When working with lists in Kotlin, a common task is to find the two smallest numbers. Whether you’re solving coding challenges, optimizing algorithms, or simply manipulating data, knowing how to efficiently extract the smallest elements is useful.
We then filter out the smallest number and find the next smallest using minOrNull() again.
This method is concise but slightly less efficient than the single-pass method.
Time Complexity: O(n) for filtering + O(n) for finding the min → Overall, O(n).
Which Method Should You Use?
Method
Time Complexity
Best Use Case
Sorting (sorted())
O(n log n)
When readability is more important than speed
Single-pass (Efficient)
O(n)
When performance is a priority
Functional (minOrNull())
O(n)
When writing concise and idiomatic Kotlin
Conclusion
In this blog, we explored multiple ways to find the two smallest numbers in a Kotlin list. We covered sorting, a highly efficient single-pass approach, and a functional-style solution. Each method has its trade-offs in terms of readability and performance.
When analyzing algorithms, time complexity plays a crucial role in determining their efficiency. Two common complexities encountered in sorting, searching, and data structure operations areO(n) (linear time) and O(n log n) (linearithmic time). But which one is better? In this blog, we will explore both complexities in detail, understand their significance, and compare them with real-world examples.
Understanding O(n) vs. O(n log n) Complexity
Imagine you’re throwing a party, and you need to greet every single guest. If you shake hands with each person individually, that’s a straightforward, one-to-one interaction. That’s essentially what O(n) is — a linear relationship. The time it takes to greet everyone grows directly with the number of guests.
Now, picture a slightly more complex scenario. You’re not just greeting guests; you’re also organizing them by height, and you’re using a clever method that involves repeatedly dividing the group in half and comparing heights. This is more akin to O(n log n). It’s still efficient, But it involves a bit more ‘thinking’ (checks) for each guest.
What is O(n)?
O(n), or linear time complexity, means that the execution time of an algorithm increases directly in proportion to the size of the input. If we double the input size, the time required also doubles.
A simple example of an O(n) algorithm is traversing an array:
Kotlin
funprintElements(arr: IntArray) {for (element in arr) {println(element) }}
Here, if we have an array of size n, the loop runs n times, making it O(n).
When O(n) is Used?
Searching in an unsorted array
Finding the maximum or minimum element in an arra
Simple computations that process each element once
What is O(n log n)?
O(n log n), or linearithmic time complexity, appears in algorithms where the problem is divided into smaller subproblems (like divide-and-conquer strategies). The additional log(n) factor results from recursive halving or merging operations.
A common example of O(n log n) complexity is Merge Sort:
Kotlin
funmergeSort(arr: IntArray): IntArray {if (arr.size <= 1) return arrval mid = arr.size / 2val left = mergeSort(arr.sliceArray(0 until mid))val right = mergeSort(arr.sliceArray(mid until arr.size))returnmerge(left, right)}funmerge(left: IntArray, right: IntArray): IntArray {var i = 0; var j = 0val mergedList = mutableListOf<Int>()while (i < left.size && j < right.size) {if (left[i] < right[j]) { mergedList.add(left[i++]) } else { mergedList.add(right[j++]) } }while (i < left.size) mergedList.add(left[i++])while (j < right.size) mergedList.add(right[j++])return mergedList.toIntArray()}
In Merge Sort, the array is divided into halves (log(n) times), and each element is processed (n times), resulting in O(n log n) complexity.
When O(n log n) is Used?
Sorting large datasets (Merge Sort, Quick Sort, Heap Sort)
Efficient searching in balanced trees
Solving problems using divide and conquer approach
O(n) vs. O(n log n): Which One is Better?
Complexity
Growth Rate
When to Use
O(n)
Faster for large inputs (linear growth)
When direct iteration is possible
O(n log n)
Slower due to log factor
When sorting or recursion is required
Example: If n = 1,000,000:
O(n) → 1,000,000 operations
O(n log n) → ~20,000,000 operations (log base 2)
Clearly, O(n) is preferable whenever possible, but for sorting and recursion-based problems, O(n log n) is necessary.
Conclusion
Understanding time complexity is essential for writing efficient code. O(n) is ideal for simple iterations, while O(n log n) is crucial for sorting and divide-and-conquer approaches. By recognizing these complexities, developers can optimize their code for better performance.
Generics in Kotlin can seem complex at first, but once you understand their power, they make your code more flexible and reusable. In this blog, we’ll break down generics in a simple way, focusing on generic functions and properties and best practices.
What Are Generics in Kotlin?
Generics allow you to write code that works with different data types without sacrificing type safety. Instead of specifying an exact type, you define a placeholder type that gets replaced with a real type at runtime.
For example, consider a function that prints any type of element. Instead of writing separate functions for Int, String, and other types, you can use generics to make it work for any type.
A generic function uses a type parameter to make it more flexible. The type parameter is placed inside angle brackets (<>) before the function’s parameter list.
A Simple Generic Function
Kotlin
fun <T> printItem(item: T) {println(item)}funmain() {printItem(42) // Works with IntprintItem("Hello") // Works with StringprintItem(3.14) // Works with Double}
<T> is the type parameter.
T is used as the parameter type inside the function.
The function can now accept any type, making it more reusable.
Kotlin’s generics allow for reusable and type-safe code. By understanding generic functions and properties, you can write cleaner and more efficient Kotlin programs. Follow best practices, use it wisely, and keep your code readable.
Now that you have a solid grasp, try using generic functions and properties in your own Kotlin projects!
Kotlin is a powerful language that puts a strong emphasis on null safety. However, when working with generics, it’s easy to accidentally allow nullability, even when you don’t intend to. If you’re wondering how to enforce non-null type parameters properly, this guide will walk you through the right approach.
Why Enforcing Non-Null Type Parameters Matters
Kotlin’s type system prevents null pointer exceptions by distinguishing between nullable and non-nullable types. However, generics (T) are nullable by default, which can lead to unintended issues if not handled correctly.
For example, consider the following generic class:
Kotlin
classContainer<T>(valvalue: T)
Here, T can be any type—including nullable ones like String?. This means that Container<String?> is a valid type, even if you don’t want to allow null values.
Making type parameters non-null
In Kotlin, when you declare a generic class or function, you can substitute any type argument, including nullable types, for its type parameters. By default, a type parameter without an upper bound specified will have the upper bound of Any? which means it can accept both nullable and non-nullable types.
Let’s take an example to understand this. Consider the Processor class defined as follows:
Kotlin
classProcessor<T> {funprocess(value: T) {value?.hashCode() // value” is nullable, so you have to use a safe call }}
In the process function of this class, the parameter value is nullable, even though T itself is not marked with a question mark. This is because specific instantiations of the Processor class can use nullable types for T. For example, you can create an instance of Processor<String?> which allows nullable strings as its type argument:
Kotlin
val nullableStringProcessor = Processor<String?>() // String?, which is a nullable type, is substituted for TnullableStringProcessor.process(null) // This code compiles fine, having “null” as the “value” argument
If you want to ensure that only non-null types can be substituted for the type parameter, you can specify a constraint or an upper bound. If the only restriction you have is nullability, you can use Any as the upper bound instead of the default Any?. Here’s an example:
Kotlin
classProcessor<T : Any> { // Specifying a non-“null” upper boundfunprocess(value: T) {value.hashCode() // “value” of type T is now non-“null” }}
In this case, the <T : Any> constraint ensures that the type T will always be a non-nullable type. If you try to use a nullable type as the type argument, like Processor<String?>(), the compiler will produce an error. The reason is that String? is not a subtype of Any (it’s a subtype of Any?, which is a less specific type):
Kotlin
val nullableStringProcessor = Processor<String?>()// Error: Type argument is not within its bounds: should be subtype of 'Any'
It’s worth noting that you can make a type parameter non-null by specifying any non-null type as an upper bound, not only Any. This allows you to enforce stricter constraints based on your specific needs.
The Wrong Way: Using T : Any?
Some developers mistakenly try to restrict T by writing:
Kotlin
classContainer<T : Any?>(valvalue: T)
However, this does not enforce non-nullability. The bound Any? explicitly allows both Any (non-null) and null. This approach is unnecessary since T is already nullable by default.
The Right Way: Enforcing Non-Null Type Parameters
To ensure that a type parameter is always non-null, you should use an upper bound of Any instead:
Kotlin
classContainer<T : Any>(valvalue: T)
Why This Works
The constraint T : Any ensures that T must be a non-nullable type.
Container<String?>will not compile, preventing unintended nullability.
You still maintain type safety and avoid potential null pointer exceptions.
These patterns ensure that all implementations respect non-nullability.
Conclusion
Making type parameters non-null in Kotlin is essential for writing safer, more predictable code. Instead of leaving T nullable or mistakenly using T : Any?, enforce non-nullability using T : Any. This simple yet powerful technique helps prevent unexpected null values while maintaining the flexibility of generics.
By applying this Kotlin tip, you can improve your code’s safety and avoid common pitfalls related to nullability.
Reification is a powerful concept in Kotlin that allows us to retain generic type information at runtime. However, it comes with a significant limitation: it only works for inline functions. But why is that the case? Let’s explore the reasons behind this restriction and understand how reification truly works.
Understanding Reification
In most JVM-based languages, including Kotlin and Java, generic type parameters are erased at runtime due to type erasure. This means that when a function or class uses generics, the type information is not available at runtime. For example, the following function:
Kotlin
fun <T> printType(value: T) {println(value::class) // Error: Type information is erased}
The above code won’t work as expected because T is erased and does not retain type information.
How Reification Works
Reification in Kotlin allows us to retain generic type information at runtime when using inline functions. It enables us to work with generics in a way that would otherwise be impossible due to type erasure.
To make a generic type reified, we use the reified keyword inside an inline function:
Kotlin
inlinefun <reifiedT> printType(item: T) {println(T::class) // Works because T is reified}
Now, if we call:
Kotlin
printType("Hello")
The output will be:
Kotlin
classkotlin.String
Unlike the earlier example, this works because T is no longer erased. But why does this work only for inline functions?
Why reification works for inline functions only?
Reification works for inline functions because the compiler inserts the bytecode implementing the inline function directly at every place where it is called. This means that the compiler knows the exact type used as the type argument in each specific call to the inline function.
Let’s understand this concept with the filterIsInstance() function from the Kotlin standard library.
When you call an inline function with a reified type parameter, the compiler can generate a bytecode that references the specific class used as the type argument for that particular call. For example, in the case of the filterIsInstance<String>() call, the generated code would be equivalent to:
Kotlin
for (element inthis) {if (element is String) { destination.add(element) }}
The generated bytecode references the specific String class, not a type parameter, so it is not affected by the type-argument erasure that occurs at runtime. This allows the reified type parameter to be used for type checks and other operations at runtime.
What Happens if You Try Reification in a Non-Inline Function?
If you try to use a reified type parameter in a non-inline function, you’ll get a compilation error:
Kotlin
fun <reifiedT> printNonInlineType(value: T) { // Errorprintln(T::class)}
This error occurs because, without inlining, the type information would be erased, making T::class invalid.
Workarounds for Non-Inline Functions
If you need to retain type information in a non-inline function, consider using class references or passing a KClass<T> parameter:
Kotlin
fun <T: Any> printType(clazz: KClass<T>, value: T) {println(clazz)}printType(String::class, "Hello")
This approach ensures the type is explicitly provided and prevents type erasure.
Conclusion
Reification is a powerful feature in Kotlin, but it is only possible within inline functions due to JVM type erasure. Inline functions allow type parameters to be substituted at compile time, preserving the type information at runtime. If you need to work with generic types in non-inline functions, you’ll need alternative solutions like KClass references.
Understanding this limitation helps developers write more effective and optimized Kotlin code while leveraging the benefits of reification where necessary.
Kotlin has gained immense popularity for its modern and expressive syntax, making Android development and general programming more efficient. One of its unique features is the companion object, which allows defining static-like members within a class. If you’re a beginner looking to understand Kotlin companion objects, this guide will take you through every essential detail.
What is a Kotlin Companion Object?
In Kotlin, unlike Java, there are no static methods. Instead, Kotlin provides a way to achieve similar functionality using companion objects. A Kotlin Companion Object is an object associated with a class that allows you to access its properties and methods without creating an instance of the class.
Key Characteristics:
A companion object is defined inside a class using the companion keyword.
It behaves like a singleton, meaning there is only one instance of it per class.
You can access its properties and methods using the class name, just like static members in Java.
How to Declare a Companion Object
Declaring a companion object in Kotlin is simple. Use the companion object keyword inside a class.
Kotlin
classMyClass {companionobject {funsayHello() {println("Hello from Companion Object!") } }}funmain() { MyClass.sayHello() // Calling the function without creating an instance}
Here,
The companion object inside MyClass defines a function sayHello().
MyClass.sayHello() is called directly, without creating an instance.
This behavior is similar to Java’s static methods but follows Kotlin’s object-oriented approach.
Adding Properties in a Companion Object
You can also define properties inside a companion object.
The companion object implements the Logger interface.
Now, Service.log("Service started") logs a message without an instance.
Conclusion
Kotlin companion objects provide a powerful way to create static-like functionality while keeping an object-oriented structure. They enable defining functions, properties, factory methods, and interface implementations within a class, making code more readable and maintainable.
Now that you have a clear understanding, start using companion objects in your Kotlin projects and take advantage of their benefits..!
Generics in Kotlin add flexibility and type safety, but sometimes we don’t need to specify a type. This is where star projection (*) comes in. In this blog, we’ll explore star projection in Kotlin, its use cases, and practical examples to help you understand how and when to use it.
Understanding Star Projection in Kotlin
In Kotlin, star projection is a syntax that allows you to indicate that you have no information about a generic argument. It is represented by the asterisk (*) symbol. Let’s explore the semantics of star projections in more detail.
When you use star projection, such as List<*>, it means you have a list of elements of an unknown type. It’s important to note that MutableList<*> is not the same as MutableList<Any?>. The former represents a list that contains elements of a specific type, but you don’t know what type it is. You can’t put any values into the list because it may violate the expectations of the calling code. However, you can retrieve elements from the list because you know they will match the type Any?, which is the supertype of all Kotlin types.
Here’s an example to illustrate this:
Kotlin
val list: MutableList<Any?> = mutableListOf('a', 1, "qwe")val chars = mutableListOf('a', 'b', 'c')val unknownElements: MutableList<*> = if (Random().nextBoolean()) list else charsunknownElements.add(42) // Error: Adding elements to a MutableList<*> is not allowedprintln(unknownElements.first()) // You can retrieve elements from unknownElements
In this example, unknownElements can be either list or chars based on a random condition. You can’t add any values to unknownElements because its type is unknown, but you can retrieve elements from it using the first() function.
Kotlin
unknownElements.add(42)// Error: Out-projected type 'MutableList<*>' prohibits//the use of 'fun add(element: E): Boolean
The term “out-projected type” refers to the fact that MutableList<*> is projected to act as MutableList<out Any?>. It means you can safely get elements of type Any? from the list but cannot put elements into it.
For contravariant type parameters, like Consumer<in T>, a star projection is equivalent to <in Nothing>. In this case, you can’t call any methods that have T in the signature on a star projection because you don’t know exactly what it can consume. This is similar to Java’s wildcards (MyType<?> in Java corresponds to MyType<*> in Kotlin).
You can use star projections when the specific information about type arguments is not important. For example, if you only need to read the data from a list or use methods that produce values without caring about their specific types. Here’s an example of a function that takes List<*> as a parameter:
In this case, the printFirst function only reads the first element of the list and doesn’t care about its specific type. Alternatively, you can introduce a generic type parameter if you need more control over the type:
Kotlin
fun <T> printFirst(list: List<T>) {if (list.isNotEmpty()) {println(list.first()) }}
The syntax with star projection is more concise, but it works only when you don’t need to access the exact value of the generic type parameter.
Now let’s consider an example using a type with a star projection and common traps that you may encounter. Suppose you want to validate user input using an interface called FieldValidator. It has a type parameter declared as contravariant (in T). You also have two validators for String and Int inputs.
If you want to store all validators in the same container and retrieve the right validator based on the input type, you might try using a map. However, using FieldValidator<*> as the value type in the map can lead to difficulties. You won’t be able to validate a string with a validator of type FieldValidator<*> because the compiler doesn’t know the specific type of the validator.
Kotlin
val validators = mutableMapOf<KClass<*>, FieldValidator<*>>()validators[String::class] = DefaultStringValidatorvalidators[Int::class] = DefaultIntValidatorvalidators[String::class]!!.validate("") // Error: Cannot call validate() on FieldValidator<*>
In this case, you will encounter a similar error as before, indicating that it’s unsafe to call a method with the type parameter on a star projection. One way to work around this is by explicitly casting the validator to the desired type, but this is not recommended as it is not type-safe.
Kotlin
val stringValidator = validators[String::class] as FieldValidator<String><br>println(stringValidator.validate("")) // Output: false
This code compiles, but it’s not safe because the cast is unchecked and may fail at runtime if the generic type information is erased.
A safer approach is to encapsulate the access to the map and provide type-safe methods for registration and retrieval. This ensures that only the correct validators can be registered and retrieved. Here’s an example using an object called Validators:
In this example, the Validators object controls all access to the map, ensuring that only correct validators can be registered and retrieved. The code emits a warning about the unchecked cast, but the guarantees provided by the Validators object make sure that no incorrect use can occur.
This pattern of encapsulating unsafe code in a separate place helps prevent misuse and makes the usage of a container safe. It’s worth noting that this pattern is not specific to Kotlin and can be applied in Java as well.
Star Projection vs Wildcards in Java
If you are familiar with Java, you might recognize ? (wildcard) in generics:
In Kotlin, ? is used for nullability, so * is used instead for wildcard-like behavior.
List<?> in Java ⟶ List<*> in Kotlin
List<? extends T> in Java ⟶ List<out T> in Kotlin
List<? super T> in Java ⟶ List<in T> in Kotlin
Kotlin’s approach is more concise and expressive, improving readability and reducing boilerplate code.
Limitations of Star Projection
While * is useful, it has some limitations:
You cannot add elements to a List<*> because the exact type is unknown.
The compiler restricts unsafe operations to maintain type safety.
Using * excessively can make code less readable.
For example, this won’t work:
Kotlin
funaddElement(list: MutableList<*>) { list.add(42) // Error: Cannot add an element of type Int}
To modify a generic list, you need a known type parameter:
Kotlin
fun <T> addElement(list: MutableList<T>, element: T) { list.add(element)}
When to Use Star Projection in Kotlin
When you need to access elements from a generic class but don’t care about their exact type.
When working with APIs that use generics, and you don’t want to specify a concrete type.
When you want to achieve type safety while maintaining code flexibility.
Conclusion
Star projection in Kotlin simplifies working with generics when the type is unknown or irrelevant. It provides flexibility while ensuring type safety, making it a valuable tool in generic programming.
Next time you’re handling generics, consider whether * might be the right choice to simplify your code.
Kotlin coroutines are a powerful feature that simplify asynchronous programming. They allow developers to write asynchronous code in a sequential manner, making it easier to read and maintain. At the heart of coroutines are coroutine builders, specifically launch and async. These builders define how coroutines are started and managed.
In this blog, we’ll dive deep into the differences between launch and async, when to use them, and best practices for effective coroutine usage.
Understanding Coroutine Builders
A coroutine builder is a function that creates and starts a coroutine. The two primary coroutine builders in Kotlin are:
launch: Used for fire-and-forget operations (does not return a result).
async: Used for parallel computations that return a result.
Let’s explore both in detail.
launch – Fire and Forget
The launch builder is used when you don’t need a result. It starts a coroutine that runs independently, meaning it does not return a value. However, it returns a Job object, which can be used to manage its lifecycle (e.g., cancellation or waiting for completion).
Key Points:
Does not return a result.
Returns a Job that can be used for cancellation or waiting.
Runs in the background without blocking the main thread.
The coroutine is launched using launch(Dispatchers.IO) { ... }.
The fetchData() function runs asynchronously without blocking the main thread.
job.join() ensures the coroutine completes before proceeding.
Output:
Kotlin
Data: FetchedDataCoroutine completed
Note: If job.join() is not called, the program might exit before the coroutine completes, depending on the coroutine scope.
async – Returns a Result
The async builder is used when you need a result. It returns a Deferred<T> object, which represents a future result. To retrieve the result, you must call await().
Key Points:
Returns a Deferred<T> object, which must be awaited.
Used for parallel computations.
Must be called within a coroutine scope.
Kotlin
import kotlinx.coroutines.*funmain() = runBlocking {val result = async(Dispatchers.IO) { fetchData() }println("Data: ${result.await()}") // Await to get the result}suspendfunfetchData(): String {delay(1000) // Simulating network callreturn"Fetched Data"}
async(Dispatchers.IO) { fetchData() } starts an asynchronous task.
It returns a Deferred<String> object.
Calling .await() retrieves the result.
Output:
Kotlin
Data: FetchedData
Important: If you do not call await(), the coroutine will run, but the result won’t be retrieved.
async for Parallel Execution
One of the most powerful use cases for async is running multiple tasks in parallel.
async { fetchData1() } and async { fetchData2() } start in parallel.
Each coroutine takes 1 second.
Since they run concurrently, the total execution time is ~1 second instead of 2 seconds (if they run sequentially then 2 seconds).
Best Practices for launch and async
Use launch when you don’t need a result (e.g., updating UI, logging, background tasks).
Use async when you need a result and always call await().
For multiple async tasks, start them first, then call await() to maximize concurrency.
Avoid using async outside of structured concurrency unless you explicitly manage its lifecycle, as it can lead to untracked execution, potential memory leaks, or uncaught exceptions.
Conclusion
Kotlin’s launch and async coroutine builders serve distinct purposes:
Use launch when you don’t need a result (fire-and-forget).
Use async when you need a result (and always call await()).
By understanding the differences and best practices, you can write efficient, safe, and scalable Kotlin applications using coroutines.
Kotlin is a powerful programming language that simplifies development while maintaining strong type safety. One of the essential concepts in Kotlin is variance, which helps us understand how generics and subtyping work. If you’ve ever been confused by out, in, or *, and how generics behave in Kotlin, this guide is for you.
Variance: generics and subtyping
The concept of variance describes how types with the same base type and different type arguments relate to each other: for example, List<String> and List<Any>. It’s important to understand variance when working with generic classes or functions because it helps ensure the safety and consistency of your code.
Why variance exists: passing an argument to a function
To illustrate why variance is important, let’s consider passing arguments to functions. Suppose we have a function that takes a List<Any> as an argument. Is it safe to pass a variable of type List<String> to this function?
In the case of a function that prints the contents of the list, such as:
You can safely pass a list of strings (List<String>) to this function. Each element in the list is treated as an Any, and since String is a subtype of Any, it is considered safe.
However, let’s consider another function that modifies the list:
If you attempt to pass a list of strings (MutableList<String>) to this function, like so:
Kotlin
val strings = mutableListOf("abc", "bac")addAnswer(strings)println(strings.maxBy { it.length })
You will encounter a ClassCastException at runtime. This occurs because the function addAnswer tries to add an integer (42) to a list of strings. If the compiler allowed this, it would lead to a type inconsistency when accessing the contents of the list as strings. To prevent such issues, the Kotlin compiler correctly forbids passing a MutableList<String> as an argument when a MutableList<Any> is expected.
So, the answer to whether it’s safe to pass a list of strings to a function expecting a list of Any objects depends on whether the function modifies the list. If the function only reads the list, it is safe to pass a List with a more specific element type. However, if the list is mutable and the function adds or replaces elements, it is not safe.
Kotlin provides different interfaces, such as List and MutableList, to control safety based on mutability. If a function accepts a read-only list, you can pass a List with a more specific element type. However, if the list is mutable, you cannot do that.
In the upcoming sections, we’ll explore these concepts in the context of generic classes. We’ll also examine why List and MutableList differ regarding their type arguments. But before that, let’s discuss the concepts of type and subtype.
Difference between Classes, types, and subtypes
In Kotlin, the type of a variable specifies the possible values it can hold. The terms “type” and “class” are sometimes used interchangeably, but they have distinct meanings. In the case of a non-generic class, the class name can be used directly as a type. For example, var x: String declares a variable that can hold instances of the String class. However, the same class name can also be used to declare a nullable type, such as var x: String?which indicates that the variable can hold either a String or null. So each Kotlin class can be used to construct at least two types.
When it comes to generic classes, things get more complex. To form a valid type, you need to substitute a specific type as a type argument for the class’s type parameter. For example, List is a class, not a type itself, but the following substitutions are valid types: List<Int>, List<String?>, List<List<String>>, and so on. Each generic class can generate an infinite number of potential types.
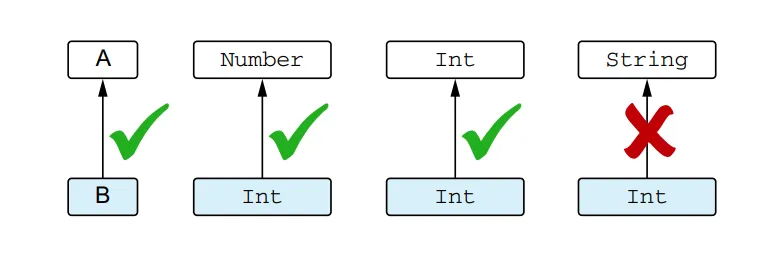
To discuss the relationship between types, it’s important to understand the concept of subtyping. Type B is considered a subtype of type A if you can use a value of type B wherever a value of type A is expected. For example, Int is a subtype of Number, but Int is not a subtype of String. Note that a type is considered a subtype of itself. The term “supertype” is the opposite of subtype: if A is a subtype of B, then B is a supertype of A.
B is a subtype of A if you can use it when A is expected
Understanding subtype relationships is crucial because the compiler performs checks whenever you assign a value to a variable or pass an argument to a function. For example:
Storing a value in a variable is only allowed if the value’s type is a subtype of the variable’s type. In this case, since Int is a subtype of Number, the declaration val n: Number = i is valid. Similarly, passing an expression to a function is only allowed if the expression’s type is a subtype of the function’s parameter type. In the example, the type Int of the argument i is not a subtype of the function parameter type String, so the invocation of the f function does not compile.
In simpler cases, subtype is essentially the same as subclass. For example, Int is a subclass of Number, so the Int type is a subtype of the Number type. If a class implements an interface, its type is a subtype of the interface type. For instance, String is a subtype of CharSequence.
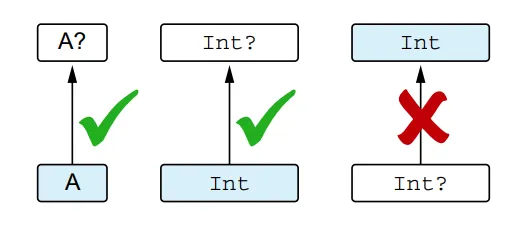
Nullable types introduce a scenario where subtype and subclass differ. A non-null type is a subtype of its corresponding nullable type, but they both correspond to the same class.
A non-null type A is a subtype of nullable A?, but not vice versa
You can store the value of a non-null type in a variable of a nullable type, but not vice versa. For example:
Kotlin
val s: String = "abc"val t: String? = s
In this case, the value of the non-null type String can be stored in a variable of the nullable type String?. However, you cannot assign a nullable type to a non-null type because null is not an acceptable value for a non-null type.
The distinction between subclasses and subtypes becomes particularly important when dealing with generic types. This brings us back to the question from the previous section: is it safe to pass a variable of type List<String> to a function expecting List<Any>? We’ve already seen that treating MutableList<String> as a subtype of MutableList<Any> is not safe. Similarly, MutableList<Any> is not a subtype of MutableList<String> either.
A generic class, such as MutableList, is called invariant on the type parameter if, for any two different types A and B, MutableList<A> is neither a subtype nor a supertype of MutableList<B>. In Java, all classes are invariant, although specific uses of those classes can be marked as non-invariant (as you’ll see soon).
In the previous section, we encountered a class, List, where the subtyping rules are different. The List interface in Kotlin represents a read-only collection. If type A is a subtype of type B, then List<A> is a subtype of List<B>. Such classes or interfaces are called covariant. In the upcoming sections, we’ll explore the concept of covariance in more detail and explain when it’s possible to declare a class or interface as covariant.
Covariance: preserved subtyping relation
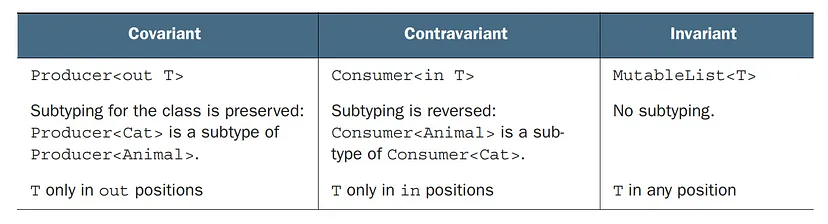
Covariance refers to preserving the subtyping relation between generic classes. In Kotlin, you can declare a class to be covariant on a specific type parameter by using the out keyword before the type parameter’s name.
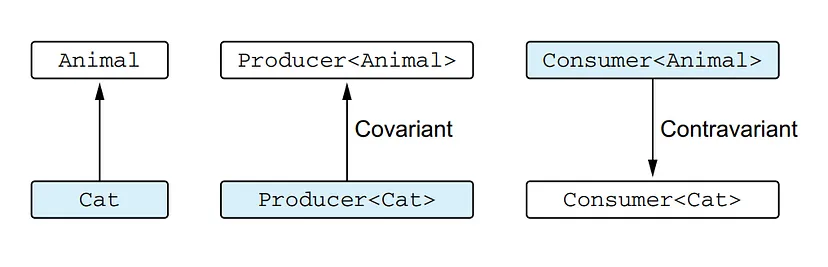
A covariant class is a generic class (we’ll use Producer as an example) for which the following holds: Producer<A> is a subtype of Producer<B> if A is a subtype of B. We say that the subtyping is preserved. For example, Producer<Cat> is a subtype of Producer<Animal> because Cat is a subtype of Animal.
Here’s an example of the Producer interface using the out keyword:
Kotlin
interfaceProducer<outT> {funproduce(): T}
Flexible Function Argument and Return Value Passing
Covariance in Kotlin allows you to pass values of a class as function arguments and return values, even when the type arguments don’t exactly match the function definition. This means that you can use a more specific type as a substitute for a more generic type.
Suppose we have a hierarchy of classes involving Animal, where Cat is a subclass of Animal. We also have a generic interface called Producer, which represents a producer of objects of type T. We’ll make the Producer interface covariant by using the out keyword on the type parameter.
Kotlin
interfaceProducer<outT> {funproduce(): T}
Now, let’s define a class AnimalProducer that implements the Producer interface for the Animal type:
Since Cat is a subtype of Animal, we can also use CatProducer wherever a Producer<Animal> is expected. This is possible because we declared the Producer interface as covariant.
Now, let’s see how covariance allows us to pass these producers as function arguments and return values:
funmain() {val animalProducer = AnimalProducer()val catProducer = CatProducer()feedAnimal(animalProducer) // Passes an AnimalProducer, which is a Producer<Animal>feedAnimal(catProducer) // Passes a CatProducer, which is also a Producer<Animal>}
In the feedAnimal function, we expect a Producer<Animal> as an argument. With covariance, we can pass both AnimalProducer and CatProducer instances because Producer<Cat> is a subtype of Producer<Animal> due to the covariance declaration.
This demonstrates how covariance allows you to treat more specific types (Producer<Cat>) as if they were more generic types (Producer<Animal>) when it comes to function arguments and return values.
BTW, How covariance guarantees type safety?
Suppose we have a class hierarchy involving Animal, where Cat is a subclass of Animal. We also have a Herd class that represents a group of animals.
Kotlin
openclassAnimal {funfeed() { /* feeding logic */ }}classHerd<T : Animal> { // The type parameter isn’t declared as covariantval size: Intget() = /* calculate the size of the herd */operatorfunget(i: Int): T { /* get the animal at index i */ }}funfeedAll(animals: Herd<Animal>) {for (i in0 until animals.size) { animals[i].feed() }}
Now, suppose you have a function called takeCareOfCats, which takes a Herd<Cat> as a parameter and performs some operations specific to cats.
Kotlin
classCat : Animal() {funcleanLitter() { /* clean litter logic */ }}funtakeCareOfCats(cats: Herd<Cat>) {for (i in0 until cats.size) { cats[i].cleanLitter()// feedAll(cats) // This line would cause a type-mismatch error, Error: inferred type is Herd<Cat>, but Herd<Animal> was expected }}
In this case, if you try to pass the cats herd to the feedAll function, you’ll get a type-mismatch error during compilation. This happens because you didn’t use any variance modifier on the type parameter T in the Herd class, making the Herd<Cat> incompatible with Herd<Animal>. Although you could use an explicit cast to overcome this issue, it is not a recommended approach.
To make it work correctly, you can make the Herd class covariant by using the out keyword on the type parameter:
Kotlin
classHerd<outT : Animal> { // The T parameter is now covariant.// ...}funtakeCareOfCats(cats: Herd<Cat>) {for (i in0 until cats.size) { cats[i].cleanLitter() }feedAll(cats) // Now this line works because of covariance, You don’t need a cast.
By marking the type parameter as covariant, you ensure that the subtyping relation is preserved, and T can only be used in \”out\” positions. This guarantees type safety and allows you to pass a Herd<Cat> where a Herd<Animal> is expected.
Usage of covariance
Covariance in Kotlin allows you to make a class covariant on a type parameter, but it also imposes certain constraints to ensure type safety. The type parameter can only be used in “out” positions, which means it can produce values of that type but not consume them.
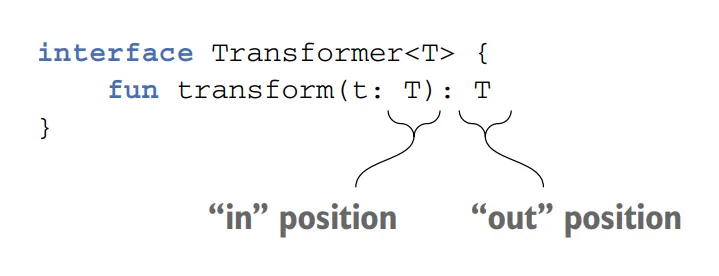
You can’t make any class covariant: it would be unsafe. Making the class covariant on a certain type parameter constrains the possible uses of this type parameter in the class. To guarantee type safety, it can be used only in so-called out positions, meaning the class can produce values of type T but not consume them. Uses of a type parameter in declarations of class members can be divided into “in” and “out” positions.
Let’s consider a class that declares a type parameter T and contains a function that uses T. We say that if T is used as the return type of a function, it’s in the out position. In this case, the function produces values of type T. If T is used as the type of a function parameter, it’s in the in position. Such a function consumes values of type T.
The function parameter type is called in position, and the function return type is called out position
The out keyword on a type parameter of the class requires that all methods using T have T only in “out” positions and not in “in” positions. This keyword constrains possible use of T, which guarantees safety of the corresponding subtype relation.
Let’s understand this with some examples. Consider the Herd class, which is declared as Herd<out T : Animal>. The type parameter T is used only in the return value of the get method. This is an “out” position, and it is safe to declare the class as covariant. For instance, Herd<Cat> is considered a subtype of Herd<Animal> because Cat is a subtype of Animal.
Kotlin
classHerd<outT : Animal> {val size: Int = ...operatorfunget(i: Int): T { ... } // Uses T as the return type}
Similarly, the List<T> interface in Kotlin is covariant because it only defines a get method that returns an element of type T. Since there are no methods that store values of type T, it is safe to declare the class as covariant.
Kotlin
interfaceList<outT> : Collection<T> {operatorfunget(index: Int): T// Read-only interface that defines only methods that return T (so T is in the “out” position)// ...}
You can also use the type parameter T as a type argument in another type. For example, the subList method in the List interface returns a List<T>, and T is used in the “out” position.
Kotlin
interfaceList<outT> : Collection<T> {funsubList(fromIndex: Int, toIndex: Int): List<T> // Here T is in the “out” position as well.// ...}
However, you cannot declare MutableList<T> as covariant on its type parameter because it contains methods that both consume and produce values of type T. Therefore, T appears in both “in” and “out” positions, and making it covariant would be unsafe.
Kotlin
interfaceMutableList<T> : List<T>, MutableCollection<T> { //MutableList can’t be declared as covariant on T …overridefunadd(element: T): Boolean// … because T is used in the “in” position.}
The compiler enforces this restriction. It would report an error if the class was declared as covariant: Type parameter T is declared as ‘out’ but occurs in ‘in’ position.
Constructor Parameters and Variance
In Kotlin, constructor parameters are not considered to be in the “in” or “out” position when it comes to variance. This means that even if a type parameter is declared as “out,” you can still use it in a constructor parameter declaration without any restrictions.
The type parameter T is declared as “out” but it can still be used in the constructor parameter vararg animals: T without any issues. The variance protection is not applicable to the constructor because it is not a method that can be called later, so there are no potentially dangerous method calls that need to be restricted.
However, if you use the val or var keyword with a constructor parameter, it declares a property with a getter and setter (if the property is mutable). In this case, the type parameter T is used in the “out” position for a read-only property and in both “out” and “in” positions for a mutable property.
Here, the type parameter T cannot be marked as “out” because the class contains a setter for the leadAnimal property, which uses T in the “in” position. The presence of a setter makes it necessary to consider both “out” and “in” positions for the type parameter.
It’s important to note that the position rules for variance in Kotlin only apply to the externally visible API of a class, such as public, protected, and internal members. Parameters of private methods are not subject to the “in” or “out” position rules. The variance rules are in place to protect a class from misuse by external clients and do not affect the implementation of the class itself.
In this case, the Herd class can safely be made covariant on T because the leadAnimal property has been made private. The private visibility means that the property is not accessible from external clients, so the variance rules for the public API do not apply.
Contravariance: reversed subtyping relation
Contravariance is the opposite of covariance and it can be understood as a mirror image of covariance. When a class is contravariant, the subtyping relationship between its type arguments is the reverse of the subtyping relationship between the classes themselves.
To illustrate this concept, let’s consider the example of the Comparator interface. This interface has a single method called compare, which takes two objects and compares them:
Kotlin
interfaceComparator<inT> {funcompare(e1: T, e2: T): Int { ... }}
In this case, you’ll notice that the compare method only consumes values of type T. This means that the type parameter T is used in “in” positions only, indicating that it is a contravariant type. To indicate contravariance, the “in” keyword is placed before the declaration of T.
A comparator defined for values of a certain type can, of course, compare the values of any subtype of that type. For example, if you have a Comparator, you can use it to compare values of any specific type.
Kotlin
val anyComparator = Comparator<Any> { e1, e2 -> e1.hashCode() - e2.hashCode() }val strings: List<String> = listOf("abc","xyz")strings.sortedWith(anyComparator) // You can use the comparator for any objects to compare specific objects, such as strings.
Here, the sortedWith function expects a Comparator (a comparator that can compare strings), and it’s safe to pass one that can compare more general types. If you need to perform comparisons on objects of a certain type, you can use a comparator that handles either that type or any of its supertypes. This means Comparator<Any> is a subtype of Comparator<String>, where Any is a supertype of String. The subtyping relation between comparators for two different types goes in the opposite direction of the subtyping relation between those types.
What is contravariance?
A class that is contravariant on the type parameter is a generic class (let’s consider Consumer<T> as an example) for which the following holds: Consumer<A> is a subtype of Consumer<B> if B is a subtype of A. The type arguments A and B changed places, so we say the subtyping is reversed. For example, Consumer<Animal> is a subtype of Consumer<Cat>.
In simple words, contravariance in Kotlin means that the subtyping relationship between two generic types is reversed compared to the normal inheritance hierarchy. If B is a subtype of A, then a generic class or interface that is contravariant on its type parameter T will have the relationship ClassName<A> is a subtype of ClassName<B>.
For a covariant type Producer, the subtyping is preserved, but for a contravariant type Consumer, the subtyping is reversed
Here, we see the difference between the subtyping relation for classes that are covariant and contravariant on a type parameter. You can see that for the Producer class, the subtyping relation replicates the subtyping relation for its type arguments, whereas for the Consumer class, the relation is reversed.
The “in” keyword means values of the corresponding type are passed in to methods of this class and consumed by those methods. Similar to the covariant case, constraining use of the type parameter leads to the specific subtyping relation. The “in” keyword on the type parameter T means the subtyping is reversed and T can be used only in “in” positions.
Covariance and Contravariance in Kotlin’s Function Types
In Kotlin, a class or interface can be covariant on one type parameter and contravariant on another. One of the classic examples of this is the Function interface. Let’s take a look at the declaration of the Function1 interface, which represents a one-parameter function:
To make the notation more readable, Kotlin provides an alternative syntax (P) -> R to represent Function1<P, R>. In this syntax, you’ll notice that P (the parameter type) is used only in the in position and is marked with the in keyword, while R (the return type) is used only in the out position and is marked with the out keyword.
This means that the subtyping relationship for the function type is reversed for the first type argument (P) and preserved for the second type argument (R).
For example, let’s say you have a higher-order function called enumerateCats that accepts a lambda function taking a Cat parameter and returning a Number:
Kotlin
funenumerateCats(f: (Cat) -> Number) { ... }
Now, suppose you have a function called getIndex defined in the Animal class that returns an Int. You can pass Animal::getIndex as an argument to enumerateCats:
Kotlin
funAnimal.getIndex(): Int = ...enumerateCats(Animal::getIndex) // This code is legal in Kotlin. Animal is a supertype of Cat, and Int is a subtype of Number
In this case, the Animal::getIndex function is accepted because Animal is a supertype of Cat, and Int is a subtype of Number, the function type’s subtyping relationship allows it.
The function (T) -> R is contravariant on its argument and covariant on its return type
This illustration demonstrates how subtyping works for function types. The arrows indicate the subtyping relationship.
Use-site variance: specifying variance for type occurrences
To understand use-site variance better, you first need to understand declaration-site variance. In Kotlin, the ability to specify variance modifiers on class declarations provides convenience and consistency because these modifiers apply to all places where the class is used. This concept is known as a declaration-site variance.
Declaration-site variance in Kotlin is achieved by using variance modifiers on type parameters when defining a class. As you already knows there are two main variance modifiers:
out (covariant): Denoted by the out keyword, it allows the type parameter to be used as a return type or read-only property. It specifies that the type parameter can only occur in the “out” position, meaning it can only be returned from functions or accessed in a read-only manner.
in (contravariant): Denoted by the in keyword, it allows the type parameter to be used as a parameter type. It specifies that the type parameter can only occur in the “in” position, meaning it can only be passed as a parameter to functions.
By specifying these variance modifiers on type parameters, you define the variance behavior of the class, and it remains consistent across all usages of the class.
On the other hand, Java handles variance differently through use-site variance. In Java, each usage of a type with a type parameter can specify whether the type parameter can be replaced with its subtypes or supertypes using wildcard types (? extends and ? super). This means that at each usage point of the type, you can decide the variance behavior.
It’s important to note that while Kotlin supports declaration-site variance with the out and in modifiers, it also provides a certain level of use-site variance through the out and in projection syntax (out T and in T). These projections allow you to control the variance behavior in specific usage points within the code.
Declaration-site variance in Kotlin Vs. Java wildcards
In Kotlin, declaration-site variance allows for more concise code because variance modifiers are specified once on the declaration of a class or interface. This means that clients of the class or interface don’t have to think about the variance modifiers. The convenience of declaration-site variance is that the variance behavior is determined at the point of declaration and remains consistent throughout the codebase.
On the other hand, in Java, wildcards are used to handle variance at the use site. To create APIs that behave according to users’ expectations, the library writer has to use wildcards extensively. For example, in the Java 8 standard library, wildcards are used on every use of the Function interface. This can lead to code like Function<? super T, ? extends R> in method signatures.
To illustrate the declaration of the map method in the Stream interface in Java :
In the Java code, wildcards are used in the declaration of the map method to handle the variance of the function argument. This can make the code less readable and more cumbersome, especially when dealing with complex type hierarchies.
In contrast, the Kotlin code uses declaration-site variance, specifying the variance once on the declaration makes the code much more concise and elegant.
BTW, How does use-site variance work in Kotlin?
Kotlin supports use-site variance, you can specify variance at the use site, which means you can indicate the variance for a specific occurrence of a type parameter, even if it can’t be declared as covariant or contravariant in the class declaration. Let’s break down the concepts and see how use-site works.
In Kotlin, many interfaces, like MutableList, are not covariant or contravariant by default because they can both produce and consume values of the types specified by their type parameters. However, in certain situations, a variable of that type may be used only as a producer or only as a consumer.
Consider the function copyData that copies elements from one collection to another:
Kotlin
fun <T> copyData(source: MutableList<T>, destination: MutableList<T>) {for (item in source) { destination.add(item) }}
In this function, both the source and destination collections have an invariant type. However, the source collection is only used for reading, and the destination collection is only used for writing. In this case, the element types of the collections don’t need to match exactly.
To make this function work with lists of different types, you can introduce a second generic parameter:
Kotlin
fun <T : R, R> copyData(source: MutableList<T>, destination: MutableList<R>) {for (item in source) { destination.add(item) }}
In this modified version, you declare two generic parameters representing the element types in the source and destination lists. The source element type (T) should be a subtype of the elements in the destination list (R).
However, Kotlin provides a more elegant way to express this using use-site variance. If the implementation of a function only calls methods that have the type parameter in the “out” position (as a producer) or only in the “in” position (as a consumer), you can add variance modifiers to the particular usages of the type parameter in the function definition.
For example, you can modify the copyData function as follows:
Kotlin
fun <T> copyData(source: MutableList<outT>, destination: MutableList<T>) {for (item in source) { destination.add(item) }}
In this version, you specify the out modifier for the source parameter, which means it’s a projected (restricted) MutableList. You can only call methods that return the generic type parameter (T) or use it in the “out” position. The compiler prohibits calling methods where the type parameter is used as an argument (“in” position).
When using use-site variance in Kotlin, there are limitations on the methods that can be called on a projected type. If you are using a projected type, you may not be able to call certain methods that require the type parameter to be used as an argument (“in” position) :
Kotlin
val list: MutableList<outNumber> = ..list.add(42) // Error: Out-projected type 'MutableList<out Number>' prohibits the use of 'fun add(element: E): Boolean'
Here, list is declared as a MutableList<out Number>, which is an out-projected type. The out projection restricts the type parameter Number to only be used in the “out” position, meaning it can only be used as a return type or read from. You cannot call the add method because it requires the type parameter to be used as an argument (“in” position).
If you need to call methods that are prohibited by the projection, you should use a regular type instead of a projection. In this case, you can use MutableList<Number> instead of MutableList<out Number>. By using the regular type, you can access all the methods available for that type.
Regarding the concept of using the in modifier, it indicates that in a particular location, the corresponding value acts as a consumer, and the type parameter can be substituted with any of its supertypes. This is similar to the contravariant position in Java’s bounded wildcards.
For example, the copyData function can be rewritten using an in-projection:
Kotlin
fun <T> copyData(source: MutableList<T>, destination: MutableList<inT>) {for (item in source) { destination.add(item) }}
In this version, the destination parameter is projected with the in modifier, indicating that it can consume elements of type T or any of its supertypes. This allows you to copy elements from the source list to a destination list with a broader type.
It’s important to note that use-site variance declarations in Kotlin correspond directly to Java’s bounded wildcards. MutableList<out T> in Kotlin is equivalent to MutableList<? extends T> in Java, while the in-projected MutableList<in T> corresponds to Java’s MutableList<? super T>.
Use-site projections in Kotlin can help widen the range of acceptable types and provide more flexibility when working with generic types, without the need for separate covariant or contravariant interfaces.
Star projection: using * instead of a type argument
In Kotlin, star projection is a syntax that allows you to indicate that you have no information about a generic argument. It is represented by the asterisk (*) symbol. Let’s explore the semantics of star projections in more detail.
When you use star projection, such as List<*>, it means you have a list of elements of an unknown type. It’s important to note that MutableList<*> is not the same as MutableList<Any?>. The former represents a list that contains elements of a specific type, but you don’t know what type it is. You can’t put any values into the list because it may violate the expectations of the calling code. However, you can retrieve elements from the list because you know they will match the type Any?, which is the supertype of all Kotlin types.
Here’s an example to illustrate this:
Kotlin
val list: MutableList<Any?> = mutableListOf('a', 1, "qwe")val chars = mutableListOf('a', 'b', 'c')val unknownElements: MutableList<*> = if (Random().nextBoolean()) list else charsunknownElements.add(42) // Error: Adding elements to a MutableList<*> is not allowedprintln(unknownElements.first()) // You can retrieve elements from unknownElements
In this example, unknownElements can be either list or chars based on a random condition. You can’t add any values to unknownElements because its type is unknown, but you can retrieve elements from it using the first() function.
Kotlin
unknownElements.add(42)// Error: Out-projected type 'MutableList<*>' prohibits//the use of 'fun add(element: E): Boolean'
The term “out-projected type” refers to the fact that MutableList<*> is projected to act as MutableList<out Any?>. It means you can safely get elements of type Any? from the list but cannot put elements into it.
For contravariant type parameters, like Consumer<in T>, a star projection is equivalent to <in Nothing>. In this case, you can’t call any methods that have T in the signature on a star projection because you don’t know exactly what it can consume. This is similar to Java’s wildcards (MyType<?> in Java corresponds to MyType<*> in Kotlin).
You can use star projections when the specific information about type arguments is not important. For example, if you only need to read the data from a list or use methods that produce values without caring about their specific types. Here’s an example of a function that takes List<*> as a parameter:
In this case, the printFirst function only reads the first element of the list and doesn’t care about its specific type. Alternatively, you can introduce a generic type parameter if you need more control over the type:
Kotlin
fun <T> printFirst(list: List<T>) {if (list.isNotEmpty()) {println(list.first()) }}
The syntax with star projection is more concise, but it works only when you don’t need to access the exact value of the generic type parameter.
Now let’s consider an example using a type with a star projection and common traps that you may encounter. Suppose you want to validate user input using an interface called FieldValidator. It has a type parameter declared as contravariant (in T). You also have two validators for String and Int inputs.
If you want to store all validators in the same container and retrieve the right validator based on the input type, you might try using a map. However, using FieldValidator<*> as the value type in the map can lead to difficulties. You won’t be able to validate a string with a validator of type FieldValidator<*> because the compiler doesn’t know the specific type of the validator.
Kotlin
val validators = mutableMapOf<KClass<*>, FieldValidator<*>>()validators[String::class] = DefaultStringValidatorvalidators[Int::class] = DefaultIntValidatorvalidators[String::class]!!.validate("") // Error: Cannot call validate() on FieldValidator<*>
In this case, you will encounter a similar error as before, indicating that it’s unsafe to call a method with the type parameter on a star projection. One way to work around this is by explicitly casting the validator to the desired type, but this is not recommended as it is not type-safe.
Kotlin
val stringValidator = validators[String::class] as FieldValidator<String>println(stringValidator.validate("")) // Output: false
This code compiles, but it’s not safe because the cast is unchecked and may fail at runtime if the generic type information is erased.
A safer approach is to encapsulate the access to the map and provide type-safe methods for registration and retrieval. This ensures that only the correct validators can be registered and retrieved. Here’s an example using an object called Validators:
In this example, the Validators object controls all access to the map, ensuring that only correct validators can be registered and retrieved. The code emits a warning about the unchecked cast, but the guarantees provided by the Validators object make sure that no incorrect use can occur.
This pattern of encapsulating unsafe code in a separate place helps prevent misuse and makes the usage of a container safe. It’s worth noting that this pattern is not specific to Kotlin and can be applied in Java as well.
Conclusion
Understanding Kotlin variance helps you write safer, more flexible code. By using out for producers, in for consumers, and keeping generics invariant when necessary, you ensure your programs remain type-safe and efficient.
Next time you see out, in, or *, you’ll know exactly what’s happening and why!
Kotlin is well known for its concise syntax, expressive features, and seamless support for functional programming. One of its powerful yet often misunderstood features is inline functions. If you’ve ever worked with higher-order functions in Kotlin, you’ve probably encountered situations where performance becomes a concern due to lambda expressions. This is where inline functions in Kotlin come to the rescue!
In this guide, we’ll break down everything you need to know about inline functions, why they exist, how they work and improve performance, and when (or when not) to use them. Whether you’re a beginner or an experienced developer looking for a refresher, this post will help you grasp inline functions in Kotlin with clear explanations and practical examples.
What Are Inline Functions in Kotlin?
Before diving into the details, let’s start with a simple definition.
In Kotlin, an inline function is a function whose body is copied (or “inlined”) at every place it’s called during compilation. This eliminates the overhead of function calls, making the code more efficient, especially when working with lambda functions.
In this case, the function greet() is marked as inline, which means that when greet("amol") is called, the compiler replaces it with:
Kotlin
println("Hello, amol!")
This eliminates the function call and directly places the function body in the main() function, improving efficiency.
Why Were Inline Functions Introduced in Kotlin?
In Kotlin, inline functions can help remove the overhead associated with lambdas and improve performance. When you use a lambda expression, it is typically compiled into an anonymous class. This means that each time you use a lambda, an additional class is created. Moreover, if the lambda captures variables, a new object is created for each invocation. As a result, using Lambdas can introduce runtime overhead and make the implementation less efficient compared to directly executing the code.
To mitigate this performance impact, Kotlin provides the inline modifier for functions. When you mark a function with inline, the compiler replaces every call to that function with the actual code implementation, instead of generating a function call. This way, the overhead of creating additional classes and objects is avoided.
Let’s see a simple example to illustrate this:
Kotlin
inlinefunmultiply(a: Int, b: Int): Int {return a * b}funmain() {val result = multiply(2, 3)println(result)}
In this example, the multiply function is marked as inline. When you call multiply(2, 3), the compiler replaces the function call with the actual code of the multiply function:
Kotlin
funmain() {val result = 2 * 3// only for illustrating purposes, later we will see how it actually works println(result)}
This allows the code to execute the multiplication directly without the overhead of a function call.
Let’s see one more example to illustrate this:
Kotlin
inlinefunperformOperation(a: Int, b: Int, operation: (Int, Int) -> Int): Int {returnoperation(a, b)}funmain() {val result = performOperation(5, 3) { x, y -> x + y }println(result)}
In this example, the performOperation function is marked as inline. It takes two integers, a and b, and a lambda expression representing an operation to be performed on a and b. When performOperation is called, instead of generating a function call, the compiler directly replaces the code inside the function with the code from the lambda expression.
So, in the main function, the call to performOperation(5, 3) will be replaced with the actual code 5 + 3. This eliminates the overhead of creating an anonymous class and improves performance.
BTW, How inlining works actually?
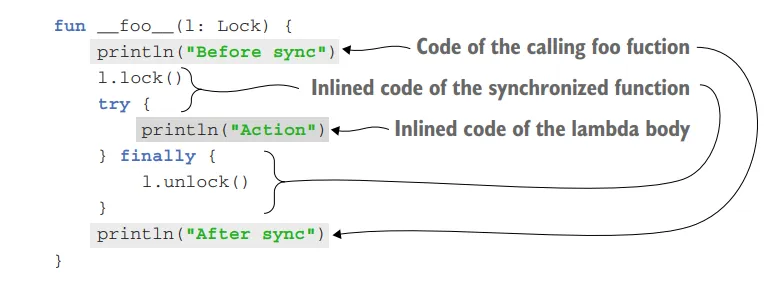
When you declare a function as inline in Kotlin, its body is substituted directly into the places where the function is called, instead of being invoked as a separate function. This substitution process is known as inlining.
Let’s take a look at an example to understand it more:
In this example, the synchronized function is declared as inline. It takes a Lock object and a lambda action as parameters. The function locks the Lock object, executes the provided action lambda, and then releases the lock.
When you use the synchronized function, the code generated for every call to it is similar to a synchronized statement in Java.
In this case, the lambda expression passed to synchronized is substituted directly into the code of the calling function. The bytecode generated from the lambda becomes part of the definition of the calling function and is not wrapped in an anonymous class implementing a function interface.
Not inlined Case (passing lambda as a parameter)
It’s worth noting that if you call an inline function and pass a parameter of a function type from a variable, rather than a lambda directly, the body of the inline function is not inlined.
Here’s an example:
Kotlin
classLockOwner(val lock: Lock) {funrunUnderLock(body: () -> Unit) {synchronized(lock, body) // A variable of a function type is passed as an argument, not a lambda. }}
In this case, the lambda’s code is not available at the site where the inline function is called, so it cannot be inlined. The body of the runUnderLock function is not inlined because there’s no lambda at the invocation. Only the body of the synchronized function is inlined; the lambda is called as usual. The runUnderLock function will be compiled to bytecode similar to the following function:
Kotlin
classLockOwner(val lock: Lock) {fun__runUnderLock__(body: () -> Unit) { // This function is similar to the bytecode the real runUnderLock is compiled to lock.lock()try {body() // The body isn’t inlined, because there’s no lambda at the invocation. } finally { lock.unlock() } }}
Here, the body of the runUnderLock function cannot be inlined because the lambda is passed as a parameter from a variable (body) rather than directly providing a lambda expression.
Suppose when you pass a lambda as a parameter directly, like this:
Kotlin
lockOwner.runUnderLock {// code block A}
The body of the inline function runUnderLock can be inlined, as the compiler knows the exact code to replace at the call site.
However, when you pass a lambda from a variable, like this:
Kotlin
val myLambda = {// code block A}lockOwner.runUnderLock(myLambda)
The body of the inline function cannot be inlined because the compiler doesn’t have access to the code inside the lambda (myLambda) at the call site. It would require the compiler to know the contents of the lambda in order to inline it.
In such cases, the function call behaves like a regular function call, and the body of the function is not copied to the call site. Instead, the lambda is passed as an argument to the function and executed within the function’s context.
So, suppose even though the runUnderLock function is marked as inline, the body of the function won’t be inlined because the lambda is passed as a parameter from a variable.
What about multiple inlining?
If you have two uses of an inline function in different locations with different lambdas, each call site will be inlined independently. The code of the inline function will be copied to both locations where you use it, with different lambdas substituted into it.
If you have multiple calls to the inline function with different lambdas, like this:
Each call site will be inlined independently. The code of the inline function will be copied to both locations where you use it, with different lambdas substituted into it. This allows the compiler to inline the code at each call site separately.
Restrictions on inline functions
When a function is declared as inline in Kotlin, the body of the lambda expression passed as an argument is substituted directly into the resulting code. However, this substitution imposes certain restrictions on how the corresponding parameter can be used in the function body.
If the parameter is called directly within the function body, the code can be easily inlined. But if the parameter is stored for later use, the code of the lambda expression cannot be inlined because there must be an object that contains this code.
In general, the parameter can be inlined if it’s called directly or passed as an argument to another inline function. If it’s used in a way that prevents inlining, such as storing it for later use, the compiler will prohibit the inlining and show an error message stating “Illegal usage of inline-parameter.”
Let’s consider an example with the Sequence.map function:
Kotlin
fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {returnTransformingSequence(this, transform)}
The map function doesn’t call the transform function directly. Instead, it passes the transform function as a constructor parameter to a class (TransformingSequence) that stores it in a property. To support this, the lambda passed as the transform argument needs to be compiled into the standard non-inline representation, which is an anonymous class implementing a function interface.
Why Use Inline Functions in Kotlin?
Inline functions are particularly useful in scenarios where:
Performance Optimization: Reduces function call overhead, making execution faster.
Avoiding Anonymous Object Allocations: Reduces memory allocations by avoiding extra objects for lambdas.
When Not to Use Inline Functions
Although inline functions in Kotlin are beneficial, overusing them can lead to code bloat (increased code size). Here are some situations where you should avoid using inline functions:
Large Function Bodies: If the function body is large, inlining it multiple times will increase the APK size.
Non-Performance Critical Code: For functions that don’t need optimization, inlining may be unnecessary.
Recursion: Recursive inline functions are not allowed in Kotlin since they would cause infinite expansion.
Performance Benefits of Inline Functions
The key benefits of inline functions in Kotlin include:
Reduces function call overhead – No need for extra method calls.
Eliminates unnecessary object creation – No wrapper objects for lambda functions.
Improves performance for high-order functions – Especially beneficial when passing multiple lambdas.
Inline functions in Kotlin are a powerful tool for improving performance, especially when working with higher-order functions and lambda expressions. By eliminating function call overhead and avoiding unnecessary object creation, they help make Kotlin code more efficient.
However, inline functions should be used carefully. Overuse can lead to increased bytecode size, making your application slower rather than faster. The key is to strike a balance—use them where they add value but avoid excessive inlining.