegalArgumentException("List is expected")println(intList.sum())}
In this example, the printSum function takes a Collection<Int> as a parameter. Using the is operator, it checks if c is a List<Int>. If the check succeeds, the sum of the integers in the list is printed. This approach is possible because the compiler knows at compile time that c is a collection of integers.
So, Kotlin’s compiler helps you identify potentially dangerous type checks (forbidding is checks) and emits warnings for type casts (as and as?) that may cause issues at runtime. Understanding these warnings and knowing which operations are safe is essential when working with type casts in Kotlin.
Power of Reified Type Parameters in Inline Functions
In Kotlin, generics are typically erased at runtime, which means that you can’t determine the type arguments used when an instance of a generic class is created or when a generic function is called. However, there is an exception to this limitation when it comes to inline functions. By marking a function as inline, you can make its type parameters reified, which allows you to refer to the actual type arguments at runtime.
Let’s take a look at an example to illustrate this. Suppose we have a generic function called isA that checks if a given value is an instance of a specific type T:
Kotlin
fun <T> isA(value: Any) = valueis T
If we try to call this function with a specific type argument, like isA<String>("abc"), we would encounter an error because the type argument T is erased at runtime.
However, if we modify the function to beinline and mark the type parameter as reified, like this:
Kotlin
inlinefun <reifiedT> isA(value: Any) = valueis T
Now we can call isA<String>("abc") and isA<String>(123) without any errors. The reified type parameter allows us to check whether the value is an instance of T at runtime. In the first example, the output will be true because "abc" is indeed a String, while in the second example, the output will be false because 123 is not a String.
Another practical use of reified type parameters is demonstrated by the filterIsInstance function from the Kotlin standard library. This function takes a collection and selects instances of a specified class, returning only those instances. For example:
Kotlin
val items = listOf("one", 2, "three")println(items.filterIsInstance<String>())
In this case, we specify <String> as the type argument for filterIsInstance, indicating that we are interested in selecting only strings from the items list. The function’s return type is automatically inferred as List<String>, and the output will be [one, three].
Here’s a simplified version of the filterIsInstance function’s declaration from the Kotlin standard library:
Before coming to this code explanation, have you ever thought, Why reification works for inline functions only? How does this work? Why are you allowed to write element is T in an inline function but not in a regular class or function? Let’s see the answers to all these questions:
Reification works for inline functions because the compiler inserts the bytecode implementing the inline function directly at every place where it is called. This means that the compiler knows the exact type used as the type argument in each specific call to the inline function.
When you call an inline function with a reified type parameter, the compiler can generate a bytecode that references the specific class used as the type argument for that particular call. For example, in the case of the filterIsInstance<String>() call, the generated code would be equivalent to:
Kotlin
for (element inthis) {if (element is String) { destination.add(element) }}
The generated bytecode references the specific String class, not a type parameter, so it is not affected by the type-argument erasure that occurs at runtime. This allows the reified type parameter to be used for type checks and other operations at runtime.
It’s important to note that inline functions with reified type parameters cannot be called from Java code. Regular inline functions are accessible to Java as regular functions, meaning they can be called but are not inlined. However, functions with reified type parameters require additional processing to substitute the type argument values into the bytecode, and therefore they must always be inlined. This makes it impossible to call them in a regular way, as Java code does not support this mechanism.
Also, one more thing to note is that an inline function can have multiple reified type parameters and can also have non-reified type parameters alongside the reified ones. It’s important to keep in mind that marking a function as inline does not necessarily provide performance benefits in all cases. If the function becomes large, it’s recommended to extract the code that doesn’t depend on reified type parameters into separate non-inline functions for better performance.
Practical use cases of reified type parameters
Reified type parameters can be especially useful when working with APIs that expect parameters of type java.lang.Class. Let\’s explore two examples to demonstrate how reified type parameters simplify such scenarios.
Example 1
ServiceLoader The ServiceLoader API from the JDK is an example of an API that takes a java.lang.Class representing an interface or abstract class and returns an instance of a service class implementing that interface. Traditionally, in Kotlin, you would use the following syntax to load a service:
Kotlin
val serviceImpl = ServiceLoader.load(Service::class.java)
However, using a function with a reified type parameter, we can make this code shorter and more readable:
Kotlin
val serviceImpl = loadService<Service>()
To define the loadService function, we use the inline modifier and a reified type parameter:
Kotlin
inlinefun <reifiedT> loadService(): T {return ServiceLoader.load(T::class.java)}
Here, T::class.java retrieves the java.lang.Class corresponding to the class specified as the type parameter, allowing us to use it as needed. This approach simplifies the code by specifying the class as a type argument, which is shorter and easier to read compared to ::class.java syntax.
Example 2
Simplifying startActivity in Android In Android development, when launching activities, instead of passing the class of the activity as a java.lang.Class, you can use a reified type parameter to make the code more concise. For instance:
With this inline function, you can start an activity by specifying the activity class as a type argument:
Kotlin
startActivity<DetailActivity>()
This simplifies the code by eliminating the need to pass the activity class as a java.lang.Class instance explicitly.
Reified type parameters allow us to work with class references directly, making the code more readable and concise. They are particularly useful in scenarios where APIs expect java.lang.Class parameters, such as ServiceLoader in Java or starting activities in Android.
Restrictions on Reified Type Parameters
Reified Type parameters in Kotlin have certain restrictions that you need to be aware of. Some of these restrictions are inherent to the concept itself, while others are determined by the implementation of Kotlin and may change in future Kotlin versions. Here’s a summary of how you can use reified type parameters and what you cannot do:
You can use a reified type parameter in the following ways:
Type checks and casts (is, !is, as, as?)
Reified type parameters can be used in type checks and casts. You can check if an object is of a specific type or perform a type cast using the reified type parameter. Here’s an example:
Kotlin
inlinefun <reifiedT> checkType(obj: Any) {if (obj is T) {println("Object is of type T") } else {println("Object is not of type T") }val castedObj = obj as? T// Perform operations with the casted object}
Kotlin reflection APIs (::class)
Reified type parameters can be used with Kotlin reflection APIs, such as ::class, to access runtime information about the type. It allows you to retrieve the KClass object representing the type parameter. Here’s an example:
Getting the corresponding java.lang.Class (::class.java)
Reified type parameters can also be used to obtain the corresponding java.lang.Class object of the type using the ::class.java syntax. This can be useful when interoperating with Java APIs that require Class objects. Here’s an example:
Using reified type parameter as a type argument when calling other functions
Reified type parameters can be used as type arguments when calling other functions. This allows you to propagate the type information to other functions without losing it due to type erasure. Here’s an example:
Kotlin
inlinefun <reifiedT> processList(list: List<T>) {// Process the list of type Tfor (item in list) {// ... }}funmain() {val myList = listOf("Hello", "World")processList<String>(myList)}
These examples demonstrate the various ways in which reified type parameters can be utilized in Kotlin, including type checks, reflection APIs, obtaining java.lang.Class, and passing the type information to other functions as type arguments.
However, there are certain things you cannot do with reified type parameters:
Creating new instances of the class specified as a type parameter
Reified type parameters cannot be used to create new instances of the class directly. You can only access the type information using reified type parameters. To create new instances, you would need to use other means such as reflection or factory methods. Here’s an example:
Kotlin
inlinefun <reifiedT> createInstance(): T {// Error: Cannot create an instance of the type parameter TreturnT()}
Calling methods on the companion object of the type parameter class
Reified type parameters cannot directly access the companion object of the type parameter class. However, you can access the class itself using T::class syntax. To call methods on the companion object, you would need to access it through the class reference. Here’s an example:
Kotlin
inlinefun <reifiedT> callCompanionMethod(): String {// Error: Cannot access the companion object of the type parameter Treturn T.Companion.someMethod()}
Using a non-reified type parameter as a type argument
When calling a function with a reified type parameter, you cannot use a non-reified type parameter as a type argument. Reified type parameters can only be used as type arguments themselves. Here’s an example:
Kotlin
inlinefun <reifiedT> reifiedFunction() {// Error: Non-reified type parameter cannot be used as a type argumentanotherFunction<T>()}fun <T> anotherFunction() {// ...}
Marking type parameters of classes, properties, or non-inline functions as reified
Reified type parameters can only be used in inline functions. You cannot mark type parameters of classes, properties, or non-inline functions as reified. Reified type parameters are limited to inline functions. Here’s an example:
Kotlin
classMyClass<T> { // Error: Type parameter cannot be marked as reified// ...}val <T> List<T>.property: T// Error: Type parameter cannot be marked as reifiedget() = TODO()fun <T> nonInlineFunction() { // Error: Type parameter cannot be marked as reified// ...}
These examples illustrate the restrictions on reified type parameters in Kotlin. By understanding these limitations, you can use reified type parameters effectively in inline functions while keeping in mind their specific usage scenarios.
Conclusion
Reified type parameters in Kotlin offer a powerful tool for overcoming the limitations of type erasure at runtime. By utilizing reified type parameters in inline functions, developers can access and manipulate precise type information, enabling type checks, casts, and interaction with reflection APIs. Understanding the benefits and restrictions of reified type parameters empowers Kotlin developers to write more expressive, type-safe, and concise code.
By embracing reified type parameters, Kotlin programmers can unleash the full potential of generics and enhance their runtime type-related operations. Start utilizing reified type parameters today and unlock a world of type-aware programming in Kotlin!
Kotlin, a modern and versatile programming language, offers various features to enhance developer productivity. One such powerful feature is function types, which enable you to treat functions as first-class citizens in your code. In this blog post, we will delve into function types in Kotlin, understand their types, explore their usage, and provide examples to solidify our understanding. So let’s dive in!
Recap: Higher-Order Functions
In Kotlin, a higher-order function is a function that can accept a lambda expression or a function reference as an argument or can return a lambda expression or a function reference. It allows functions to be treated as values and enables flexible and concise coding.
Let’s take the example of the filter function from the standard library, which takes a predicate function as an argument and is, therefore, a higher-order function:
Kotlin
list.filter { x > 0 }
Function types
In Kotlin, you can declare variables with function types. This means that the variables can hold references to functions. Let’s take a look at an example:
Kotlin
val sum: (Int, Int) -> Int = { x, y -> x + y } // Function that takes two Int parameters and returns an Int valueval action: () -> Unit = { println(42) } // Function that takes no arguments and doesn’t return a value
In this code, we have two variables: sum and action. The type of sum is a function that takes two Int parameters and returns an Int. The type of action is a function that takes no parameters and returns Unit, which represents a lack of meaningful value.
What are Function Types?
Function types allow you to treat functions as values. Just like any other variable, you can assign functions to variables, pass them as parameters to other functions, and even return them from functions. This feature provides flexibility and enables you to write more concise and expressive code.
Syntax
Function-type syntax in Kotlin
To declare a function type, you put the function parameter types in parentheses, followed by an arrow, and the return type of the function. In the above diagram, (Int, String) -> Unit specifies a function that takes Int and String parameters and returns a Unit.
The Unit type is used to indicate that a function doesn’t return a meaningful value. In regular function declarations, you can omit the Unit return type, but in function type declarations, it is always required. So, you can’t omit a Unit in this context.
Kotlin
val sum: (Int, Int) -> Int = { x, y -> x + y }
In the lambda expression { x, y -> x + y }, you might notice that the types of the parameters x and y are omitted. This is because the types are already specified in the function type declaration, so there’s no need to repeat them in the lambda itself.
You can also make the return type of a function type nullable by using the? symbol. For example:
Kotlin
var canReturnNull: (Int, Int) -> Int? = { null }
In this case, the function type (Int, Int) -> Int? represents a function that takes two Int parameters and returns an Int that can be nullable. This means the function can return either an Int value or null.
Furthermore, you can declare a nullable variable of a function type by enclosing the entire function type definition in parentheses and placing the question mark after the parentheses. For example:
Kotlin
var funOrNull: ((Int, Int) -> Int)? = null
Here, ((Int, Int) -> Int)? represents a nullable variable of a function type. The entire function type definition is enclosed in parentheses, and the question mark indicates that the variable itself is nullable.
It’s important to note the distinction between a function type with a nullable return type ((Int, Int) -> Int?) and a nullable variable of a function type (((Int, Int) -> Int)?). Omitting the parentheses will result in different meanings, so be cautious when specifying nullable function types.
Parameter names of function types
In Kotlin, you have the option to specify names for the parameters of a function type. This can improve the readability of your code and can be helpful for code completion in the IDE.
Here’s an example that demonstrates specifying parameter names in a function type:
In this code, the performRequest function takes two parameters: url of type String and callback of type (code: Int, content: String) -> Unit. The callback parameter is a function type that expects two parameters named code and content, both of type Int and String respectively. The function type represents a callback function that will be invoked when the request is completed.
When you call the performRequest function, you can provide a lambda expression as the argument for the callback parameter. The lambda can use any parameter names you prefer, regardless of the names specified in the function type declaration. For example:
Kotlin
val url = "https://blog.softaai.com"performRequest(url) { code, content ->// Code that uses the parameters 'code' and 'content'}performRequest(url) { code, page ->// Code that uses the parameters 'code' and 'page'}
In the above examples, we pass a lambda expression to the performRequest function. Inside the lambda, we can choose different names for the parameters (code and content in the first example, and code and page in the second example). These parameter names in the lambda expression do not need to match the names specified in the function type declaration.
Although the parameter names don’t affect type matching, using descriptive names can make your code more readable and understandable. Additionally, modern IDEs can utilize these parameter names for code completion, making it easier for you to write your code accurately.
Calling functions passed as arguments
In Kotlin, you can call functions that are passed as arguments to other functions. Let’s explore a couple of examples to understand how this works.
First, let’s consider the twoAndThree function, which takes another function as an argument and performs an arbitrary operation on the numbers 2 and 3:
Kotlin
funtwoAndThree(operation: (Int, Int) -> Int) {val result = operation(2, 3)println("The result is $result")}
In this example, the twoAndThree function accepts a function called operation, which has a function type (Int, Int) -> Int. This means the operation function takes two Int parameters and returns an Int. Inside the twoAndThree function, the operation function is called with arguments 2 and 3, and the result is printed.
To call the twoAndThree function and pass a function as an argument, you can use a lambda expression. For example:
Kotlin
twoAndThree { a, b -> a + b }
In this case, we pass a lambda expression that adds two numbers (a + b). The lambda matches the function type (Int, Int) -> Int because it takes two Int parameters and returns an Int. The result of the addition, 5, is printed by the twoAndThree function.
Similarly, you can pass a different lambda expression to achieve a different operation:
Kotlin
twoAndThree { a, b -> a * b }
Here, the lambda multiplies the two numbers (a * b), and the result, 6, is printed.
The syntax for calling a function passed as an argument is the same as calling a regular function. You use parentheses after the function name and provide the necessary arguments inside the parentheses.
Now, let’s consider another example: reimplementing the filter function from the standard library. The filter function takes a predicate as a parameter. The predicate is a function that takes a character and returns a Boolean result. The implementation checks whether each character satisfies the predicate and adds it to a StringBuilder if it does.
To reimplement the filter function for strings, let’s consider the following implementation:
In this implementation, the filter function is an extension function on the String class. It takes a predicate parameter, which is a function that takes a Char parameter and returns a Boolean.
Inside the function, a StringBuilder is created to store the filtered characters. The function iterates over each character of the string using the for loop and checks if the character satisfies the given predicate. If the predicate returns true for a character, it is appended to the StringBuilder.
Finally, the StringBuilder is converted to a string using the toString() function and returned as the result.
Here’s an example of how you can use the filter function:
Kotlin
println("softAai Apps".filter { it in'A'..'Z' })
In this case, the input string is "softAai Apps", and the predicate checks if each character is within the range from 'A' to 'Z'. The filtered result, which only contains the uppercase alphabetic characters, is printed as "AA".
The filter function implementation is straightforward. It enables you to filter characters from a string based on a given predicate, providing a more convenient and readable way to perform such operations.
By using higher-order functions and passing functions as arguments, you can create flexible and reusable code that can perform different operations based on the provided functions.
Default and null values for parameters with function types
When declaring a parameter of a function type, you can specify a default value for it. This can be useful when you want to provide a default behavior for the function if the caller doesn’t provide a specific implementation. Here’s an example:
Kotlin
fun <T> printCollection(collection: Collection<T>, transform: (T) -> String = { it.toString() }) {for (element in collection) {println(transform(element)) }}
In this example, the printCollection function takes a collection parameter of type Collection<T> and a transform parameter of function type (T) -> String. The transform parameter has a default value defined as a lambda expression { it.toString() }, which uses the toString() method to convert each element of the collection to a string.
You can call the printCollection function in different ways:
Kotlin
val numbers = listOf(1, 2, 3, 4, 5)// Omitting the transform parameter to use the default behaviorprintCollection(numbers)// Passing a lambda as the transform parameterprintCollection(numbers) { "Number: $it" }// Passing the transform parameter as a named argumentprintCollection(numbers, transform = { "Value: $it" })
In the first example, we omit the transform parameter, so the default behavior using toString() will be used to convert each element.
In the second example, we pass a lambda expression { "Number: $it" } as the transform parameter. This lambda defines a custom behavior to transform each element of the collection.
In the third example, we explicitly pass the transform parameter as a named argument, providing a different lambda expression { "Value: $it" } to customize the transformation.
Another option is to declare a parameter of a nullable function type. However, directly calling a function passed in such a parameter is not allowed because it could potentially lead to null pointer exceptions. To handle this, you can check for null explicitly or use the safe-call syntax callback?.invoke(). Here’s an example:
In this example, the performAction function takes a nullable function type parameter callback of type (() -> Unit)?. Inside the function, we can use the safe-call syntax callback?.invoke() to invoke the function only if it is not null.
Function Types with Generic Parameters
Kotlin allows you to define function types with generic parameters. This provides flexibility when working with functions that can operate on different types.
Kotlin
fun <T> processList(list: List<T>, operation: (T) -> Unit) {for (item in list) {operation(item) }}val numbers = listOf(1, 2, 3, 4, 5)processList(numbers) { println(it) } // Prints each number in the list
In the above example, the processList function takes a list of generic type T and a function type (T) -> Unit as parameters. The operation function is called for each item in the list and can perform any desired operation.
Now you know how to write functions that take functions as arguments, including how to provide default values for function parameters and handle nullable function types. This allows you to create more flexible and customizable functions in Kotlin.
Returning functions from functions
Returning functions from functions allows you to dynamically choose and provide different logic based on certain conditions or states. This can be useful in scenarios where the behavior of a program needs to adapt to different situations.
For example, let’s consider a shipping cost calculation scenario. The shipping cost may vary depending on the chosen delivery method. We can define a function called getShippingCostCalculator that takes the delivery parameter of type Delivery (an enum class representing different delivery options) and returns a function of type (Order) -> Double. The returned function calculates the shipping cost based on the selected delivery method.
Here’s an example implementation:
Kotlin
enumclassDelivery { STANDARD, EXPEDITED }classOrder(val itemCount: Int)fungetShippingCostCalculator(delivery: Delivery): (Order) -> Double { // Declares a function that returns a functionif (delivery == Delivery.EXPEDITED) {return { order ->6 + 2.1 * order.itemCount } // Returns lambdas from the function }return { order ->1.2 * order.itemCount } // Returns lambdas from the function}
In this example, when getShippingCostCalculator is called with Delivery.EXPEDITED, it returns a function that takes an Order parameter and calculates the shipping cost as 6 + 2.1 * order.itemCount. For any other delivery option, it returns a different function that calculates the shipping cost as 1.2 * order.itemCount.
You can use the returned function to calculate the shipping cost for a specific order. Here’s an example of usage:
Kotlin
val calculator = getShippingCostCalculator(Delivery.EXPEDITED) // Stores the returned function in a variableprintln("Shipping costs ${calculator(Order(3))}") // Invokes the returned function
In this code, we obtain the calculator function by calling getShippingCostCalculator with Delivery.EXPEDITED. Then, we pass an Order object with itemCount as 3 to the calculator function, which calculates and returns the shipping cost as 12.3. Finally, we print the shipping cost.
Let’s consider one more scenario where returning functions from functions is useful.
Suppose you’re working on a GUI contact-management application, and you need to determine which contacts should be displayed based on the state of the user interface (UI). You can define a function called getContactFilter that takes a UI state as a parameter and returns a function of type (Contact) -> Boolean. The returned function will determine whether a contact should be displayed or not based on the UI state.
Here’s an example implementation:
Kotlin
dataclassContact(val name: String, val isFavorite: Boolean)enumclassUIState { ALL, FAVORITES }fungetContactFilter(uiState: UIState): (Contact) -> Boolean { // Declares a function that returns a functionreturnwhen (uiState) { UIState.ALL -> { true } // Display all contacts UIState.FAVORITES -> { contact -> contact.isFavorite } // Display only favorite contacts }}
In this example, getContactFilter takes a UIState parameter and returns a function of type (Contact) -> Boolean. The returned function determines whether a contact should be displayed or not based on the UI state. If the UI state is UIState.ALL, the returned function always returns true, indicating that all contacts should be displayed. If the UI state is UIState.FAVORITES, the returned function checks the isFavorite property of the contact and returns its value, indicating whether the contact is a favorite or not.
You can use the returned function to filter the contacts based on the UI state. Here’s an example usage:
In this code, we obtain the filter function by calling getContactFilter with UIState.FAVORITES. Then, we have a list of contacts, and we use the filter function to filter the contacts based on the UI state. The filtered contacts, in this case, are the contacts that are marked as favorites. Finally, we print the names of the filtered contacts.
Returning functions from functions allows you to dynamically select and apply different logic based on conditions or states, providing flexibility and customization in your code.
Using function types from Java
Under the hood, function types are declared as regular interfaces: a variable of a function type is an implementation of a FunctionN interface. The Kotlin standard library defines a series of interfaces, corresponding to different numbers of function arguments: Function0 (this function takes no arguments), Function1 (this function takes one argument), and so on. Each interface defines a single invoke method, and calling it will execute the function. A variable of a function type is an instance of a class implementing the corresponding FunctionN interface, with the invoke method containing the body of the lambda.
Kotlin functions that use function types can be called easily from Java. Java 8 lambdas are automatically converted to values of function types:
// JavaprocessTheAnswer(number -> number + 1); // output : 43
In this case, the processTheAnswer function in Kotlin takes a function type (Int) -> Int as a parameter. In Java, you can pass a lambda expression number -> number + 1 as an argument, and it will be automatically converted to the corresponding function type.
What about older Java versions?
If you are using an older version of Java that doesn’t support lambdas, you can pass an instance of an anonymous class that implements the invoke method from the corresponding function interface. Here’s an example:
Kotlin
// JavaprocessTheAnswer(new Function1<Integer, Integer>() { // Uses the Kotlin function type from Java code (prior to Java 8)@Overridepublic Integer invoke(Integer number) { System.out.println(number);return number + 1; }});
In this Java example, we create an anonymous class that implements the Function1 interface. We override the invoke method, which corresponds to the function body in Kotlin, and provide the desired implementation.
What about Extention Functions?
In Java, you can easily use extension functions from the Kotlin standard library that expect lambdas as arguments. Note, however, that they don’t look as nice as in Kotlin — you have to pass a receiver object as a first argument explicitly. Here’s an example:
Kotlin
// JavaList<String> strings = new ArrayList<>();strings.add("42");CollectionsKt.forEach(strings, s -> { System.out.println(s);return Unit.INSTANCE;});
In this Java example, we use the CollectionsKt.forEach extension function from the Kotlin standard library. We pass a lambda expression s -> { ... } as an argument. Inside the lambda, we can perform the desired operations. Note that in Java, you need to explicitly return Unit.INSTANCE to match the Kotlin requirement of returning Unit.
It’s important to remember that in Java, functions or lambdas can return Unit. However, since Unit has a value in Kotlin, you need to explicitly return it. Additionally, you cannot directly pass a lambda that returns void as an argument of a function type that expects Unit as the return type.
Overall, while using function types and lambdas from Kotlin in Java may require some adjustments in syntax, it is still possible to utilize Kotlin’s higher-order functions and achieve the desired functionality.
Removing duplication through lambdas
In Kotlin, lambdas are anonymous functions that can be treated as values. They allow you to define blocks of code that can be passed around and executed later. This flexibility enables us to write more concise and reusable code.
Suppose you have a scenario where you need to perform similar operations on different elements of a collection. Without lambdas, you might end up writing repetitive code for each element, resulting in duplication. However, by utilizing lambdas, you can extract the common behavior and eliminate duplication.
To illustrate this concept, let’s consider an example involving website visit data. We have a class called SiteVisit that represents a visit to a website. Each visit has properties like path (the visited URL), duration (time spent on the page), and os (operating system used by the visitor). The os property is an enum called OS, representing different operating systems.
Our goal is to calculate the average duration of visits from Windows machines. We can achieve this by filtering the visits based on the operating system, mapping the durations, and then calculating the average using the average function.
In this example, we used the lambda expression { it.os == OS.WINDOWS } as a filter to select only the visits with the Windows operating system. Then, we used the map function to extract the durations of those visits. Finally, the average function calculated the average duration.
Now, let’s say we want to calculate the average duration for visits from Mac users as well. Without using lambdas, we would need to write similar code again, resulting in duplication. However, we can avoid this duplication by extracting the common behavior into a function and parameterizing it.
We define an extension function called averageDurationFor on the List<SiteVisit> class, which takes an os parameter representing the operating system. Inside the function, we filter the visits based on the given operating system, map the durations, and calculate the average.
Kotlin
funList<SiteVisit>.averageDurationFor(os: OS) =filter { it.os == os } .map(SiteVisit::duration) .average()
With this function in place, we can now calculate the average duration for both Windows and Mac visits without duplicating the code.
By parameterizing the behavior that varies (in this case, the operating system), we eliminated duplication and made the code more reusable and maintainable.
However, there are situations where a simple parameter is not sufficient to capture the complexity of the condition we want to apply. For example, if we want to calculate the average duration for visits from mobile platforms (iOS and Android), a single parameter representing the operating system won’t be enough. In such cases, lambdas provide a powerful solution.
We can modify our averageDurationFor function to take a lambda expression as a parameter. This lambda expression represents a condition that needs to be fulfilled for a visit to be included in the calculation.
Now, we can use this enhanced averageDurationFor function to calculate the average duration based on more complex conditions. For example, finding the average duration for visits from Android and iOS users:
In this case, we passed a lambda expression { it.os in setOf(OS.ANDROID, OS.IOS) } to the averageDurationFor function. This lambda expression represents the condition that checks if the operating system is either Android or iOS.
Similarly, we can use Lambdas to perform more intricate queries, such as finding the average duration of visits to the signup page from iOS users:
Here, we provided a lambda expression { it.os == OS.IOS && it.path == "/signup" } to specify the condition that includes only the visits from iOS users to the “/signup” page.
By using lambdas and function types, we can eliminate code duplication and extract both the repeated data and behavior into reusable functions. Lambdas allow us to write more expressive and concise code, making our programs easier to understand and maintain.
Function types and lambdas not only help eliminate code duplication but also provide a flexible and concise way to define different strategies or behaviors within your code. Instead of creating multiple classes or interfaces for each strategy, you can directly pass lambda expressions as different strategies, simplifying your code and making it more expressive.
Conclusion
Function types in Kotlin provide a powerful way to work with functions as first-class citizens. They enable you to pass functions as parameters, return them from functions, and even assign them to variables. This flexibility allows for concise and expressive code, making Kotlin a great language for functional programming paradigms. By understanding the various aspects of function types and exploring practical examples, you can leverage this feature to write more efficient and maintainable code. So go ahead, harness the power of function types in Kotlin, and take your programming skills to the next level!