
Kotlin is a modern programming language that offers powerful features for building robust and type-safe applications. One such feature is generics, which allows developers to write reusable code that can work with different types. In this blog post, we will delve into the concept of Kotlin generics and explore the intricacies of variance, providing clear explanations and practical examples along the way.
In Kotlin, there are some advanced concepts related to generics that we will explore. These concepts include reified type parameters and declaration-site variance. While they may sound unfamiliar, don’t worry! This blog post will cover them in detail.
Generic type parameters
In Kotlin Generics, you can define types that have type parameters, allowing for more flexible and reusable code. When you create an instance of such a type, you substitute the type parameters with specific types, known as type arguments. This allows you to specify the kind of data that will be stored or processed by the type.
For example, let’s consider the List type. In Kotlin, you can declare a variable of type List<String>, which means it holds a list of strings. Similarly, the Map type has type parameters for the key type (K) and the value type (V). You can instantiate a Map with specific arguments, such as Map<String, Person>, which represents a map with string keys and Person values.
In many cases, the Kotlin compiler can infer the type arguments based on the context. For example:
val authors = listOf("Stan Lee", "J.K Rowling")Here, since both values passed to the listOf function are strings, the compiler infers that you’re creating a List<String>. However, when creating an empty list, there is nothing to infer the type argument from, so you need to specify it explicitly. You have two options for specifying the type argument:
// here created empty list, so nothing to infer, so specified type argument(i.e String) explicitly.
val readers: MutableList<String> = mutableListOf()
val readers = mutableListOf<String>() Both of these declarations are equivalent and create an empty mutable list of strings.
It’s important to note that Kotlin always requires type arguments to be either specified explicitly or inferred by the compiler. In contrast, Java allows the use of raw types, where you can declare a variable of a generic type without specifying the type argument. However, Kotlin does not support raw types, and type arguments must always be defined.
So, in Kotlin, you won’t encounter situations where you can use a generic type without providing the type arguments explicitly or inferring them through type inference.
Generic functions and properties
In Kotlin generics, You can write generic functions and properties to work with any type, providing flexibility and reusability. Generic functions have their own type parameters, which are replaced with specific type arguments when invoking the function. Similarly, generic properties allow you to define properties that are parameterized by a type.
Let’s explore examples of generic functions and properties to understand how they work.
Generic Functions
To illustrate, let’s consider the slice function, which returns a list containing elements at specified indices. Its declaration looks like this:
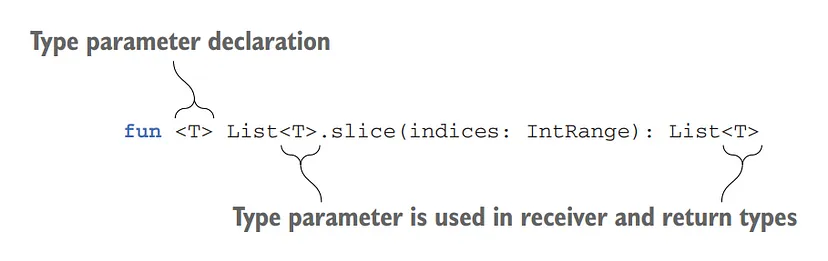
fun <T> List<T>.slice(indices: IntRange): List<T> {
// Implementation goes here
}In this example, <T> is the type parameter, which represents the unknown type that will be specified when calling the function. The List<T> is the receiver type, indicating that this function is an extension function for lists. The return type List<T> ensures that the resulting list has the same type as the input list.
When invoking the slice function, you can either explicitly specify the type argument or rely on type inference:
val letters = ('a'..'z').toList()
println(letters.slice<Char>(0..2)) // Specifies the type argument explicitly, o/p - [a, b, c]
println(letters.slice(10..13)) // The compiler infers that T is Char here, o/p - [k, l, m, n]The compiler can often infer the type argument based on the context, so you don’t need to explicitly provide it. In both cases, the result type will be List<Char>.
Generic type parameter used in parameter Function Type
When a generic type parameter is used in a parameter function type like (T) -> Boolean, it allows the function to accept a lambda or function that operates on elements of the generic type. The compiler infers the type based on the context and ensures type safety throughout the filtering process. Let’s see it in detail.
Consider the filter function, which filters a list based on a provided predicate. Its declaration looks like this:
fun <T> List<T>.filter(predicate: (T) -> Boolean): List<T> {
// Implementation goes here
}In this example, <T> is the type parameter, representing the unknown type that will be specified when calling the function. The List<T> is the receiver type, indicating that this function is an extension function for lists. The predicate parameter has the function type (T) -> Boolean, which means it accepts a function that takes a parameter of type T and returns a Boolean value.
When using the filter function, you can provide a lambda expression as the predicate. The compiler infers the type based on the function’s declaration and the type of the list being filtered. Here’s an example:
val authors = listOf("Stan Lee", "J.K.Rowling")
val readers = mutableListOf<String>(/* ... */)
val filteredReaders = readers.filter { it !in authors }In this case, the lambda expression { it !in authors } is used as the predicate. The compiler determines that the lambda parameter it has the type T, which is inferred to be String because the filter function is called on List<String> (readers).
By utilizing the generic type parameter
Tin the function declaration, thefilterfunction can work with any type of list and apply the provided predicate accordingly.
Generic Extension Properties
Similar to generic functions, you can declare generic extension properties using the same syntax. For example, let’s define an extension property penultimate that returns the element before the last one in a list:
val <T> List<T>.penultimate: T // This generic extension property can be called on a list of any kind
get() = this[size - 2]In this case, <T> is the type parameter, and it is part of the receiver type List<T>. The get() function provides the implementation for retrieving the penultimate element.
You can then use the penultimate property on a list:
println(listOf(1, 2, 3, 4).penultimate) //The type parameter T is inferred to be Int in this invocation
// Output: 3Note that generic non-extension properties are not allowed in Kotlin. Regular (non-extension) properties cannot have type parameters because they are associated with a specific class or obect and cannot store multiple values of different types.
If you attempt to declare a generic non-extension property, the compiler will report an error similar to the following:
val <T> x: T = TODO()
// ERROR: type parameter of a property must be used in its receiver typeThe error message indicates that the type parameter T used in the property declaration should be associated with its receiver type, but since regular properties are specific to a class or object, it doesn’t make sense to have a generic property that can accommodate multiple types.
Declaring generic classes
Just like in Java, in Kotlin also, you can declare generic classes and interfaces by using angle brackets after the class name and specifying the type parameters within the angle brackets. These type parameters can then be used within the body of the class, just like any other types.
For example, let’s consider the declaration of the standard Java interface List in Kotlin:
interface List<T> {
operator fun get(index: Int): T
// ...
}In this example, List is declared as a generic interface with a type parameter T. You can use this type parameter in the interface’s methods and other declarations.
When a class extends a generic class or implements a generic interface, you need to provide a type argument for the generic parameter of the base type. This type argument can be a specific type or another type parameter.
Here are a couple of examples:
class StringList : List<String> {
override fun get(index: Int): String = ...
}
class ArrayList<T> : List<T> {
override fun get(index: Int): T = ...
}In the first example, the StringList class extends List<String>, which means it specifically contains String elements. The get function in StringList will have the signature fun get(index: Int): String instead of fun get(index: Int): T.
In the second example, the ArrayList class defines its own type parameter T and specifies it as the type argument for the superclass List<T>.
Note that T in ArrayList is not the same as in List — it’s a new type parameter, and it doesn’t need to have the same name.
Additionally, a class can even refer to itself as a type argument. Classes implementing the Comparable interface are the classical example of this pattern. Any comparable element must define how to compare it with objects of the same type:
interface Comparable<T> {
fun compareTo(other: T): Int
}
class String : Comparable<String> {
override fun compareTo(other: String): Int = /* ... */
}In this example, the String class implements the generic Comparable interface by specifying String as the type argument for the type parameter T.
Type parameter constraints
Type parameter constraints in Kotlin allow you to limit the types that can be used as arguments for a class or function. This ensures that only specific types or their subtypes can be used.
When you specify a type as an upper bound constraint for a type parameter of a generic type, the corresponding type arguments in specific instantiations of the generic type must be either the specified type or its subtypes(For now, you can think of subtype as a synonym for subclass).
To specify a constraint, you put a colon after the type parameter name, followed by the type that’s the upper bound for the type parameter. In Java, you use the keyword extends to express the same concept: T sum(List list)
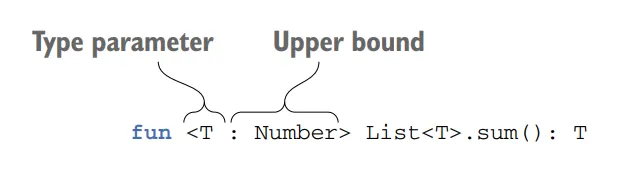
Let’s start with an example. Suppose we have a function called sum that calculates the sum of elements in a list. We want this function to work with List<Int> or List<Double>, but not with List<String>. To achieve this, we can define a type parameter constraint that specifies the type parameter of sum must be a number.
fun <T : Number> sum(list: List<T>): T {
var result = 0.0
for (element in list) {
result += element.toDouble()
}
return result as T
}In this example, we specify <T : Number> as the type parameter constraint, indicating that T must be a subclass of Number. Now, when we invoke the function with a list of integers, it works correctly:
println(sum(listOf(1, 2, 3))) // Output: 6The type argument Int extends Number, so it satisfies the type parameter constraint.
You can also use methods defined in the class used as the bound for the type parameter constraint. Here’s an example:
fun <T : Number> oneHalf(value: T): Double {
return value.toDouble() / 2.0
}
println(oneHalf(3)) // Output: 1.5In this case, T is constrained to be a subclass of Number, so we can use methods defined in the Number class, such as toDouble().
Now let’s consider another example where we want to find the maximum of two items. Since it’s only possible to compare items that are comparable to each other, we need to specify that requirement in the function signature using the Comparable interface:
fun <T : Comparable<T>> max(first: T, second: T): T {
return if (first > second) first else second
}
println(max("kotlin", "java")) // Output: kotlinIn this case, we specify <T : Comparable<T>> as the type parameter constraint. It ensures that T can only be a type that implements the Comparable interface. Hence, we can compare first and second using the > operator.
If you try to call max with incomparable items, such as a string and an integer, it won’t compile:
println(max("kotlin", 42)) // ERROR: Type parameter bound for T is not satisfiedThe error occurs because the type argument Any inferred for T is not a subtype of Comparable<Any>, which violates the type parameter constraint.
In some cases, you may need to specify multiple constraints on a type parameter. You can use a slightly different syntax for that. Here’s an example where we ensure that the given CharSequence has a period at the end and can be appended:
fun <T> ensureTrailingPeriod(seq: T)
where T : CharSequence, T : Appendable {
if (!seq.endsWith('.')) {
seq.append('.')
}
}
val helloWorld = StringBuilder("Hello World")
ensureTrailingPeriod(helloWorld)
println(helloWorld) // Output: Hello World.In this case, we specify the constraints T : CharSequence and T : Appendable using the where clause. This ensures that the type argument must implement both the CharSequence and Appendable interfaces, allowing us to use operations like endsWith and append on values of that type
Type parameter constraints are also commonly used when you want to declare a non-null type parameter. This helps enforce that the type argument cannot be nullable, ensuring that you always have a non-null value. Let’s see it in more detail.
Making type parameters non-null
In Kotlin, when you declare a generic class or function, you can substitute any type argument, including nullable types, for its type parameters. By default, a type parameter without an upper bound specified will have the upper bound of Any? which means it can accept both nullable and non-nullable types.
Let’s take an example to understand this. Consider the Processor class defined as follows:
class Processor<T> {
fun process(value: T) {
value?.hashCode() // value” is nullable, so you have to use a safe call
}
}In the process function of this class, the parameter value is nullable, even though T itself is not marked with a question mark. This is because specific instantiations of the Processor class can use nullable types for T. For example, you can create an instance of Processor<String?> which allows nullable strings as its type argument:
val nullableStringProcessor = Processor<String?>() // String?, which is a nullable type, is substituted for T
nullableStringProcessor.process(null) // This code compiles fine, having “null” as the “value” argumentIf you want to ensure that only non-null types can be substituted for the type parameter, you can specify a constraint or an upper bound. If the only restriction you have is nullability, you can use Any as the upper bound instead of the default Any?. Here’s an example:
class Processor<T : Any> { // Specifying a non-“null” upper bound
fun process(value: T) {
value.hashCode() // “value” of type T is now non-“null”
}
}In this case, the <T : Any> constraint ensures that the type T will always be a non-nullable type. If you try to use a nullable type as the type argument, like Processor<String?>(), the compiler will produce an error. The reason is that String? is not a subtype of Any (it’s a subtype of Any?, which is a less specific type):
val nullableStringProcesor = Processor<String?>()
// Error: Type argument is not within its bounds: should be subtype of 'Any'It’s worth noting that you can make a type parameter non-null by specifying any non-null type as an upper bound, not only
Any. This allows you to enforce stricter constraints based on your specific needs.
Underscore operator ( _ ) for type arguments
The underscore operator _ in Kotlin is a type inference placeholder that allows the Kotlin compiler to automatically infer the type of an argument based on the context and other explicitly specified types.
abstract class SomeClass<T> {
abstract fun execute() : T
}
class SomeImplementation : SomeClass<String>() {
override fun execute(): String = "Test"
}
class OtherImplementation : SomeClass<Int>() {
override fun execute(): Int = 42
}
object Runner {
inline fun <reified S: SomeClass<T>, T> run() : T {
return S::class.java.getDeclaredConstructor().newInstance().execute()
}
}
fun main() {
// T is inferred as String because SomeImplementation derives from SomeClass<String>
val s = Runner.run<SomeImplementation, _>()
assert(s == "Test")
// T is inferred as Int because OtherImplementation derives from SomeClass<Int>
val n = Runner.run<OtherImplementation, _>()
assert(n == 42)
}Don’t worry! Let’s break down the code step by step:
- In this code, we have an abstract class called
SomeClasswith a generic typeT. It declares an abstract functionexecute()that returns an object of typeT. - We have a class called
SomeImplementationwhich extendsSomeClassand specifies the generic type asString. It overrides theexecute()function and returns the string value"Test". - Similarly, we have another class called
OtherImplementationwhich extendsSomeClassand specifies the generic type asInt. It overrides theexecute()function and returns the integer value42. - Below that, we have an object called
Runnerwith a functionrun(). This function is generic and has two type parametersSandT. It uses thereifiedkeyword to access the type information at runtime. Inside the function, it creates an instance of the specified classSusing reflection (getDeclaredConstructor().newInstance()) and calls theexecute()function on it, returning the result of typeT.
In the above code, the underscore operator is used in the main() function when calling the Runner.run() function. Let’s take a closer look:
val s = Runner.run<SomeImplementation, _>()In this line, the type parameter T is explicitly specified as _ for the Runner.run() function. Here, _ acts as a placeholder for the type to be inferred by the compiler. Since SomeImplementation derives from SomeClass<String>, the compiler infers T as String for this invocation. Therefore, the variable s is inferred to be of type String, and the Runner.run() function returns the result of executing SomeImplementation, which is the string "Test".
val n = Runner.run<OtherImplementation, _>()Similarly, in this line, the type parameter T is specified as _ for the Runner.run() function. Since OtherImplementation derives from SomeClass<Int>, the compiler infers T as Int for this invocation. Consequently, the variable n is inferred to be of type Int, and the Runner.run() function returns the result of executing OtherImplementation, which is the integer 42.
By using the underscore operator
_as a type argument, the compiler can automatically infer the appropriate type based on the context and the explicitly specified types.
BTW, how do generics work at runtime?
In Kotlin, generics are a compile-time feature rather than a runtime feature. This means that type information is erased at runtime and not available for inspection or manipulation by the program.
When you use generics in Kotlin, the compiler performs type checking and ensures type safety at compile time. It enforces that the correct types are used in generic functions or classes based on the type parameters specified.
At runtime, Kotlin uses type erasure to remove the generic type information. This is done for compatibility with Java, as both languages share a common runtime environment known as the Java Virtual Machine (JVM). The JVM does not natively support reified generics, which would allow for preserving type information at runtime.
Due to type erasure, you cannot directly access the type parameters of a generic class or function at runtime. For example, if you define a List<String> and a List<Int>, they both become List<Any> at runtime.
However, there are cases where Kotlin provides a workaround for working with generics at runtime using reified types. The reified keyword can be used in inline functions to retain type information within the body of the function. This allows you to perform type checks or access the class instance of the type parameter within the function.
Here’s an example of an inline function that utilizes reified types to perform type checks at runtime:
inline fun <reified T> getType(obj: T) {
if (obj is T) {
println("Object is of type ${T::class.simpleName}")
} else {
println("Object is not of type ${T::class.simpleName}")
}
}In this example, the reified T declaration allows you to access the class instance of the type parameter T using T::class. This wouldn’t be possible without the reified keyword.
Please note that although reified types enable limited runtime access to type information, they only work within the scope of inline functions. Outside of inline functions, the type information is still erased at runtime.
Variance: generics and subtyping
The concept of variance describes how types with the same base type and different type arguments relate to each other: for example, List<String> and List<Any>. It’s important to understand variance when working with generic classes or functions because it helps ensure the safety and consistency of your code.
Why variance exists: passing an argument to a function
To illustrate why variance is important, let’s consider passing arguments to functions. Suppose we have a function that takes a List<Any> as an argument. Is it safe to pass a variable of type List<String> to this function?
In the case of a function that prints the contents of the list, such as:
fun printContents(list: List<Any>) {
println(list.joinToString())
}You can safely pass a list of strings (List<String>) to this function. Each element in the list is treated as an Any, and since String is a subtype of Any, it is considered safe.
However, let’s consider another function that modifies the list:
fun addAnswer(list: MutableList<Any>) {
list.add(42)
}If you attempt to pass a list of strings (MutableList<String>) to this function, like so:
val strings = mutableListOf("abc", "bac")
addAnswer(strings)
println(strings.maxBy { it.length })You will encounter a ClassCastException at runtime. This occurs because the function addAnswer tries to add an integer (42) to a list of strings. If the compiler allowed this, it would lead to a type inconsistency when accessing the contents of the list as strings. To prevent such issues, the Kotlin compiler correctly forbids passing a MutableList<String> as an argument when a MutableList<Any> is expected.
So, the answer to whether it’s safe to pass a list of strings to a function expecting a list of Any objects depends on whether the function modifies the list. If the function only reads the list, it is safe to pass a List with a more specific element type. However, if the list is mutable and the function adds or replaces elements, it is not safe.
Kotlin provides different interfaces, such as List and MutableList, to control safety based on mutability. If a function accepts a read-only list, you can pass a List with a more specific element type. However, if the list is mutable, you cannot do that.
In the upcoming sections, we’ll explore these concepts in the context of generic classes. We’ll also examine why List and MutableList differ regarding their type arguments. But before that, let’s discuss the concepts of type and subtype.
Difference between Classes, types, and subtypes
In Kotlin, the type of a variable specifies the possible values it can hold. The terms “type” and “class” are sometimes used interchangeably, but they have distinct meanings. In the case of a non-generic class, the class name can be used directly as a type. For example, var x: String declares a variable that can hold instances of the String class. However, the same class name can also be used to declare a nullable type, such as var x: String? which indicates that the variable can hold either a String or null. So each Kotlin class can be used to construct at least two types.
When it comes to generic classes, things get more complex. To form a valid type, you need to substitute a specific type as a type argument for the class’s type parameter. For example, List is a class, not a type itself, but the following substitutions are valid types: List<Int>, List<String?>, List<List<String>>, and so on. Each generic class can generate an infinite number of potential types.
To discuss the relationship between types, it’s important to understand the concept of subtyping. Type B is considered a subtype of type A if you can use a value of type B wherever a value of type A is expected. For example, Int is a subtype of Number, but Int is not a subtype of String. Note that a type is considered a subtype of itself. The term “supertype” is the opposite of subtype: if A is a subtype of B, then B is a supertype of A.
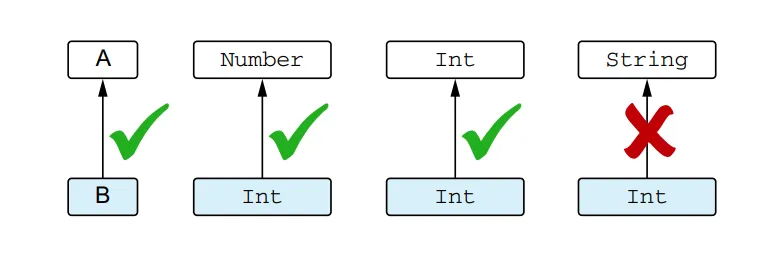
Understanding subtype relationships is crucial because the compiler performs checks whenever you assign a value to a variable or pass an argument to a function. For example:
fun test(i: Int) {
val n: Number = i
fun f(s: String) { /*...*/ }
f(i)
}Storing a value in a variable is only allowed if the value’s type is a subtype of the variable’s type. In this case, since Int is a subtype of Number, the declaration val n: Number = i is valid. Similarly, passing an expression to a function is only allowed if the expression’s type is a subtype of the function’s parameter type. In the example, the type Int of the argument i is not a subtype of the function parameter type String, so the invocation of the f function does not compile.
In simpler cases, subtype is essentially the same as subclass. For example, Int is a subclass of Number, so the Int type is a subtype of the Number type. If a class implements an interface, its type is a subtype of the interface type. For instance, String is a subtype of CharSequence.
Nullable types introduce a scenario where subtype and subclass differ. A non-null type is a subtype of its corresponding nullable type, but they both correspond to the same class.
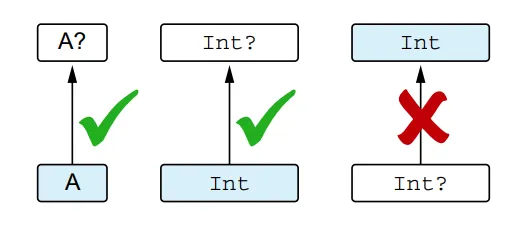
You can store the value of a non-null type in a variable of a nullable type, but not vice versa. For example:
val s: String = "abc"
val t: String? = sIn this case, the value of the non-null type String can be stored in a variable of the nullable type String?. However, you cannot assign a nullable type to a non-null type because null is not an acceptable value for a non-null type.
The distinction between subclasses and subtypes becomes particularly important when dealing with generic types. This brings us back to the question from the previous section: is it safe to pass a variable of type List<String> to a function expecting List<Any>? We’ve already seen that treating MutableList<String> as a subtype of MutableList<Any> is not safe. Similarly, MutableList<Any> is not a subtype of MutableList<String> either.
A generic class, such as MutableList, is called invariant on the type parameter if, for any two different types A and B, MutableList<A> is neither a subtype nor a supertype of MutableList<B>. In Java, all classes are invariant, although specific uses of those classes can be marked as non-invariant (as you’ll see soon).
In the previous section, we encountered a class, List, where the subtyping rules are different. The List interface in Kotlin represents a read-only collection. If type A is a subtype of type B, then List<A> is a subtype of List<B>. Such classes or interfaces are called covariant. In the upcoming sections, we’ll explore the concept of covariance in more detail and explain when it’s possible to declare a class or interface as covariant.
Covariance: preserved subtyping relation
Covariance refers to preserving the subtyping relation between generic classes. In Kotlin, you can declare a class to be covariant on a specific type parameter by using the out keyword before the type parameter’s name.
A covariant class is a generic class (we’ll use Producer as an example) for which the following holds: Producer<A> is a subtype of Producer<B> if A is a subtype of B. We say that the subtyping is preserved. For example, Producer<Cat> is a subtype of Producer<Animal> because Cat is a subtype of Animal.
Here’s an example of the Producer interface using the out keyword:
interface Producer<out T> {
fun produce(): T
}Flexible Function Argument and Return Value Passing
Covariance in Kotlin allows you to pass values of a class as function arguments and return values, even when the type arguments don’t exactly match the function definition. This means that you can use a more specific type as a substitute for a more generic type.
Suppose we have a hierarchy of classes involving Animal, where Cat is a subclass of Animal. We also have a generic interface called Producer, which represents a producer of objects of type T. We’ll make the Producer interface covariant by using the out keyword on the type parameter.
interface Producer<out T> {
fun produce(): T
}Now, let’s define a class AnimalProducer that implements the Producer interface for the Animal type:
class AnimalProducer : Producer<Animal> {
override fun produce(): Animal {
return Animal()
}
}Since Animal is a subtype of Animal, we can use AnimalProducer wherever a Producer<Animal> is expected.
Now, let’s define another class CatProducer that implements the Producer interface for the Cat type:
class CatProducer : Producer<Cat> {
override fun produce(): Cat {
return Cat()
}
}Since Cat is a subtype of Animal, we can also use CatProducer wherever a Producer<Animal> is expected. This is possible because we declared the Producer interface as covariant.
Now, let’s see how covariance allows us to pass these producers as function arguments and return values:
fun feedAnimal(producer: Producer<Animal>) {
val animal = producer.produce()
animal.feed()
fun main() {
val animalProducer = AnimalProducer()
val catProducer = CatProducer()
feedAnimal(animalProducer) // Passes an AnimalProducer, which is a Producer<Animal>
feedAnimal(catProducer) // Passes a CatProducer, which is also a Producer<Animal>
}In the feedAnimal function, we expect a Producer<Animal> as an argument. With covariance, we can pass both AnimalProducer and CatProducer instances because Producer<Cat> is a subtype of Producer<Animal> due to the covariance declaration.
This demonstrates how covariance allows you to treat more specific types (Producer<Cat>) as if they were more generic types (Producer<Animal>) when it comes to function arguments and return values.
BTW, How covariance guarantees type safety?
Suppose we have a class hierarchy involving Animal, where Cat is a subclass of Animal. We also have a Herd class that represents a group of animals.
open class Animal {
fun feed() { /* feeding logic */ }
}
class Herd<T : Animal> { // The type parameter isn’t declared as covariant
val size: Int get() = /* calculate the size of the herd */
operator fun get(i: Int): T { /* get the animal at index i */ }
}
fun feedAll(animals: Herd<Animal>) {
for (i in 0 until animals.size) {
animals[i].feed()
}
}Now, suppose you have a function called takeCareOfCats, which takes a Herd<Cat> as a parameter and performs some operations specific to cats.
class Cat : Animal() {
fun cleanLitter() { /* clean litter logic */ }
}
fun takeCareOfCats(cats: Herd<Cat>) {
for (i in 0 until cats.size) {
cats[i].cleanLitter()
// feedAll(cats) // This line would cause a type-mismatch error, Error: inferred type is Herd<Cat>, but Herd<Animal> was expected
}
}In this case, if you try to pass the cats herd to the feedAll function, you’ll get a type-mismatch error during compilation. This happens because you didn’t use any variance modifier on the type parameter T in the Herd class, making the Herd<Cat> incompatible with Herd<Animal>. Although you could use an explicit cast to overcome this issue, it is not a recommended approach.
To make it work correctly, you can make the Herd class covariant by using the out keyword on the type parameter:
class Herd<out T : Animal> { // The T parameter is now covariant.
// ...
}
fun takeCareOfCats(cats: Herd<Cat>) {
for (i in 0 until cats.size) {
cats[i].cleanLitter()
}
feedAll(cats) // Now this line works because of covariance, You don’t need a cast.
By marking the type parameter as covariant, you ensure that the subtyping relation is preserved, and T can only be used in \”out\” positions. This guarantees type safety and allows you to pass a Herd<Cat> where a Herd<Animal> is expected.
Usage of covariance
Covariance in Kotlin allows you to make a class covariant on a type parameter, but it also imposes certain constraints to ensure type safety. The type parameter can only be used in “out” positions, which means it can produce values of that type but not consume them.
You can’t make any class covariant: it would be unsafe. Making the class covariant on a certain type parameter constrains the possible uses of this type parameter in the class. To guarantee type safety, it can be used only in so-called out positions, meaning the class can produce values of type T but not consume them. Uses of a type parameter in declarations of class members can be divided into “in” and “out” positions.
Let’s consider a class that declares a type parameter T and contains a function that uses T. We say that if T is used as the return type of a function, it’s in the out position. In this case, the function produces values of type T. If T is used as the type of a function parameter, it’s in the in position. Such a function consumes values of type T.
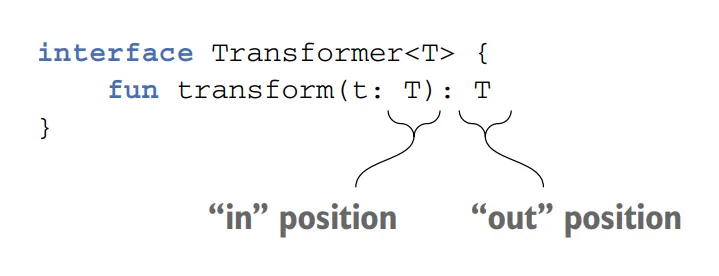
The out keyword on a type parameter of the class requires that all methods using T have T only in “out” positions and not in “in” positions. This keyword constrains possible use of T, which guarantees safety of the corresponding subtype relation.
Let’s understand this with some examples. Consider the Herd class, which is declared as Herd<out T : Animal>. The type parameter T is used only in the return value of the get method. This is an “out” position, and it is safe to declare the class as covariant. For instance, Herd<Cat> is considered a subtype of Herd<Animal> because Cat is a subtype of Animal.
class Herd<out T : Animal> {
val size: Int = ...
operator fun get(i: Int): T { ... } // Uses T as the return type
}Similarly, the List<T> interface in Kotlin is covariant because it only defines a get method that returns an element of type T. Since there are no methods that store values of type T, it is safe to declare the class as covariant.
interface List<out T> : Collection<T> {
operator fun get(index: Int): T // Read-only interface that defines only methods that return T (so T is in the “out” position)
// ...
}You can also use the type parameter T as a type argument in another type. For example, the subList method in the List interface returns a List<T>, and T is used in the “out” position.
interface List<out T> : Collection<T> {
fun subList(fromIndex: Int, toIndex: Int): List<T> // Here T is in the “out” position as well.
// ...
}However, you cannot declare MutableList<T> as covariant on its type parameter because it contains methods that both consume and produce values of type T. Therefore, T appears in both “in” and “out” positions, and making it covariant would be unsafe.
interface MutableList<T> : List<T>, MutableCollection<T> { //MutableList can’t be declared as covariant on T …
override fun add(element: T): Boolean // … because T is used in the “in” position.
}The compiler enforces this restriction. It would report an error if the class was declared as covariant: Type parameter T is declared as ‘out’ but occurs in ‘in’ position.
Constructor Parameters and Variance
In Kotlin, constructor parameters are not considered to be in the “in” or “out” position when it comes to variance. This means that even if a type parameter is declared as “out,” you can still use it in a constructor parameter declaration without any restrictions.
For example:
class Herd<out T: Animal>(vararg animals: T) { ... }The type parameter T is declared as “out” but it can still be used in the constructor parameter vararg animals: T without any issues. The variance protection is not applicable to the constructor because it is not a method that can be called later, so there are no potentially dangerous method calls that need to be restricted.
However, if you use the val or var keyword with a constructor parameter, it declares a property with a getter and setter (if the property is mutable). In this case, the type parameter T is used in the “out” position for a read-only property and in both “out” and “in” positions for a mutable property.
For example:
class Herd<T: Animal>(var leadAnimal: T, vararg animals: T) { ... }Here, the type parameter T cannot be marked as “out” because the class contains a setter for the leadAnimal property, which uses T in the “in” position. The presence of a setter makes it necessary to consider both “out” and “in” positions for the type parameter.
It’s important to note that the position rules for variance in Kotlin only apply to the externally visible API of a class, such as public, protected, and internal members. Parameters of private methods are not subject to the “in” or “out” position rules. The variance rules are in place to protect a class from misuse by external clients and do not affect the implementation of the class itself.
For instance:
class Herd<out T: Animal>(private var leadAnimal: T, vararg animals: T) { ... }In this case, the Herd class can safely be made covariant on T because the leadAnimal property has been made private. The private visibility means that the property is not accessible from external clients, so the variance rules for the public API do not apply.
Contravariance: reversed subtyping relation
Contravariance is the opposite of covariance and it can be understood as a mirror image of covariance. When a class is contravariant, the subtyping relationship between its type arguments is the reverse of the subtyping relationship between the classes themselves.
To illustrate this concept, let’s consider the example of the Comparator interface. This interface has a single method called compare, which takes two objects and compares them:
interface Comparator<in T> {
fun compare(e1: T, e2: T): Int { ... }
}In this case, you’ll notice that the compare method only consumes values of type T. This means that the type parameter T is used in “in” positions only, indicating that it is a contravariant type. To indicate contravariance, the “in” keyword is placed before the declaration of T.
A comparator defined for values of a certain type can, of course, compare the values of any subtype of that type. For example, if you have a Comparator, you can use it to compare values of any specific type.
val anyComparator = Comparator<Any> { e1, e2 -> e1.hashCode() - e2.hashCode() }
val strings: List<String> = listOf("abc","xyz")
strings.sortedWith(anyComparator) // You can use the comparator for any objects to compare specific objects, such as strings.Here, the sortedWith function expects a Comparator (a comparator that can compare strings), and it’s safe to pass one that can compare more general types. If you need to perform comparisons on objects of a certain type, you can use a comparator that handles either that type or any of its supertypes. This means Comparator<Any> is a subtype of Comparator<String>, where Any is a supertype of String. The subtyping relation between comparators for two different types goes in the opposite direction of the subtyping relation between those types.
What is contravariance?
A class that is contravariant on the type parameter is a generic class (let’s consider Consumer<T> as an example) for which the following holds: Consumer<A> is a subtype of Consumer<B> if B is a subtype of A. The type arguments A and B changed places, so we say the subtyping is reversed. For example, Consumer<Animal> is a subtype of Consumer<Cat>.
In simple words, contravariance in Kotlin means that the subtyping relationship between two generic types is reversed compared to the normal inheritance hierarchy. If B is a subtype of A, then a generic class or interface that is contravariant on its type parameter T will have the relationship ClassName<A> is a subtype of ClassName<B>.
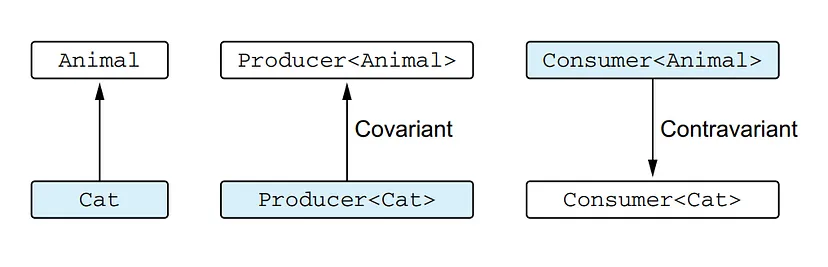
Here, we see the difference between the subtyping relation for classes that are covariant and contravariant on a type parameter. You can see that for the Producer class, the subtyping relation replicates the subtyping relation for its type arguments, whereas for the Consumer class, the relation is reversed.
The “in” keyword means values of the corresponding type are passed in to methods of this class and consumed by those methods. Similar to the covariant case, constraining use of the type parameter leads to the specific subtyping relation. The “in” keyword on the type parameter T means the subtyping is reversed and T can be used only in “in” positions.
Covariance and Contravariance in Kotlin’s Function Types
In Kotlin, a class or interface can be covariant on one type parameter and contravariant on another. One of the classic examples of this is the Function interface. Let’s take a look at the declaration of the Function1 interface, which represents a one-parameter function:
interface Function1<in P, out R> {
operator fun invoke(p: P): R
}To make the notation more readable, Kotlin provides an alternative syntax (P) -> R to represent Function1<P, R>. In this syntax, you’ll notice that P (the parameter type) is used only in the in position and is marked with the in keyword, while R (the return type) is used only in the out position and is marked with the out keyword.
This means that the subtyping relationship for the function type is reversed for the first type argument (P) and preserved for the second type argument (R).
For example, let’s say you have a higher-order function called enumerateCats that accepts a lambda function taking a Cat parameter and returning a Number:
fun enumerateCats(f: (Cat) -> Number) { ... }Now, suppose you have a function called getIndex defined in the Animal class that returns an Int. You can pass Animal::getIndex as an argument to enumerateCats:
fun Animal.getIndex(): Int = ...
enumerateCats(Animal::getIndex) // This code is legal in Kotlin. Animal is a supertype of Cat, and Int is a subtype of NumberIn this case, the Animal::getIndex function is accepted because Animal is a supertype of Cat, and Int is a subtype of Number, the function type’s subtyping relationship allows it.
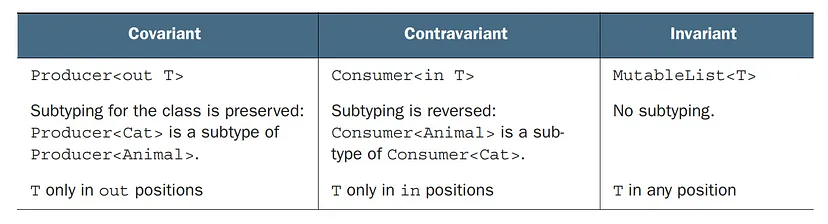
This illustration demonstrates how subtyping works for function types. The arrows indicate the subtyping relationship.
Use-site variance: specifying variance for type occurrences
To understand use-site variance better, you first need to understand declaration-site variance. In Kotlin, the ability to specify variance modifiers on class declarations provides convenience and consistency because these modifiers apply to all places where the class is used. This concept is known as a declaration-site variance.
Declaration-site variance in Kotlin is achieved by using variance modifiers on type parameters when defining a class. As you already knows there are two main variance modifiers:
out(covariant): Denoted by theoutkeyword, it allows the type parameter to be used as a return type or read-only property. It specifies that the type parameter can only occur in the “out” position, meaning it can only be returned from functions or accessed in a read-only manner.in(contravariant): Denoted by theinkeyword, it allows the type parameter to be used as a parameter type. It specifies that the type parameter can only occur in the “in” position, meaning it can only be passed as a parameter to functions.
By specifying these variance modifiers on type parameters, you define the variance behavior of the class, and it remains consistent across all usages of the class.
On the other hand, Java handles variance differently through use-site variance. In Java, each usage of a type with a type parameter can specify whether the type parameter can be replaced with its subtypes or supertypes using wildcard types (? extends and ? super). This means that at each usage point of the type, you can decide the variance behavior.
It’s important to note that while Kotlin supports declaration-site variance with the out and in modifiers, it also provides a certain level of use-site variance through the out and in projection syntax (out T and in T). These projections allow you to control the variance behavior in specific usage points within the code.
Declaration-site variance in Kotlin Vs. Java wildcards
In Kotlin, declaration-site variance allows for more concise code because variance modifiers are specified once on the declaration of a class or interface. This means that clients of the class or interface don’t have to think about the variance modifiers. The convenience of declaration-site variance is that the variance behavior is determined at the point of declaration and remains consistent throughout the codebase.
On the other hand, in Java, wildcards are used to handle variance at the use site. To create APIs that behave according to users’ expectations, the library writer has to use wildcards extensively. For example, in the Java 8 standard library, wildcards are used on every use of the Function interface. This can lead to code like Function<? super T, ? extends R> in method signatures.
To illustrate the declaration of the map method in the Stream interface in Java :
/* Java */
public interface Stream<T> {
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
}In the Java code, wildcards are used in the declaration of the map method to handle the variance of the function argument. This can make the code less readable and more cumbersome, especially when dealing with complex type hierarchies.
In contrast, the Kotlin code uses declaration-site variance, specifying the variance once on the declaration makes the code much more concise and elegant.
BTW, How does use-site variance work in Kotlin?
Kotlin supports use-site variance, you can specify variance at the use site, which means you can indicate the variance for a specific occurrence of a type parameter, even if it can’t be declared as covariant or contravariant in the class declaration. Let’s break down the concepts and see how use-site works.
In Kotlin, many interfaces, like MutableList, are not covariant or contravariant by default because they can both produce and consume values of the types specified by their type parameters. However, in certain situations, a variable of that type may be used only as a producer or only as a consumer.
Consider the function copyData that copies elements from one collection to another:
fun <T> copyData(source: MutableList<T>, destination: MutableList<T>) {
for (item in source) {
destination.add(item)
}
}In this function, both the source and destination collections have an invariant type. However, the source collection is only used for reading, and the destination collection is only used for writing. In this case, the element types of the collections don’t need to match exactly.
To make this function work with lists of different types, you can introduce a second generic parameter:
fun <T : R, R> copyData(source: MutableList<T>, destination: MutableList<R>) {
for (item in source) {
destination.add(item)
}
}In this modified version, you declare two generic parameters representing the element types in the source and destination lists. The source element type (T) should be a subtype of the elements in the destination list (R).
However, Kotlin provides a more elegant way to express this using use-site variance. If the implementation of a function only calls methods that have the type parameter in the “out” position (as a producer) or only in the “in” position (as a consumer), you can add variance modifiers to the particular usages of the type parameter in the function definition.
For example, you can modify the copyData function as follows:
fun <T> copyData(source: MutableList<out T>, destination: MutableList<T>) {
for (item in source) {
destination.add(item)
}
}In this version, you specify the out modifier for the source parameter, which means it’s a projected (restricted) MutableList. You can only call methods that return the generic type parameter (T) or use it in the “out” position. The compiler prohibits calling methods where the type parameter is used as an argument (“in” position).
Here’s an example usage:
val ints = mutableListOf(1, 2, 3)
val anyItems = mutableListOf<Any>()
copyData(ints, anyItems)
println(anyItems) // [1, 2, 3]When using use-site variance in Kotlin, there are limitations on the methods that can be called on a projected type. If you are using a projected type, you may not be able to call certain methods that require the type parameter to be used as an argument (“in” position) :
val list: MutableList<out Number> = ..
list.add(42) // Error: Out-projected type 'MutableList<out Number>' prohibits the use of 'fun add(element: E): Boolean'Here, list is declared as a MutableList<out Number>, which is an out-projected type. The out projection restricts the type parameter Number to only be used in the “out” position, meaning it can only be used as a return type or read from. You cannot call the add method because it requires the type parameter to be used as an argument (“in” position).
If you need to call methods that are prohibited by the projection, you should use a regular type instead of a projection. In this case, you can use
MutableList<Number>instead ofMutableList<out Number>. By using the regular type, you can access all the methods available for that type.
Regarding the concept of using the in modifier, it indicates that in a particular location, the corresponding value acts as a consumer, and the type parameter can be substituted with any of its supertypes. This is similar to the contravariant position in Java’s bounded wildcards.
For example, the copyData function can be rewritten using an in-projection:
fun <T> copyData(source: MutableList<T>, destination: MutableList<in T>) {
for (item in source) {
destination.add(item)
}
}In this version, the destination parameter is projected with the in modifier, indicating that it can consume elements of type T or any of its supertypes. This allows you to copy elements from the source list to a destination list with a broader type.
It’s important to note that use-site variance declarations in Kotlin correspond directly to Java’s bounded wildcards.
MutableList<out T>in Kotlin is equivalent toMutableList<? extends T>in Java, while the in-projectedMutableList<in T>corresponds to Java’sMutableList<? super T>.
Use-site projections in Kotlin can help widen the range of acceptable types and provide more flexibility when working with generic types, without the need for separate covariant or contravariant interfaces.
Star projection: using * instead of a type argument
In Kotlin, star projection is a syntax that allows you to indicate that you have no information about a generic argument. It is represented by the asterisk (*) symbol. Let’s explore the semantics of star projections in more detail.
When you use star projection, such as List<*>, it means you have a list of elements of an unknown type. It’s important to note that MutableList<*> is not the same as MutableList<Any?>. The former represents a list that contains elements of a specific type, but you don’t know what type it is. You can’t put any values into the list because it may violate the expectations of the calling code. However, you can retrieve elements from the list because you know they will match the type Any?, which is the supertype of all Kotlin types.
Here’s an example to illustrate this:
val list: MutableList<Any?> = mutableListOf('a', 1, "qwe")
val chars = mutableListOf('a', 'b', 'c')
val unknownElements: MutableList<*> = if (Random().nextBoolean()) list else chars
unknownElements.add(42) // Error: Adding elements to a MutableList<*> is not allowed
println(unknownElements.first()) // You can retrieve elements from unknownElementsIn this example, unknownElements can be either list or chars based on a random condition. You can’t add any values to unknownElements because its type is unknown, but you can retrieve elements from it using the first() function.
unknownElements.add(42)
// Error: Out-projected type 'MutableList<*>' prohibits//the use of 'fun add(element: E): Boolean'The term “out-projected type” refers to the fact that MutableList<*> is projected to act as MutableList<out Any?>. It means you can safely get elements of type Any? from the list but cannot put elements into it.
For contravariant type parameters, like Consumer<in T>, a star projection is equivalent to <in Nothing>. In this case, you can’t call any methods that have T in the signature on a star projection because you don’t know exactly what it can consume. This is similar to Java’s wildcards (MyType<?> in Java corresponds to MyType<*> in Kotlin).
You can use star projections when the specific information about type arguments is not important. For example, if you only need to read the data from a list or use methods that produce values without caring about their specific types. Here’s an example of a function that takes List<*> as a parameter:
fun printFirst(list: List<*>) {
if (list.isNotEmpty()) {
println(list.first())
}
}
printFirst(listOf("softAai", "Apps")) // Output: softAaiIn this case, the printFirst function only reads the first element of the list and doesn’t care about its specific type. Alternatively, you can introduce a generic type parameter if you need more control over the type:
fun <T> printFirst(list: List<T>) {
if (list.isNotEmpty()) {
println(list.first())
}
}The syntax with star projection is more concise, but it works only when you don’t need to access the exact value of the generic type parameter.
Now let’s consider an example using a type with a star projection and common traps that you may encounter. Suppose you want to validate user input using an interface called FieldValidator. It has a type parameter declared as contravariant (in T). You also have two validators for String and Int inputs.
interface FieldValidator<in T> {
fun validate(input: T): Boolean
}
object DefaultStringValidator : FieldValidator<String> {
override fun validate(input: String) = input.isNotEmpty()
}
object DefaultIntValidator : FieldValidator<Int> {
override fun validate(input: Int) = input >= 0
}If you want to store all validators in the same container and retrieve the right validator based on the input type, you might try using a map. However, using FieldValidator<*> as the value type in the map can lead to difficulties. You won’t be able to validate a string with a validator of type FieldValidator<*> because the compiler doesn’t know the specific type of the validator.
val validators = mutableMapOf<KClass<*>, FieldValidator<*>>()
validators[String::class] = DefaultStringValidator
validators[Int::class] = DefaultIntValidator
validators[String::class]!!.validate("") // Error: Cannot call validate() on FieldValidator<*>In this case, you will encounter a similar error as before, indicating that it’s unsafe to call a method with the type parameter on a star projection. One way to work around this is by explicitly casting the validator to the desired type, but this is not recommended as it is not type-safe.
val stringValidator = validators[String::class] as FieldValidator<String>
println(stringValidator.validate("")) // Output: falseThis code compiles, but it’s not safe because the cast is unchecked and may fail at runtime if the generic type information is erased.
A safer approach is to encapsulate the access to the map and provide type-safe methods for registration and retrieval. This ensures that only the correct validators can be registered and retrieved. Here’s an example using an object called Validators:
object Validators {
private val validators = mutableMapOf<KClass<*>, FieldValidator<*>>()
fun <T : Any> registerValidator(kClass: KClass<T>, fieldValidator: FieldValidator<T>) {
validators[kClass] = fieldValidator
}
@Suppress("UNCHECKED_CAST")
operator fun <T : Any> get(kClass: KClass<T>): FieldValidator<T> =
validators[kClass] as? FieldValidator<T>
?: throw IllegalArgumentException("No validator for ${kClass.simpleName}")
}
Validators.registerValidator(String::class, DefaultStringValidator)
Validators.registerValidator(Int::class, DefaultIntValidator)
println(Validators[String::class].validate("softAai Apps")) // Output: true
println(Validators[Int::class].validate(42)) // Output: trueIn this example, the Validators object controls all access to the map, ensuring that only correct validators can be registered and retrieved. The code emits a warning about the unchecked cast, but the guarantees provided by the Validators object make sure that no incorrect use can occur.
This pattern of encapsulating unsafe code in a separate place helps prevent misuse and makes the usage of a container safe. It’s worth noting that this pattern is not specific to Kotlin and can be applied in Java as well.
Conclusion
Kotlin generics and variance are powerful tools that enhance type safety and code reusability. Understanding these concepts enables developers to write generic code that can be adapted to different types and relationships between them. By mastering generics and variance, you can build more flexible and robust applications.
In this blog post, we covered the basics of Kotlin generics, explained variance with examples, explored variance annotations, wildcards, type projections, and discussed additional topics such as reified type parameters and generic constraints. With this knowledge, you are well-equipped to utilize generics effectively in your Kotlin projects.