
PyTorch, a popular open-source deep learning framework, has gained immense popularity for its flexibility, dynamic computational graph, and user-friendly design. One of its key components, TorchVision, extends PyTorch’s capabilities specifically for computer vision tasks. In this blog post, we will delve into the details of the TorchVision library, exploring its features, functionalities, and how it simplifies the process of building and training deep learning models for various vision tasks.
Understanding TorchVision
Torchvision, an integral component of the PyTorch ecosystem, stands as a dedicated library for handling image and video data. As a versatile toolkit, Torchvision encapsulates key functionalities, including datasets, models (both pretrained and untrained), and transformations. Let’s dive into the core features of Torchvision, understanding its role in simplifying the complexities of working with visual data.
- Datasets: Torchvision’s datasets module serves as a treasure trove of diverse datasets for image and video analysis. Whether it’s classic datasets like MNIST and CIFAR-10 or more specialized datasets, Torchvision provides a unified interface for seamless data integration. This abstraction significantly streamlines the process of loading and preprocessing visual data, a foundational step in any computer vision project.
- Models (Pretrained and Untrained): One of Torchvision’s standout features is its collection of pretrained and untrained models for image and video analysis. For rapid prototyping and transfer learning, developers can leverage a variety of pretrained models, such as ResNet, VGG, and more. Additionally, Torchvision allows the creation of custom models, facilitating the exploration of novel architectures tailored to specific visual tasks.
- Transformations: Data augmentation and preprocessing are critical for enhancing the robustness and generalization of models trained on visual data. Torchvision’s transformations module offers a rich set of tools for applying diverse image and video transformations. From resizing and cropping to advanced augmentations, developers can effortlessly manipulate input data to suit the requirements of their computer vision models.
- Integration with PyTorch Ecosystem: Torchvision seamlessly integrates with the broader PyTorch ecosystem. The interoperability allows for a smooth transition between Torchvision’s visual processing capabilities and the core PyTorch functionalities. This synergy empowers developers to combine the strengths of Torchvision with the flexibility of PyTorch, creating a comprehensive environment for tackling complex computer vision tasks.
Key Features
TorchVision is a comprehensive library that provides tools and utilities for a wide range of computer vision tasks. Some of its key features include:
- Datasets and DataLoaders: TorchVision provides pre-loaded datasets such as MNIST, CIFAR-10, and ImageNet, making it easy to experiment with your models. DataLoaders assist in efficiently loading and processing these datasets for training and evaluation.
- Transforms: Transformations play a crucial role in augmenting and preprocessing image data. TorchVision simplifies this process by offering a variety of built-in transforms for tasks like cropping, rotating, and normalizing images.
- Models: Pre-trained models for popular architectures like ResNet, VGG, and MobileNet are readily available in TorchVision. These models can be easily integrated into your projects, saving valuable time and computational resources.
- Utilities for Image Processing: TorchVision includes functions for common image processing tasks, such as handling images with different formats, plotting, and converting between image and tensor representations.
- Object Detection: TorchVision supports object detection tasks through its implementation of popular algorithms like Faster R-CNN, Mask R-CNN, and SSD (Single Shot MultiBox Detector).
- Semantic Segmentation: For tasks involving pixel-level segmentation, TorchVision provides pre-trained models and tools for semantic segmentation using architectures like DeepLabV3 and FCN (Fully Convolutional Networks).
Big Question: How do computers see images?

In the intricate dance between machines and visual data, the question arises: How do computers perceive images? Unlike human eyes, computers rely on algorithms and mathematical representations to decipher the rich tapestry of visual information presented to them. This process, rooted in the realm of computer vision, is a fascinating exploration of the intersection between technology and perception.
At the core of how computers see images lies the concept of pixels. Images, essentially composed of millions of pixels, are numerical representations of color and intensity. Through this pixel-level analysis, computers gain insights into the visual content, laying the foundation for more advanced interpretations.
Machine learning and deep neural networks play a pivotal role in endowing computers with the ability to “see.” Training on vast datasets, these algorithms learn patterns, shapes, and features, enabling them to recognize objects and scenes. Convolutional Neural Networks (CNNs) have emerged as a powerful tool in this context, mimicking the hierarchical structure of the human visual system.
Ever wondered about the connection between androids and electric sheep? Philip K. Dick’s iconic novel, “Do Androids Dream of Electric Sheep?” delves into the essence of humanity and consciousness. While the book contemplates the emotional spectrum of androids, in reality, computers lack emotions but excel in processing visual stimuli. The comparison draws attention to the intricate dance between artificial intelligence and the nuanced world of human emotions.

Have you ever opened an image in a text editor? It might seem counterintuitive, but this simple act unveils the binary soul of visual data. Images, composed of intricate patterns of 0s and 1s, reveal their inner workings when viewed through the lens of a text editor. Each pixel’s color and intensity are encoded in binary, providing a glimpse into the digital language that computers effortlessly comprehend.
Typical Pipeline with TorchVision
The specific query, “Is there a traffic light in this image?” encapsulates the practical application of object identification. TorchVision excels in precisely answering such questions by leveraging state-of-the-art models like Faster R-CNN, SSD, and YOLO. These models, pre-trained on extensive datasets, are adept at recognizing a myriad of objects, including traffic lights, amidst diverse visual scenarios.
The TorchVision workflow for object identification involves preprocessing the input image, feeding it through the chosen model, and post-processing the results to obtain accurate predictions.

This seamless pipeline ensures that users can confidently pose questions about the content of an image, knowing that TorchVision’s robust architecture is tirelessly at work behind the scenes. Let’s unravel the intricacies of the typical pipeline for object detection, guided by the robust capabilities of TorchVision.
- Input Image: The journey begins with a single image, acting as the canvas for the object detection model. This could be any visual data, ranging from photographs to video frames, forming the raw material for the subsequent stages.
- Image Tensor: To make the image compatible with deep learning models, it undergoes a transformation into an image tensor. This conversion involves representing the image as a multi-dimensional array, enabling seamless integration with neural networks.
- Batch of Input Tensors: Object detection rarely relies on a single image. Instead, a batch of input tensors is fed into the model, allowing for parallel processing and improved efficiency. This batch formation ensures that the model can generalize well across diverse visual scenarios.
- Object Detection Model: At the heart of the pipeline lies the object detection model, a neural network specifically designed to identify and locate objects within images. TorchVision provides a variety of pre-trained models like Faster R-CNN, SSD, and YOLO, each excelling in different aspects of object detection.
- Detected Objects: The model, after intense computation, outputs a set of bounding boxes, each encapsulating a detected object along with its associated class label and confidence score. These bounding boxes serve as the visual annotations, outlining the positions of identified objects.
- Model Output Report: The final step involves generating a comprehensive model output report. This report encapsulates the results of the object detection process, including details on the detected objects, their classes, and the corresponding confidence levels. This information is pivotal for downstream applications such as decision-making systems or further analysis.
Image Tensors
Image tensors serve as fundamental structures for representing digital images in computer vision. These tensors, commonly categorized as rank 3 tensors, possess specific dimensions that encapsulate essential information about the image they represent.

- Rank 3 Tensors: Image tensors, at their core, are rank 3 tensors, implying that they have three dimensions. This trinity of dimensions corresponds to distinct aspects of the image, collectively forming a comprehensive representation.
- Dimensions:
- Dim0 – Number of Channels: The initial dimension, dim0, signifies the number of channels within the image tensor. For RGB images, this value is set to 3, denoting the three primary color channels—red, green, and blue. Each channel encapsulates unique information contributing to the overall color composition of the image.
- Dim1 – Height of the Image: The second dimension, dim1, corresponds to the height of the image. This dimension measures the vertical extent of the image, providing crucial information about its size along the y-axis.
- Dim2 – Width of the Image: Dim2, the third dimension, represents the width of the image. It quantifies the horizontal span of the image along the x-axis, completing the spatial information encoded in the tensor.
- RGB Image Representation: In the context of RGB images, the tensor’s channels correspond to the intensity values of red, green, and blue colors. This enables the tensor to encapsulate both spatial and color information, making it a powerful representation for various computer vision tasks.
- Application in Deep Learning: Image tensors play a pivotal role in deep learning frameworks, serving as input data for neural networks. Their hierarchical structure allows neural networks to analyze and extract features at different levels, enabling the model to learn intricate patterns within images.
- Manipulation and Processing: Understanding the tensor dimensions facilitates image manipulation and processing. Reshaping, cropping, or applying filters involves modifying these dimensions to achieve desired effects while preserving the integrity of the visual information.
- Advancements and Future Directions: As computer vision research progresses, advancements in image tensor representations continue to emerge. Techniques such as tensor decomposition and attention mechanisms contribute to refining image tensor utilization, paving the way for enhanced image analysis and understanding.
Batching
Batching is the practice of grouping multiple images into a single batch for processing by your model. This significantly improves efficiency, especially when working with GPUs. When working with deep learning frameworks like PyTorch, leveraging hardware acceleration with GPUs can significantly speed up the training process.

In torchvision, batching involves the grouping of images to be processed together, a key practice for enhancing computational efficiency. By leveraging torchvision’s capabilities, particularly its DataLoader module, images can be efficiently organized into batches, making them ready for simultaneous processing by both the GPU and CPU.
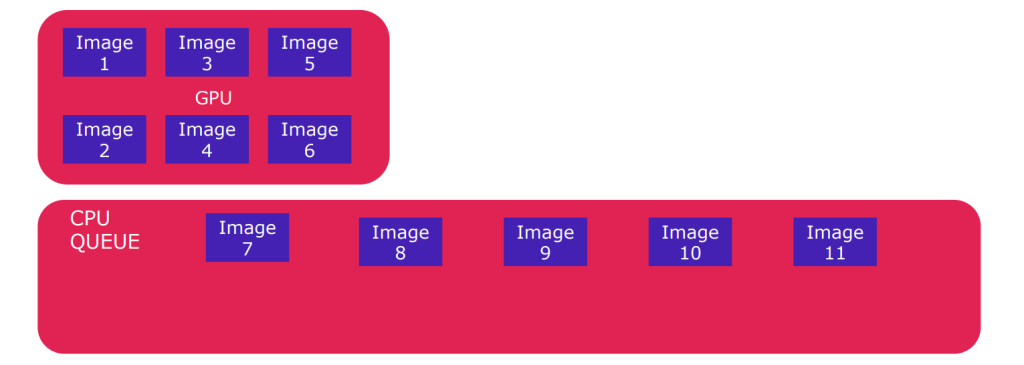
The torchvision library seamlessly integrates with GPUs to leverage their parallel processing capabilities. In the case of 6-image batches, the CPU, through torchvision’s DataLoader, can efficiently prepare the image data, while the GPU, powered by torchvision’s transformation and processing functions, executes parallelized operations on the batched images. This collaborative effort optimizes the efficiency of image processing tasks.

CPU Queues play a critical role in managing the flow of image processing tasks between the CPU and GPU. Batching strategies, facilitated by torchvision’s DataLoader, contribute to effective queue management by defining the composition of image batches. This ensures that both processors remain actively engaged, resulting in seamless parallel processing of images.
Pretrained Models
Pretrained Models in the realm of computer vision play a pivotal role in simplifying and accelerating the development of various applications. Among these models, fasterrcnn_resnet50_fpn stands out for its robust performance and versatile applications.
The nomenclature of fasterrcnn_resnet50_fpn sheds light on its underlying neural architectures. Resnet50, a well-known model, excels in extracting meaningful information from image tensors. Its depth and skip connections enable effective feature extraction, making it a popular choice for various computer vision tasks.
Faster RCNN, integrated with Resnet50, takes the capabilities further by adopting an object-detection architecture. Leveraging Resnet’s extracted features, Faster RCNN excels in precisely identifying and localizing objects within an image. This architecture enhances accuracy and efficiency in object detection, making it suitable for applications such as image classification, localization, and segmentation.
The training of fasterrcnn_resnet50_fpn is noteworthy, as it has been accomplished using the COCO academic dataset. The COCO dataset, known for its comprehensive and diverse collection of images, ensures that the model is exposed to a wide range of scenarios. This broad training data contributes to the model’s ability to generalize well and perform effectively on unseen data.
It is worth noting that Torchvision, a popular computer vision library in PyTorch, hosts a variety of pretrained models catering to different use cases. These models are tailored for tasks ranging from image classification to instance segmentation. The availability of diverse pretrained models in Torchvision provides developers with a rich toolbox, enabling them to choose the most suitable model for their specific application.
Fast R-CNN
Pretrained Models like Fast R-CNN continue to be instrumental in advancing computer vision applications, offering a unique approach to object detection. Let’s delve into the specifics of Fast R-CNN and its key attributes:
Fast R-CNN, short for Fast Region-based Convolutional Neural Network, represents a paradigm shift in object detection methodologies. Unlike its predecessor, R-CNN, which involved time-consuming region proposal generation, Fast R-CNN streamlines this process by introducing a Region of Interest (RoI) pooling layer. This innovation significantly enhances computational efficiency while maintaining high detection accuracy.
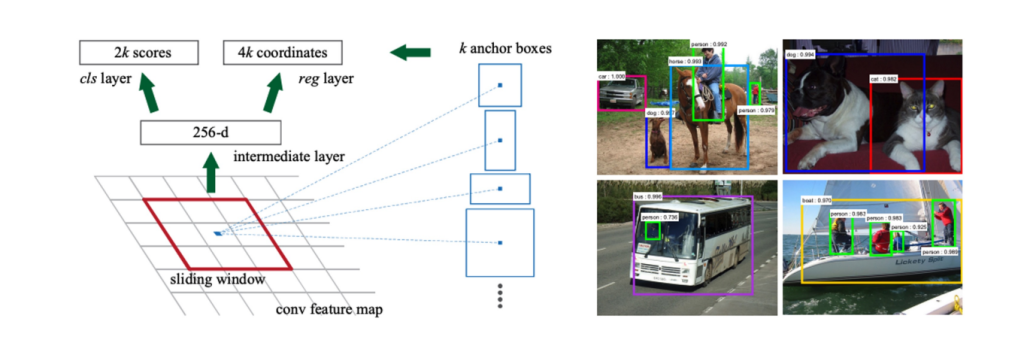
The architecture of Fast R-CNN includes a convolutional neural network (CNN) for feature extraction and an RoI pooling layer for region-based localization. In the case of the lab, Resnet50 serves as the CNN, leveraging its ability to extract rich and informative features from image tensors.
The model’s name, “Fast R-CNN,” reflects its emphasis on speed without compromising accuracy, making it well-suited for real-time applications. By integrating region-based information through RoI pooling, Fast R-CNN excels in precisely identifying and classifying objects within an image.
Similar to other pretrained models, the effectiveness of Fast R-CNN is heightened by training on comprehensive datasets. While the specific datasets may vary, a common choice is the COCO academic dataset, ensuring exposure to diverse scenarios and object classes. This comprehensive training aids the model in generalizing well to unseen data and diverse real-world applications.
Within the broader context of computer vision frameworks, Torchvision provides a repository of pretrained models, including variants optimized for different use cases. Fast R-CNN’s availability in Torchvision enhances its accessibility, making it a valuable resource for developers working on object detection tasks.
COCO Dataset
The COCO dataset, or the Common Objects in Context dataset, stands as a cornerstone in the field of computer vision, providing a rich and diverse collection of images annotated with detailed object information. Here’s a closer look at the key aspects of the COCO dataset and its role in training models:
- Comprehensive Object Coverage: The COCO dataset is renowned for its inclusivity, encompassing a wide array of common objects encountered in various real-world scenarios. This diversity ensures that models trained on COCO are exposed to a broad spectrum of objects, allowing them to learn robust features and patterns.
- Integer-based Object Prediction: Models trained on the COCO dataset typically predict the class of an object as an integer. This integer corresponds to a specific class label within the COCO taxonomy. The use of integer labels simplifies the prediction output, making it computationally efficient and facilitating easier interpretation.
- Lookup Mechanism for Object Identification: After the model predicts an integer representing the class of an object, a lookup mechanism is employed to identify the corresponding object. This lookup involves referencing a mapping or dictionary that associates each integer label with a specific object category. By cross-referencing this mapping, the predicted integer can be translated into a human-readable label, revealing the identity of the detected object.

The COCO dataset’s impact extends beyond its use as a training dataset. It serves as a benchmark for evaluating the performance of computer vision models, particularly in tasks such as object detection, segmentation, and captioning. The dataset’s annotations provide valuable ground truth information, enabling precise model evaluation and comparison.
In practical terms, the COCO dataset has been pivotal in advancing the capabilities of object detection models, such as Faster RCNN and Fast R-CNN. These models leverage the dataset’s diverse images and detailed annotations to learn intricate features, enabling them to excel in real-world scenarios with multiple objects and complex scenes.
Model inference
Model inference is a crucial step in the deployment of machine learning models, representing the process of generating predictions or outputs based on given inputs. In the context of PyTorch, a popular deep learning library, model inference is a straightforward procedure, typically encapsulated in a single line of code.
- Definition of Model Inference: Model inference involves utilizing a trained machine learning model to generate predictions or outputs based on input data. This process is fundamental to applying models in real-world scenarios, where they are tasked with making predictions on new, unseen data.
- PyTorch Implementation: In PyTorch, the process of model inference is as simple as invoking the model with the input data. The syntax is concise, often represented by a single line of code. For example:
prediction = model(input)Here, model is the pretrained neural network, and input is the data for which predictions are to be generated. This simplicity and elegance in syntax contribute to the accessibility and usability of PyTorch for model deployment.
- Batched Inference: In scenarios where the input consists of a batch of N samples, the model inference process extends naturally. The PyTorch model is capable of handling batched inputs, and consequently, the output is a batch of N predictions. This capability is essential for efficient processing and parallelization, particularly in applications with large datasets.
- Prediction Output Format: The output of the model inference is a list of predictions, each corresponding to an object detected in the input image. Each prediction in the list includes information about the detected object and the model’s confidence level regarding the detection. This information typically includes class labels representing the type of object detected and associated confidence scores.For instance, a prediction might look like:
[
{'class': 'cat', 'confidence': 0.92},
{'class': 'dog', 'confidence': 0.85},
# ... additional detected objects and confidences
]This format provides actionable insights into the model’s understanding of the input data, allowing developers and users to make informed decisions based on the detected objects and their associated confidence levels.
Post Processing
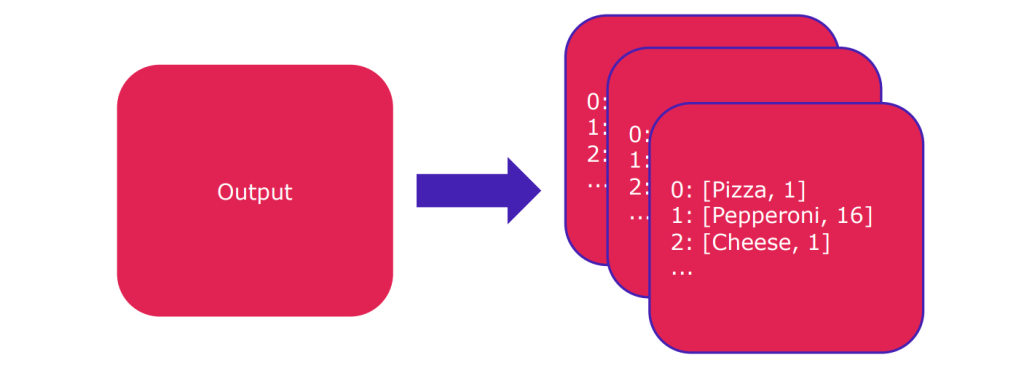
Post-processing is a critical phase in the workflow of a machine learning model, particularly in the context of computer vision tasks such as object detection. It involves refining and interpreting the raw outputs generated by the model during the inference phase. In PyTorch, post-processing is an essential step to transform model predictions into actionable and understandable results.
- Definition of Post Processing: Post processing is the stage where the raw predictions generated by a model during inference are refined and organized to extract meaningful information. This step is necessary to convert the model’s output into a format that is usable and interpretable for the intended application.
- Simple Syntax in PyTorch: In PyTorch, post-processing is often implemented in a straightforward manner. After obtaining the raw predictions from the model, developers typically apply a set of rules or operations to enhance the interpretability of the results. For example:
post_processed_predictions = post_process(prediction)Here, prediction is the output generated by the model during inference, and post_process is a function that refines the raw predictions based on specific criteria or requirements.
- Handling Batched Outputs: Similar to the inference phase, post-processing is designed to handle batched outputs efficiently. If the model has processed a batch of input samples, the post-processing step is applied independently to each prediction in the batch, ensuring consistency and scalability.
- Refining Predictions: The primary goal of post-processing is to refine and organize the raw predictions into a structured format. This may involve tasks such as:
- Filtering out predictions below a certain confidence threshold.
- Non-maximum suppression to eliminate redundant or overlapping detections.
- Converting class indices into human-readable class labels.
- Mapping bounding box coordinates to the original image space.
- Result Interpretation: The final output of the post-processing step is a refined set of predictions that are more interpretable for end-users or downstream applications. The refined predictions often include information such as the class of the detected object, the associated confidence score, and the location of the object in the image. For instance:
[
{'class': 'car', 'confidence': 0.95, 'bbox': [x, y, width, height]},
{'class': 'person', 'confidence': 0.89, 'bbox': [x, y, width, height]},
# ... additional refined predictions
]This format provides a clear and concise representation of the detected objects and their characteristics.
Working with Datasets and DataLoaders
TorchVision simplifies the process of working with datasets and loading them into your models. You can easily download and use datasets like CIFAR-10 as follows:
import torchvision
import torchvision.transforms as transforms
# Define transform
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# Download and load CIFAR-10 dataset
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
Leveraging Pre-trained Models
TorchVision’s pre-trained models can be easily integrated into your projects. Here’s an example of using a pre-trained ResNet model for image classification:
import torchvision.models as models
import torch.nn as nn
# Load pre-trained ResNet18
resnet = models.resnet18(pretrained=True)
# Modify the final fully connected layer for your specific task
num_classes = 10
resnet.fc = nn.Linear(resnet.fc.in_features, num_classes)
Object Detection with TorchVision
Object detection is a common computer vision task, and TorchVision makes it accessible with its implementation of Faster R-CNN. Here’s a simplified example:
import torchvision.transforms as T
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.models.detection.rpn import AnchorGenerator
# Define transformations
transform = T.Compose([T.ToTensor()])
# Create a Faster R-CNN model
model = fasterrcnn_resnet50_fpn(pretrained=True)
# Set the model to evaluation mode
model.eval()
Semantic Segmentation with DeepLabV3
For semantic segmentation tasks, TorchVision offers DeepLabV3, a state-of-the-art model for pixel-level classification:
import torchvision.models as models
from torchvision.models.segmentation import deeplabv3_resnet50
# Load pre-trained DeepLabV3
deeplabv3 = deeplabv3_resnet50(pretrained=True)
# Modify the final classification layer for your specific number of classes
num_classes = 21
deeplabv3.classifier = nn.Conv2d(deeplabv3.classifier.in_channels, num_classes, kernel_size=1)
Conclusion:
PyTorch’s TorchVision library stands out as a powerful tool for computer vision tasks, providing a rich set of functionalities and pre-trained models. Whether you’re working on image classification, object detection, or semantic segmentation, TorchVision simplifies the implementation process, allowing researchers and developers to focus on the core aspects of their projects. With its ease of use and extensive documentation, TorchVision has become an invaluable resource in the deep learning community, contributing to the rapid advancement of computer vision applications.