
Machine Learning (ML) has emerged as a transformative force in the realm of technology, reshaping the way we approach complex problems and unlocking unprecedented possibilities. In this blog, we will embark on a comprehensive journey through the fascinating world of Machine Learning, exploring its types, key algorithms like backpropagation and gradient descent, and groundbreaking innovations such as ImageNet, LSvRC, and AlexNet.
What is Artificial Intelligence (AI)?
Artificial Intelligence Refers to the simulation of human intelligence Mimicking the intelligence or behavioral pattern of humans or any other living entity.

What is Machine Learning ?
Machine learning is a subfield of artificial intelligence (AI) that focuses on the development of algorithms and statistical models that enable computers to perform tasks without explicit programming. The primary goal of machine learning is to enable computers to learn and improve from experience.

The term ‘machine learning’ originated in the mid-20th century, with Arthur Samuel’s 1959 definition describing it as “the ability to learn without being explicitly programmed.” Machine learning, a subset of artificial intelligence (AI), enhances a computer’s capacity to learn and autonomously adapt as it encounters new and dynamic data. A notable application is Facebook’s news feed, employing machine learning to personalize each user’s feed according to their preferences.
In traditional programming, humans write explicit instructions for a computer to perform a task. In contrast, machine learning allows computers to learn from data and make predictions or decisions without being explicitly programmed for a particular task. The learning process involves identifying patterns and relationships within the data, allowing the system to make accurate predictions or decisions when exposed to new, unseen data.
Types of Machine Learning
There are several types of machine learning, including:
Supervised Learning:
- Definition: In supervised learning, the algorithm is trained on a labeled dataset, where the input data is paired with the corresponding output or target variable. The goal is to make accurate predictions on new, unseen data.
- Examples:
- Linear Regression: Predicts a continuous output based on input features.
- Support Vector Machines (SVM): Classifies data points into different categories using a hyperplane.
- Decision Trees and Random Forests: Builds a tree-like structure to make decisions based on input features.
Unsupervised Learning:
- Definition: Unsupervised learning deals with unlabeled data, and the algorithm tries to find patterns, relationships, or structures in the data without explicit guidance. Clustering and dimensionality reduction are common tasks in unsupervised learning.
- Examples:
- Clustering Algorithms (K-means, Hierarchical clustering): Group similar data points together.
- Principal Component Analysis (PCA): Reduces the dimensionality of the data while retaining important information.
- Generative Adversarial Networks (GANs): Generates new data instances that resemble the training data.
Semi-Supervised Learning:
- Definition: A combination of supervised and unsupervised learning, where the algorithm is trained on a dataset that contains both labeled and unlabeled data.
- Examples:
- Self-training: The model is initially trained on labeled data, and then it labels unlabeled data and includes it in the training set.
Reinforcement Learning:
- Definition: Reinforcement learning involves an agent learning to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties based on its actions.
- Examples:
- Q-Learning: A model-free reinforcement learning algorithm that aims to learn a policy, which tells the agent what action to take under what circumstances.
- Deep Q Network (DQN): Combines Q-learning with deep neural networks for more complex tasks.
- Policy Gradient Methods: Learn a policy directly without explicitly computing a value function.
Deep Learning:
- Definition: Deep learning involves neural networks with multiple layers (deep neural networks) to learn complex representations of data.
- Examples:
- Convolutional Neural Networks (CNN): Effective for image and video analysis.
- Recurrent Neural Networks (RNN): Suitable for sequential data, such as time series and natural language.
ML and data-driven artificial intelligence
Machine learning (ML) encompasses a diverse array of techniques designed to automate the learning process of algorithms. This marks a departure from earlier approaches, where enhancements in performance relied on human adjustments or additions to the expertise encoded directly into the algorithm. While the foundational concepts of these methods date back to the era of symbolic AI, their widespread application gained momentum after the turn of the century, sparking the contemporary resurgence of the field.
In ML, algorithms typically refine themselves through training on data, leading to the characterization of this approach as data-driven AI. The practical application of these methods has experienced significant growth over the past decade. Although the techniques themselves are not inherently new, the pivotal factor behind recent ML advancements is the unprecedented surge in the availability of data. The remarkable expansion of data-driven AI is, in essence, fueled by data.
ML algorithms often autonomously identify patterns and leverage learned insights to make informed statements about data. Different ML approaches are tailored to specific tasks and contexts, each carrying distinct implications. The ensuing sections offer a comprehensible introduction to key ML techniques. The initial segment elucidates deep learning and the pre-training of software, followed by an exploration of various concepts related to data, underscoring the indispensable role of human engineers in designing and fine-tuning ML systems. The concluding sections demonstrate how ML algorithms are employed to comprehend the world and even generate language, images, and sounds.
Machine Learning Algorithms
Just as a skilled painter wields their brush and a sculptor shapes clay, machine learning algorithms are the artist’s tools for crafting intelligent systems. In this segment, we’ll explore two of the most essential algorithms that drive ML’s learning process: Backpropagation and Gradient Descent.
Backpropagation
Backpropagation is a fundamental algorithm in the training of neural networks. It involves iteratively adjusting the weights of connections in the network based on the error between predicted and actual outputs. This process is crucial for minimizing the overall error and improving the model’s performance.
Imagine an ANN as a student learning to solve math problems. The student is given a problem (the input), works through it (the hidden layers), and writes down an answer (the output). If the answer is wrong, the teacher shows the correct answer (the labeled data) and points out the mistakes. The student then goes back through their work step-by-step to figure out where they went wrong and fix those steps for the next problem. This is similar to how backpropagation works in an ANN.
Backpropagation focuses on modifying the neurons within the ANN. Commencing with the previously outlined procedure, an input signal traverses the hidden layer(s) to the output layer, producing an output signal. The ensuing step involves computing the error by contrasting the actual output with the anticipated output based on labeled data. Subsequently, neurons undergo adjustments to diminish the error, enhancing the accuracy of the ANN’s output. This corrective process initiates at the output layer, wielding more influence, and then ripples backward through the hidden layer(s). The term “backpropagation” aptly describes this phenomenon as the error correction retroactively propagates through the ANN.
In theory, one could calculate the error for every conceivable Artificial Neural Network (ANN) by generating a comprehensive set of ANNs with all possible neuron combinations. Each ANN in this exhaustive set would be tested against labeled data, and the one exhibiting the minimal error would be chosen. However, practical constraints arise due to the sheer multitude of potential configurations, rendering this exhaustive approach unfeasible. AI engineers must adopt a more discerning strategy for an intelligent search aimed at identifying the ANN with the lowest error, and this is where gradient descent comes into play.
Gradient Descent
Gradient descent is an optimization algorithm used to minimize the error in a model by adjusting its parameters. It involves iteratively moving in the direction of the steepest decrease in the error function. This process continues until a minimum (or close approximation) is reached.
Imagine an AI engineer as a hiker trying to find the lowest point in a foggy valley. They can’t see the whole valley at once, so they have to feel their way around, step by step. They start at a random spot and check the slope in different directions. If they feel a steeper slope downhill, they take a step in that direction. They keep doing this, always moving towards lower ground, until they find the lowest point they can. This is basically how gradient descent works in AI.
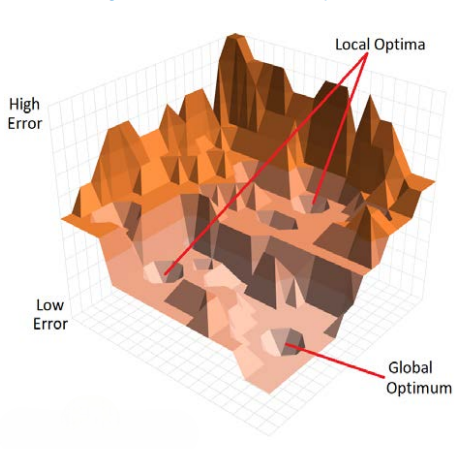
Imagine a graphical representation of every conceivable ANN, where each point denotes one ANN and the elevation signifies its error—a landscape of errors, illustrated in the above figure. Gradient descent is a technique designed to navigate this error landscape and pinpoint the ANN with the least error, even without a comprehensive map. Analogously, it is likened to a hiker navigating a foggy mountain. The hiker, limited to one-meter visibility in each direction, strategically evaluates the steepest descent, moves in that direction, reassesses, and repeats the process until reaching the base. Similarly, an ANN is created at a random point on the error landscape, and its error is calculated along with adjustments representing nearby positions on the landscape. The most promising adjustment guides the ANN in the optimal direction, and this iterative process continues until the best solution is achieved.
While this algorithm may identify the global optimum, it is not flawless. Similar to the hiker potentially getting stuck in a recess on the mountain, the algorithm might settle for a ‘local optimum,’ an imperfect solution it perceives as optimal in its immediate surroundings. To mitigate this, the process is repeated multiple times, commencing from different points and utilizing diverse training data.
Both gradient descent and backpropagation rely on labeled data to compute errors. However, to prevent the algorithm from merely memorizing the training data without gaining the ability to respond to new data, some labeled data is reserved solely for testing rather than training. Yet, the absence of labeled data poses a challenge.
Innovations in Machine Learning
Machine learning has witnessed rapid advancements and innovations in recent years. These innovations span various domains, addressing challenges, and opening up new possibilities. Here are some notable innovations in machine learning:
ImageNet
ImageNet, the largest dataset of annotated images, stands as a testament to the pioneering work of Fei-Fei Li and Jia Deng, who conceived this monumental project at Stanford University in 2009. Comprising a staggering 14 million images meticulously labeled across an expansive spectrum of 22 thousand categories, ImageNet has become a cornerstone in the realm of computer vision and artificial intelligence.
This diverse repository of visual data has transcended its humble beginnings to fuel breakthroughs in image recognition, object detection, and machine learning. Researchers and developers worldwide leverage ImageNet’s rich tapestry of images to train and refine algorithms, pushing the boundaries of what’s possible in the digital landscape.
The profound impact of ImageNet extends beyond its quantitative dimensions, fostering a collaborative spirit among the global scientific community. The ongoing legacy of this monumental dataset continues to inspire new generations of innovators, sparking creativity and ingenuity in the ever-evolving field of computer vision.
Large Scale Visual Recognition Challenge (LSVRC)
The Large Scale Visual Recognition Challenge (LSVRC), an annual event intricately woven into the fabric of ImageNet, serves as a dynamic platform designed to inspire and reward innovation in the field of artificial intelligence. Conceived as a competition to achieve the highest accuracy in specific tasks, the LSVRC has catalyzed rapid advances in key domains such as computer vision and deep learning.
Participants in the challenge, ranging from academic institutions to industry leaders, engage in a spirited race to push the boundaries of AI capabilities. The pursuit of higher accuracy not only fosters healthy competition but also serves as a crucible for breakthroughs, where novel approaches and ingenious methodologies emerge.
Over the years, the LSVRC has become a crucible for testing the mettle of cutting-edge algorithms and models, creating a ripple effect that resonates across diverse sectors. The impact extends far beyond the confines of the challenge, influencing the trajectory of research and development in fields ranging from image recognition to broader applications of artificial intelligence.
The challenge’s influence can be seen in the dynamic interplay between participants, propelling the evolution of computer vision and deep learning. The LSVRC stands as a testament to the power of organized competition in fostering collaboration, accelerating progress, and driving the relentless pursuit of excellence in the ever-expanding landscape of artificial intelligence.
AlexNet
AlexNet, the ‘winner, winner chicken dinner’ of the ImageNet Large Scale Visual Recognition Challenge in 2012, stands as a milestone in the evolution of deep learning and convolutional neural networks (CNNs). Developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, this groundbreaking architecture demonstrated the feasibility of training deep CNNs end-to-end, sparking a paradigm shift in the field of computer vision.
The triumph of AlexNet was not just in winning the competition but in achieving a remarkable 15.3% top-5 error rate, a testament to its prowess in image classification. This breakthrough shattered previous benchmarks, paving the way for a new era in machine learning and inspiring a wave of subsequent innovations.
The impact of AlexNet reverberates through the halls of AI history, as it played a pivotal role in catalyzing further advancements. Its success served as a catalyst for subsequent architectures such as VGGNet, GoogLeNet, ResNet, and more, each pushing the boundaries of model complexity and performance.
Beyond its accolades, AlexNet’s legacy is etched in its contribution to the democratization of deep learning. By showcasing the potential of deep CNNs, it fueled interest and investment in the field, spurring researchers and practitioners to explore new frontiers and applications. AlexNet’s ‘winner’ status not only marked a singular achievement but also ignited a chain reaction, propelling the AI community towards unprecedented heights of innovation and discovery.
AlexNet Block Diagram
AlexNet have eight weight layers, five convolutional layers and three fully connected layers, making it a deep neural network for its time. Modern architectures have since become even deeper with the advent of models like VGGNet, GoogLeNet, and ResNet.
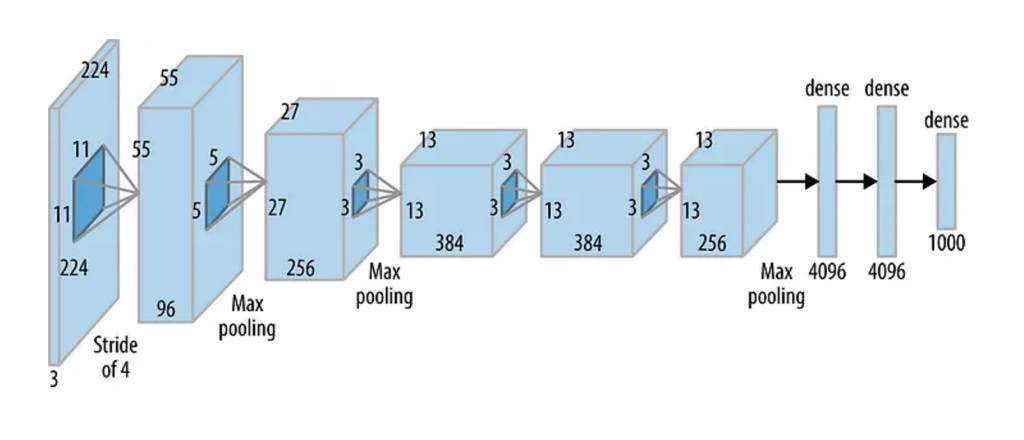
Here are the key components of the AlexNet architecture in a block diagram:
- Input Layer:
- The network takes as input a fixed-size RGB image. In the case of ImageNet, the images are typically 224 pixels in height and width.
- Convolutional Layers:
- The first layer is a convolutional layer with a small filter size (11×11 in the original AlexNet).
- The subsequent convolutional layers use smaller filter sizes (3×3 and 5×5) to capture spatial hierarchies.
- Activation Function (ReLU):
- Rectified Linear Units (ReLU) activation functions are applied after each convolutional layer. ReLU introduces non-linearity to the model.
- Max-Pooling Layers:
- Max-pooling layers follow some of the convolutional layers to downsample the spatial dimensions, reducing the computational load and introducing a degree of translation invariance.
- Local Response Normalization (LRN):
- LRN layers were used in the original AlexNet to normalize the responses across adjacent channels, enhancing the model’s generalization.
- Fully Connected Layers:
- Several fully connected layers follow the convolutional and pooling layers. These layers are responsible for high-level reasoning and making predictions.
- Dropout:
- Dropout layers were introduced to prevent overfitting. They randomly deactivate a certain percentage of neurons during training.
- Softmax Layer:
- The final layer is a softmax activation layer, which outputs a probability distribution over the classes. This layer is used for multi-class classification.
- Output Layer:
- The output layer provides the final predictions for the classes.
- Training and Optimization:
- The network is trained using supervised learning with the backpropagation algorithm and an optimization method such as stochastic gradient descent (SGD).
Conclusion
Machine Learning continues to shape the future of technology, with its diverse types, powerful algorithms, and transformative innovations. From the foundational concepts of supervised and unsupervised learning to the intricacies of backpropagation and gradient descent, the journey into the world of ML is both enlightening and dynamic. As we celebrate milestones like ImageNet, LSvRC, and AlexNet, it becomes evident that the fusion of data-driven AI and machine learning is propelling us into an era where the once-unimaginable is now within our grasp.