
AI tools can write code, summarize documents, answer questions, and generate content in seconds. But for a long time, they all shared the same problem: they confidently returned wrong answers.
These made-up responses are called hallucinations. If you’ve used an AI chatbot long enough, you’ve probably seen one. A model cites a fake research paper, invents an API method, or gives outdated information as if it were current.
That problem pushed developers toward a new approach: Retrieval-Augmented Generation (RAG).
Retrieval-Augmented Generation gives AI systems access to external knowledge before generating a response. Instead of relying only on what the model learned during training, the system retrieves relevant information from trusted sources and feeds it into the prompt.
The result is far more grounded and reliable output.
This article breaks down how Retrieval-Augmented Generation works, why it matters, how developers build RAG pipelines, and where it still falls short.
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) combines two systems:
- Information retrieval
- Large language models (LLMs)
The retrieval layer searches for relevant information from external sources. The language model then uses that information to generate a response.
Without Retrieval-Augmented Generation, an LLM answers questions using only the data it saw during training. That creates obvious problems:
- Training data becomes outdated
- Domain-specific knowledge may be missing
- Models fill gaps with statistically likely text
RAG changes the workflow by giving the model fresh context at runtime.
Instead of generating answers from memory alone, the model works from retrieved evidence.
Why AI Hallucinations Happen
Large language models predict the next token in a sequence. They are optimized for language generation, not fact verification.
That distinction matters.
A model can produce fluent, convincing answers even when the underlying information is wrong. In many cases, hallucinations happen because the model lacks reliable context for the question being asked.
Common causes include:
- Outdated training data
- Missing domain knowledge
- Ambiguous prompts
- Weak retrieval pipelines
- Limited context windows
For example, if you ask a standard LLM about a recently released framework or API update, it may generate an answer based on older patterns from training data.
Retrieval-Augmented Generation helps by pulling in current, relevant information before the response is generated.
How Retrieval-Augmented Generation Works
At a high level, a RAG pipeline follows this sequence:
- A user submits a query
- The system searches a knowledge source
- Relevant documents are retrieved
- Retrieved content is injected into the prompt
- The LLM generates a response using that context
The architecture is simple conceptually, but each step affects answer quality.
Core Components of a RAG System
Most Retrieval-Augmented Generation systems contain the same foundational pieces.
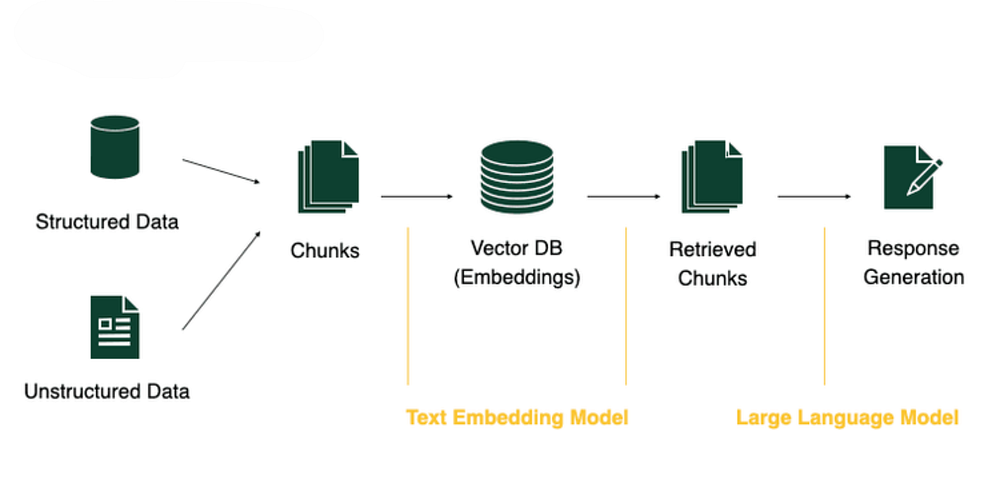
1. Data Source
This is the knowledge layer the system retrieves from.
Typical sources include:
- PDFs
- Internal documentation
- Wikis
- Databases
- APIs
- Research papers
- Web content
The quality of your RAG system depends heavily on the quality of these sources.
Poor documentation leads to poor retrieval.
2. Chunking
Documents are split into smaller sections called chunks.
Language models and embedding systems work better with smaller pieces of text than large documents.
A long PDF might become hundreds of chunks, each containing:
- A focused topic
- Related context
- Roughly 200–500 words
Chunk size has a direct impact on retrieval quality.
Small chunks improve precision but may lose context. Large chunks preserve context but can reduce search accuracy.
3. Embeddings
Each chunk is converted into a vector embedding.
Embeddings are numerical representations of semantic meaning. They allow systems to compare text based on similarity rather than exact keywords.
For example:
- “Authentication token expired”
- “Session credential timeout”
These phrases may produce similar embeddings even though the wording differs.
Popular embedding models include:
- OpenAI Embeddings
- Sentence Transformers
- Cohere Embeddings
4. Vector Database
Embeddings are stored inside a vector database.
Common options include:
- Pinecone
- Weaviate
- Chroma
- Milvus
When a user submits a query, the query is converted into an embedding and compared against stored vectors.
The system retrieves the closest semantic matches.
This process is called similarity search.
5. Large Language Model (LLM)
The retrieved chunks are added to the prompt sent to the language model.
The model generates a response using that retrieved context as grounding material.
This step is what reduces hallucinations. The model has relevant information available during generation instead of relying entirely on training memory.
A Simple RAG Example
Suppose a user asks:
“What is our company’s refund policy?”
A standard LLM may:
- Guess based on common refund policies
- Return outdated information
- Invent policy details entirely
A Retrieval-Augmented Generation system handles it differently:
- Search company documents
- Retrieve the refund policy section
- Inject the text into the prompt
- Generate the answer from retrieved context
That workflow is why RAG has become common in enterprise AI systems.
Retrieval-Augmented Generation Architecture
A simplified RAG pipeline looks like this:
User Query
↓
Embedding Model
↓
Vector Search
↓
Retrieve Relevant Chunks
↓
Augment Prompt
↓
Large Language Model
↓
Final ResponseEach layer improves the model’s ability to generate grounded answers.
Why Retrieval-Augmented Generation Matters
As AI systems move into production environments, accuracy becomes critical.
Hallucinated answers can create real problems in:
- Healthcare
- Finance
- Legal systems
- Customer support
- Enterprise search
- Developer tooling
Retrieval-Augmented Generation helps teams build systems that are more reliable and easier to trust. Grounded responses backed by verifiable sources naturally support those principles.
Benefits of Retrieval-Augmented Generation
Reduced Hallucinations
This is the primary reason teams adopt RAG.
The model generates answers from retrieved evidence instead of unsupported assumptions.
Access to Current Information
Traditional LLMs are limited to their training cutoff.
RAG systems can work with:
- Live APIs
- Updated documentation
- Internal databases
- Recently published content
Better Enterprise Search
Organizations can build internal AI assistants trained on:
- SOPs
- Product docs
- Internal wikis
- Support documentation
Without retraining the entire model.
Lower Operational Costs
Updating a knowledge base is generally faster and cheaper than repeatedly fine-tuning large models.
Improved Transparency
Many RAG systems can expose retrieved sources alongside generated answers.
That makes outputs easier to verify.
Limitations of Retrieval-Augmented Generation
RAG improves accuracy, but it does not solve every problem.
Retrieval Quality Still Matters
If retrieval fails, generation quality drops quickly.
Irrelevant chunks often lead to weak or misleading answers.
Added Latency
A RAG pipeline introduces additional steps:
- Embedding generation
- Vector search
- Context assembly
That increases response time compared to direct generation.
Context Window Constraints
LLMs still have token limits.
Too much retrieved context can dilute answer quality or exceed model limits.
Infrastructure Complexity
Building Retrieval-Augmented Generation systems requires multiple moving parts:
- Embedding pipelines
- Vector databases
- Search optimization
- Prompt engineering
- Evaluation workflows
Production-grade RAG systems need careful tuning.
RAG vs Fine-Tuning
Retrieval-Augmented Generation and fine-tuning solve different problems.

Many production systems combine both approaches.
Fine-tuning shapes model behavior. RAG supplies current knowledge.
Types of Retrieval-Augmented Generation
Naive RAG
This is the simplest setup:
- Retrieve documents
- Inject context
- Generate response
It works surprisingly well for many use cases.
Advanced RAG
Advanced pipelines often include:
- Hybrid search
- Reranking models
- Query rewriting
- Metadata filtering
These additions improve retrieval precision.
Agentic RAG
Agentic systems allow models to decide:
- What to retrieve
- When to retrieve
- How to validate information
- Which tools to use
This area is evolving quickly.
Real-World Use Cases
Customer Support
AI assistants retrieve information from product documentation and support articles before answering customer questions.
Legal Research
Law firms use Retrieval-Augmented Generation to surface relevant statutes, case law, and legal references.
Healthcare Applications
Medical AI systems retrieve verified medical literature and clinical references before generating responses.
Enterprise Knowledge Search
Employees can search across thousands of internal documents using natural language queries.
AI Coding Assistants
Coding tools retrieve API docs, repositories, and framework references before generating code suggestions.
Platforms like GitHub Copilot increasingly rely on retrieval-based workflows.
Building a Simple RAG Pipeline in Python
Let’s walk through a minimal Retrieval-Augmented Generation setup using:
- Python
- LangChain
- OpenAI
- FAISS
Install Dependencies
pip install langchain openai faiss-cpu tiktokenThese packages handle:
- Document loading
- Text chunking
- Embeddings
- Vector search
- LLM interaction
Step 1: Load Documents
from langchain.document_loaders import TextLoader
loader = TextLoader("knowledge_base.txt")
documents = loader.load()This loads your knowledge source into memory.
The file could contain:
- Product documentation
- Internal policies
- Technical articles
- Research material
Step 2: Split Documents Into Chunks
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
docs = text_splitter.split_documents(documents)Chunking improves retrieval quality by breaking large documents into manageable sections.
The overlap helps preserve context between chunks.
Step 3: Generate Embeddings
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()Embeddings convert text into vectors that represent semantic meaning.
Those vectors allow the system to retrieve related content even when exact wording differs.
Step 4: Store Embeddings in FAISS
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(docs, embeddings)Meta developed FAISS for efficient similarity search across large vector datasets.
At this point, the system can search documents semantically instead of relying on keyword matching alone.
Step 5: Retrieve Relevant Chunks
query = "How does Retrieval-Augmented Generation reduce hallucinations?"
retrieved_docs = vectorstore.similarity_search(query)The query is converted into an embedding and compared against stored vectors.
The database returns the closest semantic matches.
This is the retrieval phase of the pipeline.
Step 6: Generate the Final Response
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4")
context = "\n".join([doc.page_content for doc in retrieved_docs])
prompt = f"""
Use the following context to answer the question accurately.
Context:
{context}
Question:
{query}
"""
response = llm.predict(prompt)
print(response)The retrieved context is injected into the prompt before generation.
That gives the model grounded information to work from and improves factual accuracy.
Best Practices for RAG Systems
Start With Good Data
Strong retrieval begins with clean, accurate documentation.
Weak source material creates weak outputs.
Test Different Chunk Sizes
Chunk size directly affects retrieval quality.
There is no universal setting that works for every dataset.
Use Hybrid Search
Combining semantic search with keyword search often improves retrieval precision.
Add Reranking
Rerankers help prioritize the most relevant retrieved chunks before generation.
This can significantly improve final answers.
Measure Hallucination Rates
RAG reduces hallucinations, but evaluation still matters.
Track:
- Retrieval relevance
- Citation accuracy
- Response correctness
- Failure cases
The Future of Retrieval-Augmented Generation
Retrieval-Augmented Generation is becoming standard infrastructure for production AI systems.
Current trends include:
- Multimodal RAG
- Real-time retrieval pipelines
- Agentic workflows
- Long-term memory systems
- Self-evaluating retrieval loops
As models improve, retrieval quality is becoming one of the biggest differentiators between AI products.
Frequently Asked Questions
Is Retrieval-Augmented Generation better than fine-tuning?
They solve different problems.
RAG works well for dynamic knowledge and frequently updated information. Fine-tuning is useful for behavior customization and specialized tasks.
Does RAG eliminate hallucinations completely?
No.
It reduces hallucinations significantly, but generation errors can still happen if retrieval quality is poor or context is incomplete.
Which vector database is best for RAG?
Popular choices include:
- Pinecone
- Weaviate
- Chroma
- FAISS
The right choice depends on scale, latency requirements, infrastructure preferences, and budget.
Can Retrieval-Augmented Generation use live internet data?
Yes.
Many systems retrieve information from APIs, search engines, and real-time web sources.
Conclusion
Retrieval-Augmented Generation has become one of the most practical ways to improve AI reliability.
Instead of relying entirely on static training data, RAG systems retrieve relevant information at runtime and use it to ground generated responses.
That shift improves:
- Accuracy
- Transparency
- Freshness
- Trustworthiness
For developers building production AI systems, Retrieval-Augmented Generation is quickly becoming a core architectural pattern rather than an optional enhancement.